




數據庫與緩存雙寫問題
計算機領域任何一個問題都可以通過增加一個抽象“層”來解決。
業務中爲了減少熱點數據不必要的db查詢,往往會增加一層緩存來解決I/O性能。可是I/O多了一層也就多了一層的更新維護與容錯保障,當修改db中某些數據時,往往會面臨緩存更新的問題,在這裏簡單介紹 數據庫與緩存雙寫問題以及在業務場景如何使用雙寫策略。
緩存更新時機
緩存在以下情況下需要更新:
- 不存在緩存,回源至db後添加緩存
- 緩存超時,重複上個步驟
- 修改db,更新緩存
緩存更新策略
-
若不存在緩存或者緩存超時:
- 查詢db
- 設置緩存
-
若緩存存在,且需要更新db,則有多種緩存更新策略:
- 先更新db,然後更新緩存
- 先刪除緩存,然後更新db
- 先更新db,在刪除緩存
本節主要討論更新db時如何更新緩存的問題,且暫時不考慮緩存操作失敗的情況(如網絡原因、redis服務不可用等)。
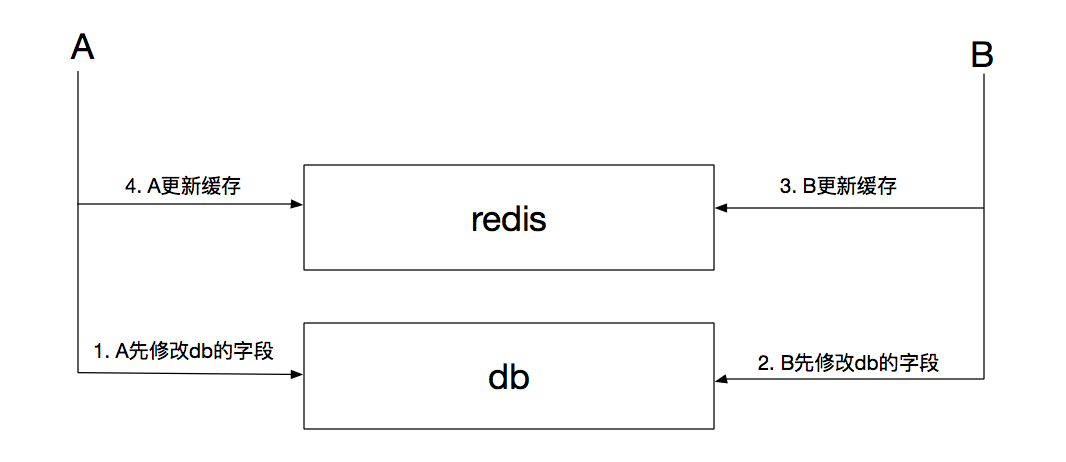
如果業務場景中不會出現修改相同數據字段競爭的問題,那麼這三種更新策略毫無疑問都可以使用。如果出現緩存競爭態的情況,那麼第一種策略是最先排除的:
上圖所示,如果A、B先後修改db,會出現最終緩存與db不一致的現象,導致隨後至緩存超時或下次更新的時間段內使用髒數據的現象。
而且業務方需要考慮的是,是否每次更新db,都需要立即刷新緩存。如果在“寫頻繁,而讀頻率遠小於寫的情況下,頻繁的刷新緩存是否有必要?”
){kind=link}
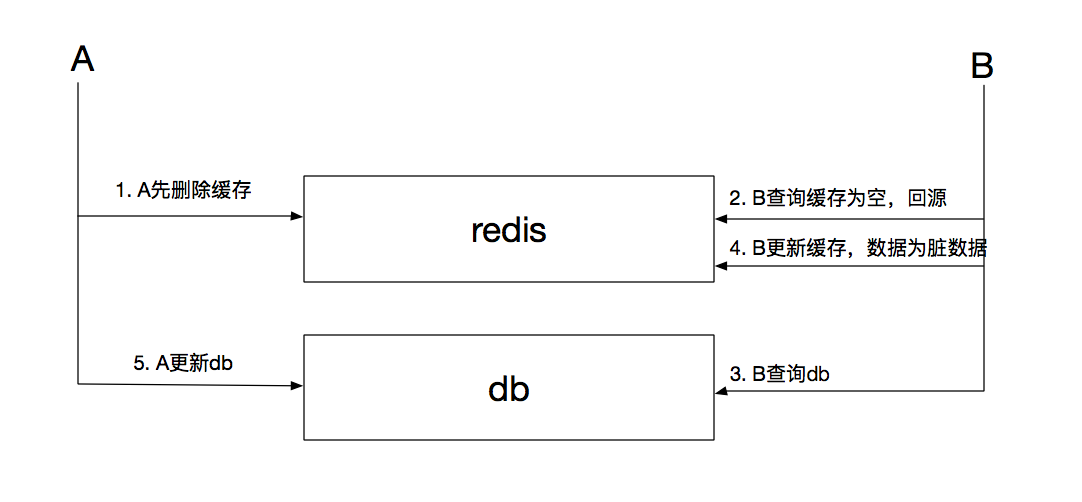
第二種策略,先刪除緩存再更新數據庫旨在犧牲性能下儘可能降低使用髒緩存的情況,可是此種情況下仍有可能出現髒緩存的情況:
如上圖,A先刪除緩存,同時開始更新db;與此同時B查詢緩存爲空,進而查詢db,由於db的讀性能高於寫且數據庫隔離級別默認爲提交讀,因此B查詢db的數據往往爲舊數據,此後B查詢完畢更新緩存,導致緩存在超時時間或者下次修改db的範圍內爲髒數據。
如果db底層做了讀寫分離的情況下,這種現象更容易出現,B查詢db是讀庫,而A修改主庫後需要一定時間的同步才能保障從庫的數據最新,因此在此種情況下,緩存肯定仍是髒數據。
){kind=link}
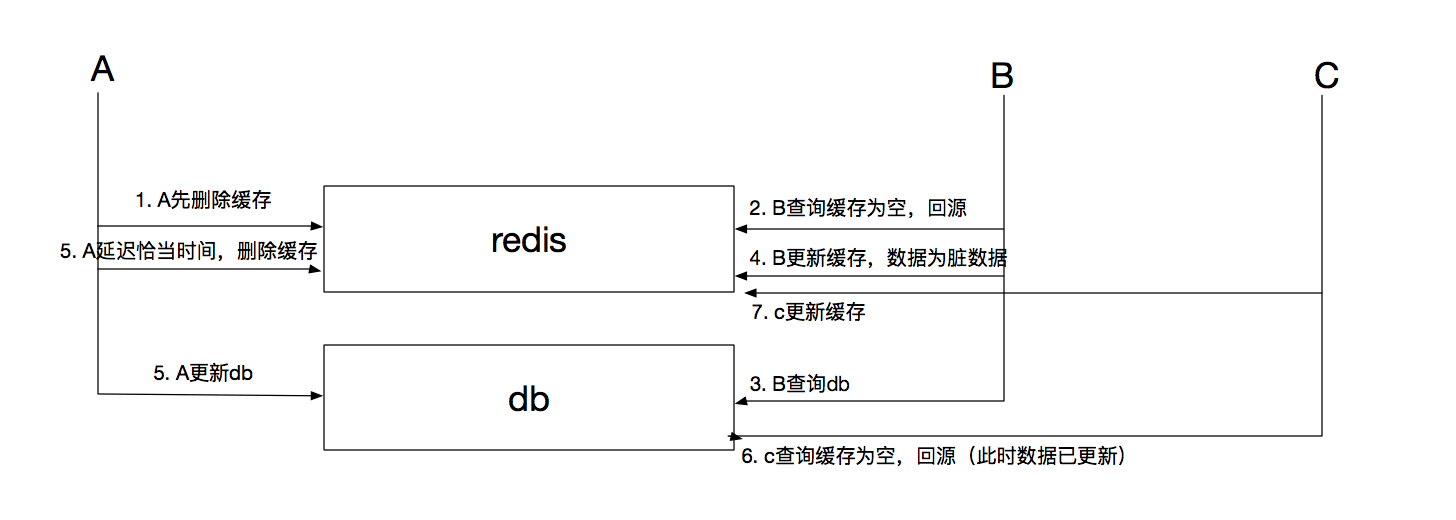
爲了避免這種情況,A可以在更新db後延時一定間隔(往往是查詢db時間+設置緩存的時間)刪除緩存,儘量縮短髒緩存的時段,新的請求回源db並設置新的緩存數據。如下圖所示。
){kind=link}
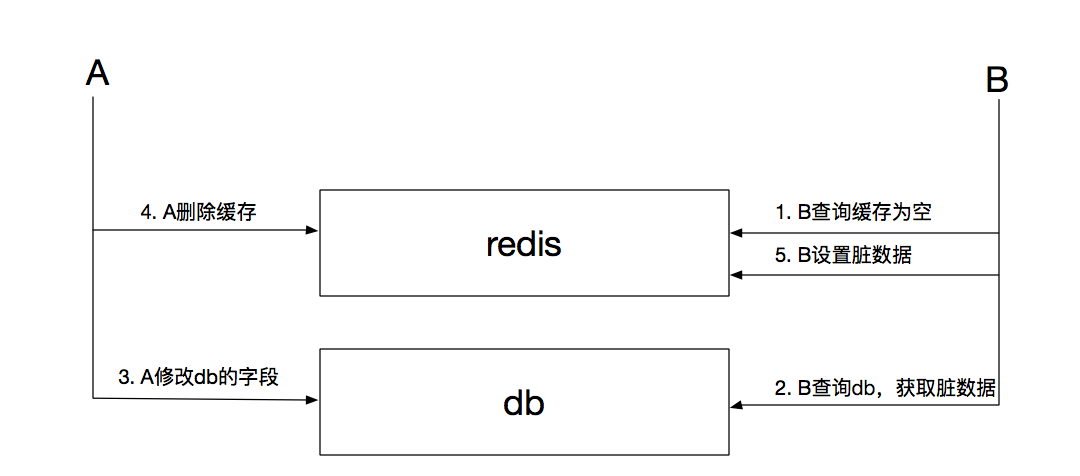
第三種策略先更新數據庫再刪除緩存,此種策略較爲安全,幾乎不會出現髒緩存的情況,就算出現也是會在極不合理的情況下導致髒緩存:
如上圖,緩存出現髒數據的前提是第2步驟耗時大於第3、4步驟,即讀耗時大於寫耗時,這幾乎不可能發生。就算髮生,也可以通過A再次延遲刪除緩存(兩次刪除)解決。
){kind=link}
緩存操作問題
在上一節中提到的所有緩存更新策略都是在暫時不考慮緩存操作失敗的情況(如網絡原因、redis服務不可用等)前提下討論的,如果緩存操作失敗,則必須通過業務代碼重試、消息隊列或者設置緩存超時解決。
業務代碼重試,設置合理的重試次數與間隔,如果超時後緩存仍然無法操作則需要等待緩存超時或者人爲介入;
消息隊列則在緩存操作失敗後投遞對應消息,在非業務代碼中進行重試;
緩存超時則是兜底方案,這是允許最長的緩存不一致的時間。
分佈式事務
比較遺憾的是,在node領域還沒有類似JAVA的JTA規範及其實現,JTA規範中的核心“事務管理器TM”大都由容器來實現,如常見的jboss和websphere;TM接收業務層的事務請求,同時協同參與事務的各個資源管理器RM如dbms、mq等,實現分佈式事務的提交與回滾;同時也提供分佈式事務在不同自治系統的傳遞。
分佈式事務的集中解決方案有如下幾種:
1. 兩階段提交
2. 三階段提交
3. 異步確保
4. TCC在JAVA和其他生態已經證明了,兩階段提交的低效以及無法抗住高併發且存在單點的問題;三階段提交雖然解決了兩階段的單點和減少協調者阻塞等待參與者的問題,但仍存在數據不一致的情況,因此這兩種理論上的模型其實並不符合實際業務中的場景,在工程領域需要追求的是最優化,可見理論與現實仍然有不少差距。
那麼在node場景中,處理分佈式事務的方式也就只剩下兩種工程上的解決方案。
node中使用異步確保模型可以使用相比較簡單的基於消息隊列的異步確保模型(也可基於本地數據庫表)。將分佈式長事務切分爲多個本地事務,通過保障本地事務的可靠性實現分佈式長事務的最終提交。如果參與分佈式事務的某個本地事務執行出錯進行回滾,則通過消息隊列實現業務主動方的補償,實現最終的數據一致性。
如下圖:
TCC模型相比較異步確保而言則比較重,需要開發一個TCC的TM協調各個服務參與方,同時對參與事務的各個從服務侵入性比較大,必須提供try、confirm和cancel三個接口。其中try接口預留相關資源,並確保數據一致性,confirm接口和cancel接口保證冪等性,執行或回滾try階段預留的資源。其中,在業務中主動調用所有參與分佈式事務的從服務的try接口,並彙報給TM執行情況,由TM根據try階段的結果完成後續的執行或回滾操作,同時記錄分佈式事務狀態傳遞以及各個從服務的執行階段等信息,便於追蹤。
因此用node實現分佈式事務時,在沒有自研TCC中間件的前提下,可根據業務特性自行擴展異步確保型方案。