




Elastic Stack介紹
近幾年,互聯網生成數據的速度不斷遞增,爲了便於用戶能夠更快更精準的找到想要的內容,站內搜索或應用內搜索成了不可缺少了的功能之一。同時,企業積累的數據也再不斷遞增,對海量數據分析處理、可視化的需求也越來越高。
在這個領域裏,開源項目ElasticSearch贏得了市場的關注,比如,去年Elastic公司與阿里雲達成合作伙伴關係提供阿里雲 Elasticsearch 的雲服務、今年10月Elastic公司上市,今年11月舉行了Elastic 中國開發者大會、目前各大雲廠商幾乎都提供基於Elasticsearch的雲搜索服務,等等這些事件,都反映了Elasticsearch在企業的應用越來越普遍和重要。
先來看看官網的介紹,ok,核心關鍵字:搜索、分析。
Elasticsearch is a distributed, RESTful search and analytics engine
capable of solving a growing number of use cases. As the heart of the
Elastic Stack, it centrally stores your data so you can discover the
expected and uncover the unexpected.
Elasticsearch 是一個分佈式的 RESTful 風格的搜索和數據分析引擎,能夠解決不斷涌現出的各種用例。作爲 Elastic
Stack 的核心,它集中存儲您的數據,幫助您發現意料之中以及意料之外的情況。
產品優勢:速度快、可擴展性、彈性、靈活性。
在某些應用場景中,不僅會使用Elasticsearch,還會使用Elastic旗下的其他產品,比如Kibana、Logstash等,常見的ELK指的就是Elasticsearch、Logstash、Kibana這三款產品,Elastic Stack指的是Elastic旗下的所有開源產品。
應用場景:(圖片截於Elastic官網)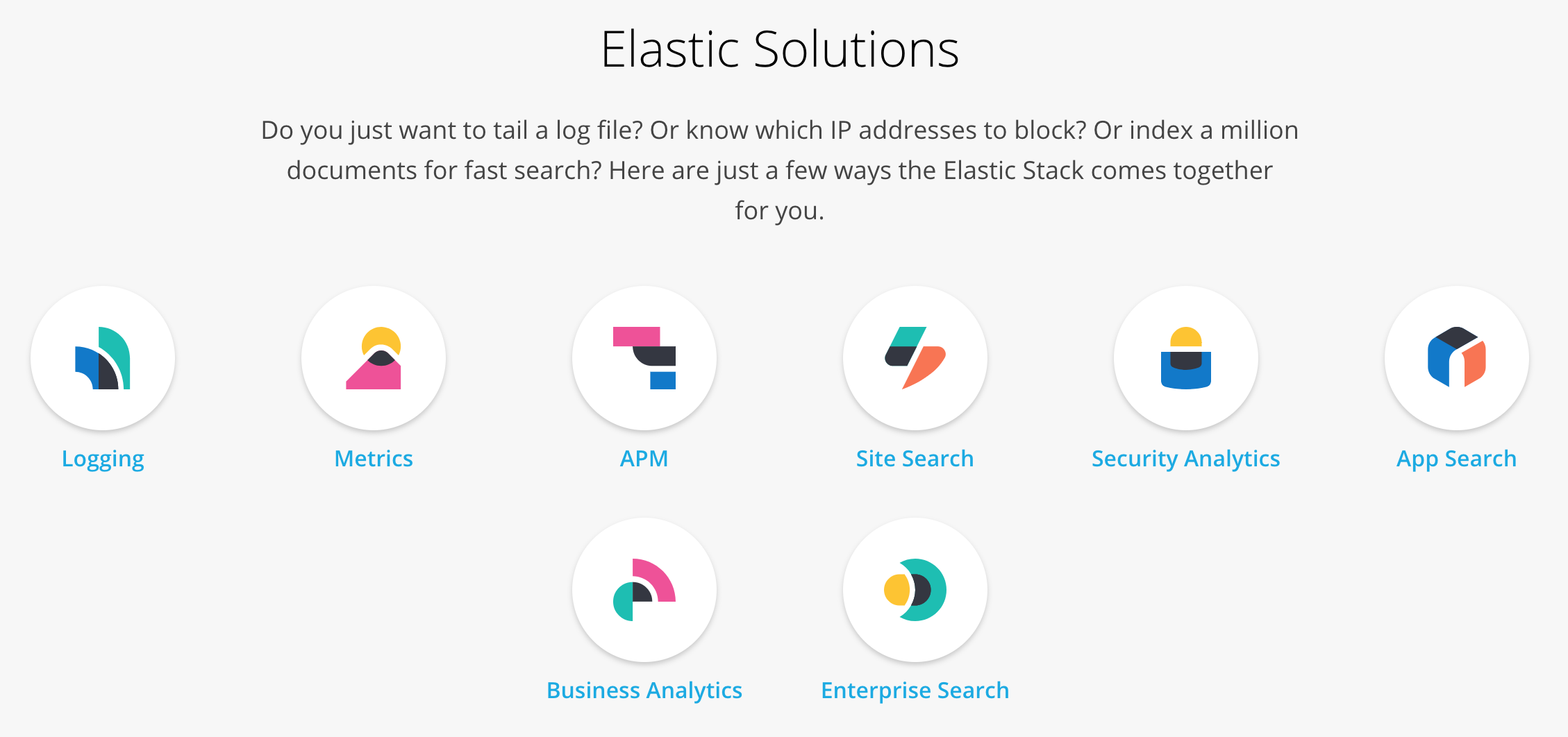
場景實戰
接下來,我們來實戰一個應用場景。
場景:一個後端應用部署在一臺雲服務器中,後端應用會以文件形式記錄日誌。需求爲:收集日誌內容,對每行日誌解析,得到結構化數據,便於搜索、處理與可視化。
方案:使用Filebeat轉發日誌到Logstash,後者解析或轉換數據,然後轉發到Elasticsearch儲存,接着數據就任君處理了,這裏我們把日誌數據根據某些需求進行可視化,可視化的活就交給Kibana完成。(另種方案也可:通過Filebeat將日誌數據直接轉發到Elasticsearch,由Elasticsearch Ingest node負責數據的數據處理)
所需軟件
本案例使用的產品版本如下:
系統:CentOS,這裏分開部署了,也可以放在一起。
1、Kibana_v6.2.3 (IP: 192.168.0.26)
2、Elasticsearch_v6.2.3 (IP: 192.168.0.26)
3、Filebeat_v6.2.3 (IP: 192.168.0.25)
4、Logstash_v6.2.3 (IP: 192.168.0.25)
日誌內容
假設一行日誌內容如下:(日誌文件放在/root/logs目錄下)
其中一行日誌內容如下:
2018-11-08 20:46:25,949|https-jsse-nio-10.44.97.19-8979-exec-11|INFO|CompatibleClusterServiceImpl.getClusterResizeStatus.resizeStatus=|com.huawei.hwclouds.rds.trove.api.service.impl.CompatibleClusterServiceImpl.getResizeStatus(CompatibleClusterServiceImpl.java:775)
一行日誌中可得到5個字段,以“|”分割
2018-11-08 20:46:25,949| #時間
https-jsse-nio-10.44.97.19-8979-exec-11| # 線程名稱
INFO| # 日誌級別
CompatibleClusterServiceImpl.getClusterResizeStatus.resizeStatus=| # 日誌內容
trove.api.service.impl.CompatibleClusterServiceImpl.getResizeStatus(CompatibleClusterServiceImpl.java:775) # 類名文件目錄如下:(Elasticsearch和Kibana在另一臺服務器,且已啓動)
Logstash配置
logs目錄存放需要收集的應用日誌,logstash.conf 爲Logstash準備的配置文件。
logstash.conf內容如下:
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{GREEDYDATA:Timestamp}\|%{GREEDYDATA:ThreadName}\|%{WORD:LogLevel}\|%{GREEDYDATA:TextInformation}\|%{GREEDYDATA:ClassName}" }
}
date {
match => [ "Timestamp", "yyyy-MM-dd HH:mm:ss,SSS" ]
}
}
output {
elasticsearch {
hosts => "192.168.0.26:9200"
manage_template => false
index => "java_log"
}
}
接下來啓動Logstash(啓動成功,監聽5044端口,等待日誌數據傳入):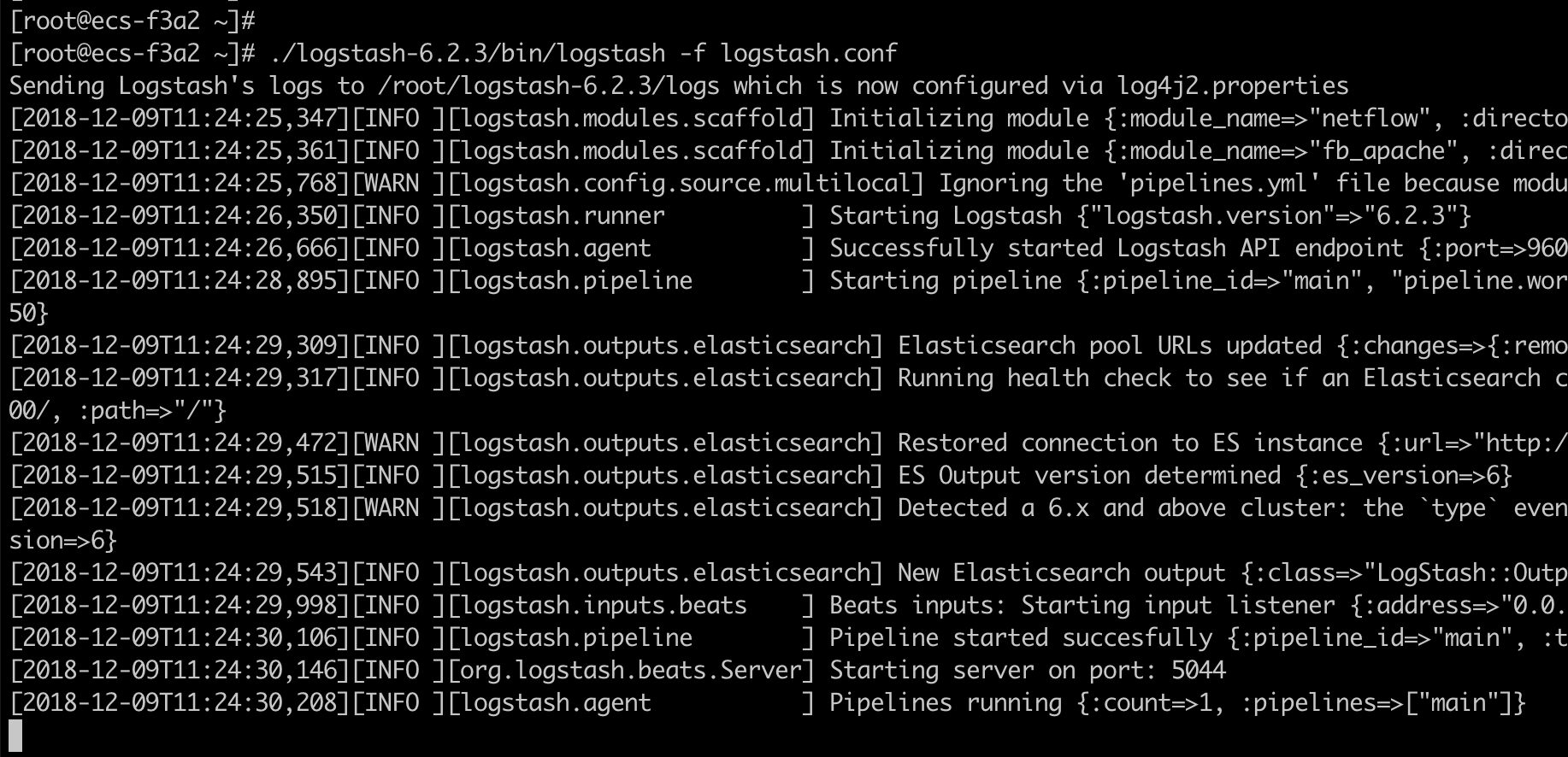
Filebeat配置
接下來看下Filebeat的配置文件:
filebeat.prospectors:
- type: log
enabled: true
# 配置日誌目錄的路徑或者日誌文件的路徑
paths:
- /root/logs/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
setup.kibana:
host: "192.168.0.26:5601"
# 配置output爲logstash
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
啓動Filebeat:(當日志文件有更新時,會被Filebeat監聽到,被轉發出去。)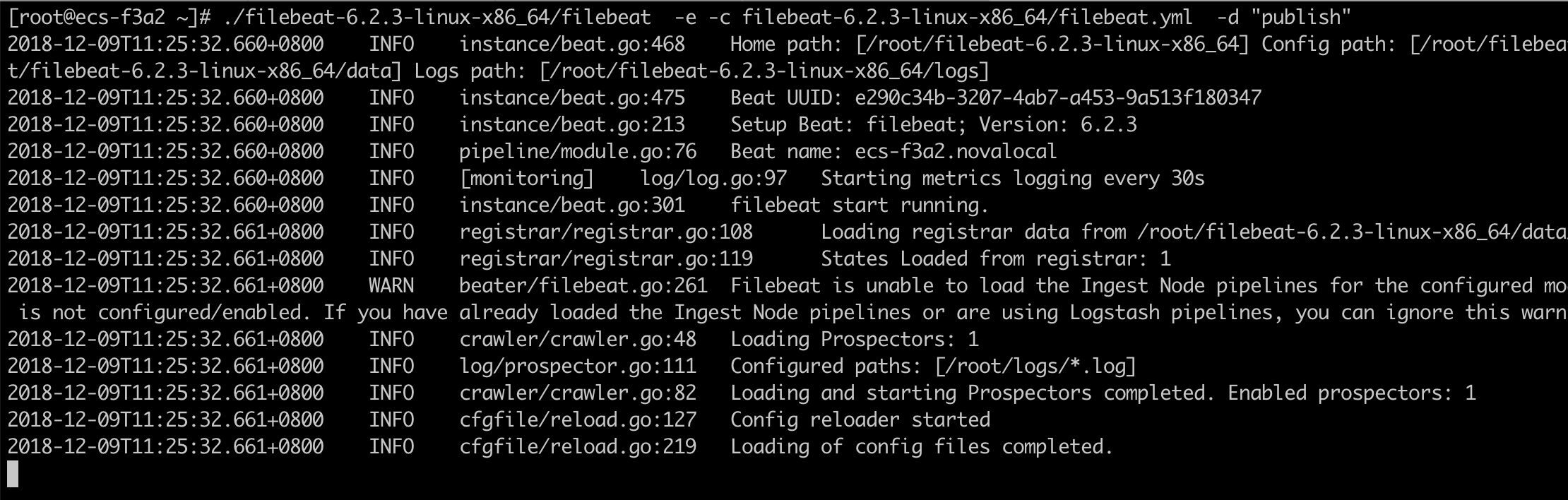
日誌查詢和可視化
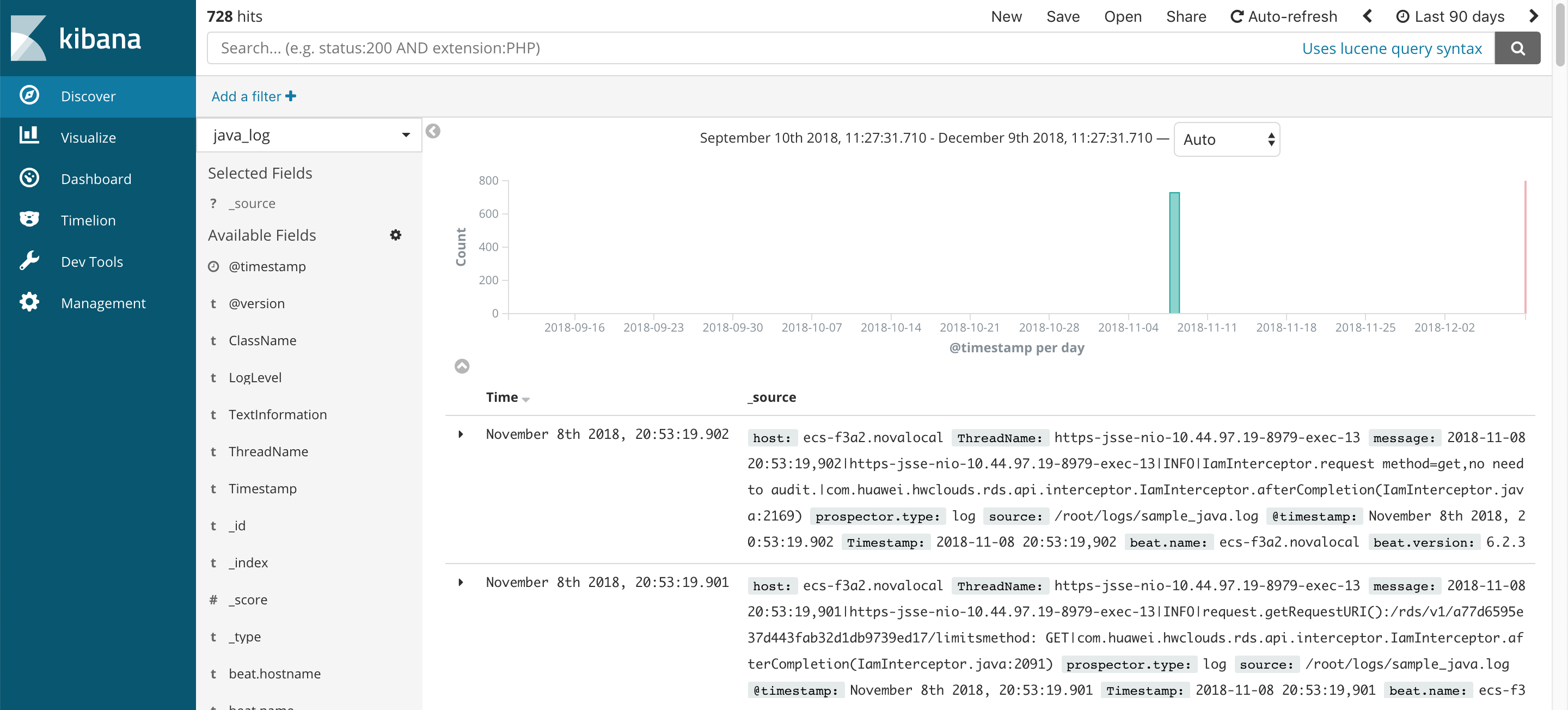
最後來看看Kibana,進行日誌的可視化。在Kibana創建好index pattern,這裏命名爲:java_log。在Discover頁面中對日誌數據進行查詢。
在Visualize中創建可視化圖形。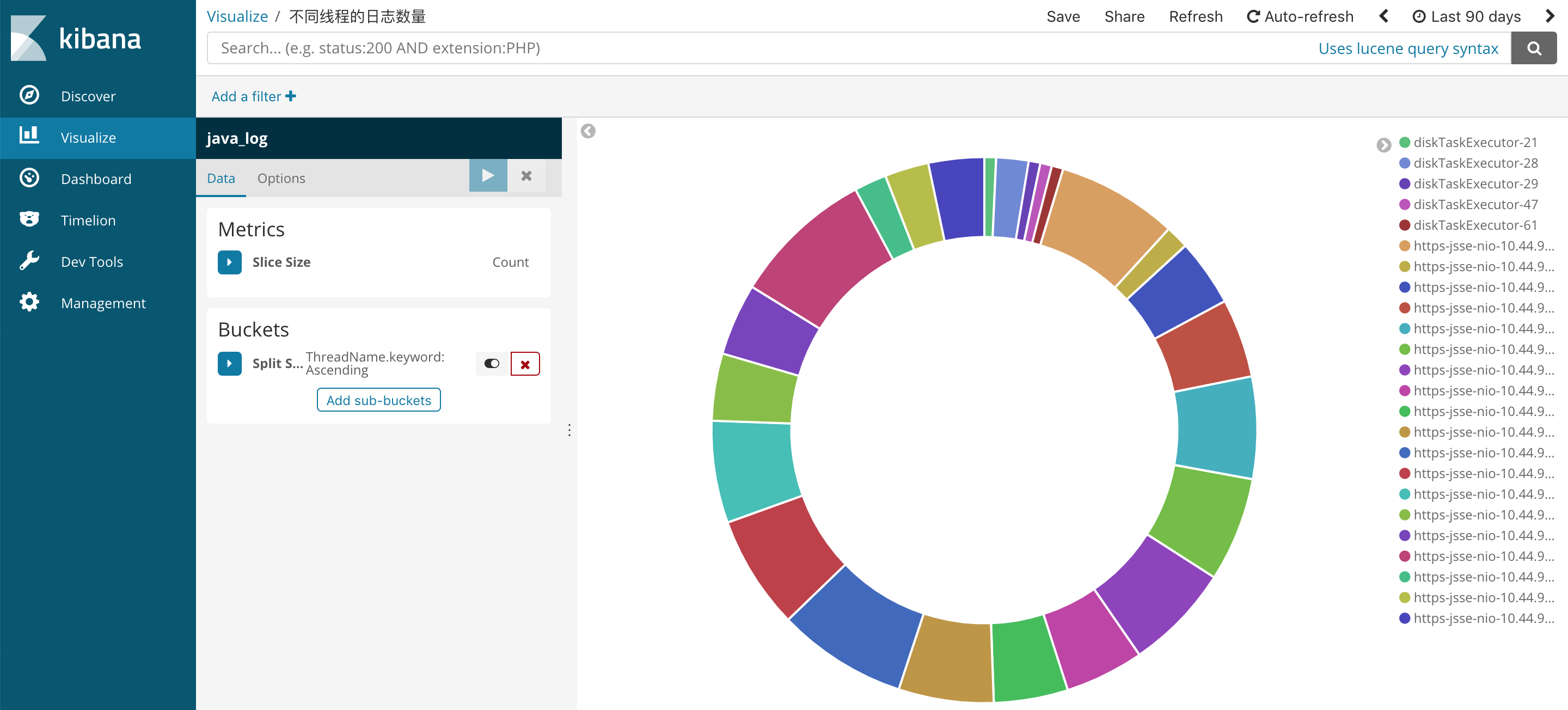
在Dashboard中組合我們的圖形。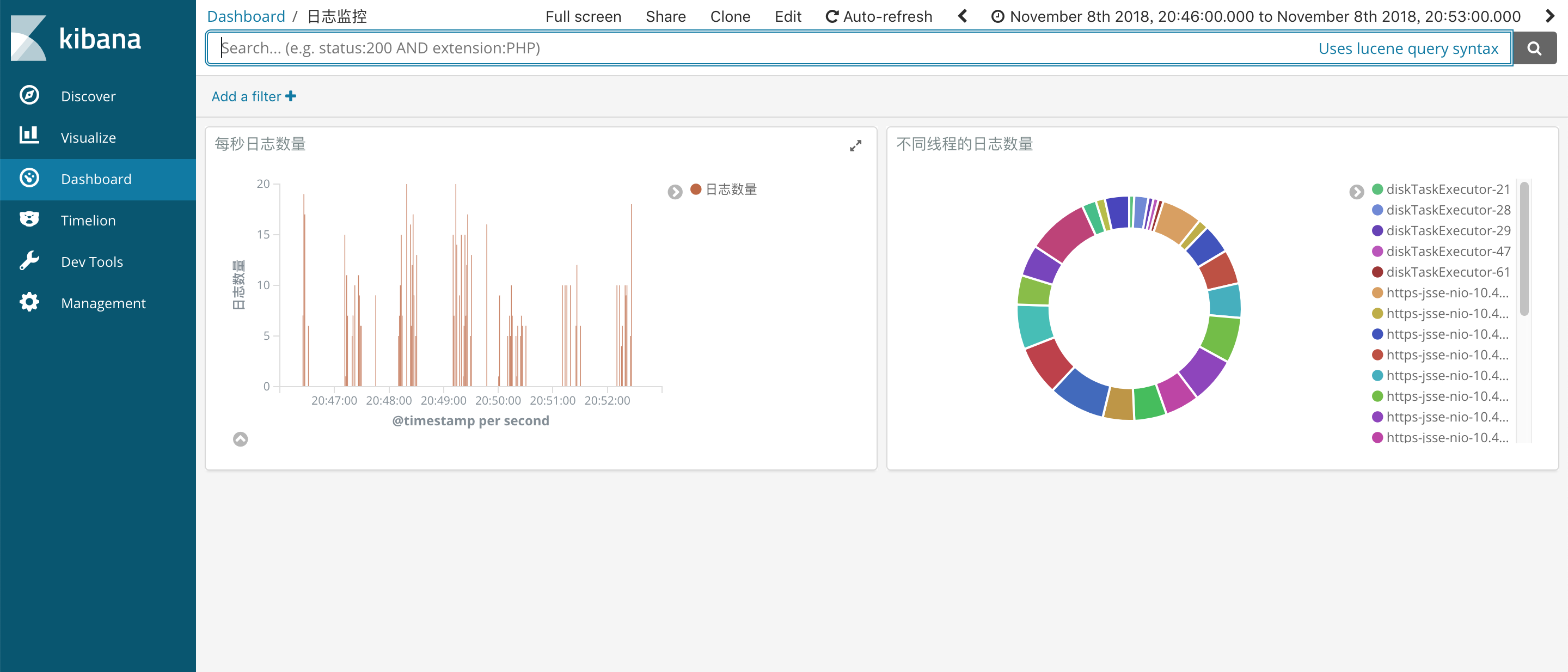
到此,就完成一個簡單的日誌數據的收集、分析、可視化。
Elastic Stack還有很多強大的功能,後面我們來一個應用內搜索案例。
參考資料
-
https://www.elastic.co/cn/blog/alibaba-cloud-to-offer-elasticsearch-kibana-and-x-pack-in-china 阿里雲與Elastic公司合作
-
https://www.elastic.co/guide/en/beats/libbeat/6.2/getting-started.html beat入門
- https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html grok插件

公衆號:碼農阿呆 (歡迎關注和交流)