




之前一直講存儲層,大家都知道計算機三層架構分爲: cpu / 內存 / 硬盤。
前幾篇都是在講存儲層數據治理,講如何控制硬盤裏的數據量。集羣不要失控啦,不要被新增業務線數據撐爆啦,要分清楚哪些是冷數據,哪些是小文件啦。總之都是圍繞着“硬盤”。
今天就來侃侃 hadoop 集羣的 cpu & 內存管理。
PS: 本文的tool和可視化圖表都是由
同學在hulu實習期間開發的,感謝她出色&辛苦的工作。
Agenda
history 談談yarn的歷史,由來
yarn相同的領域,還有哪些產品
yarn的設計,多租戶,隊列/標籤
real world裏,yarn的問題
數據驅動的yarn管理,資源治理
分析規律,反哺線上,做出改變
總結
1. 談談yarn的歷史,由來
當下hadoop穩定在了2.x.x版本,3.x版本也基本production stable了,雖然敢用的公司很少。(2.x 也很難升級到3.x, no-downtime upgrade又是另一個高大上的話題了,在hadoop 2.x後,都是用 YARN (Apache Hadoop YARN )來管理集羣的計算資源。
隨着互聯網的發展,互聯網公司的業務越來越複雜,早在10年錢,一個普通的小網站有個50臺機器,能有20個web服務器20個數據庫,公司內有10來個應用系統,也就差不多了。但是像google,bat這種巨無霸,很早就面臨了大規模集羣的管理問題,且問題越來越大。看看現在的bat,有多少業務線,內部有多少it系統在不停歇的運轉。倘若每個應用的開發者,都自己維護自己的物理機,那這些機器出問題後,每個開發者的維護成本簡直無法估量。即使有專業的運維團隊,把每個應用部署在哪臺機器,哪臺機器壞了,把應用遷移到另外的機器,這些問題都是很棘手的。慢慢的爲了自動化,讓運維人更自由,業界也就產生了“分佈式操作系統”。單臺操作系統管理本機的cpu,內存。“分佈式操作系統”就管理整個集羣成千上外臺機器的cpu,內存,甚至網絡。你的應用被提交到“分佈式操作系統”後,一定會跑成功,即使運行你應用的節點發生故障,“分佈式操作系統”也會自動在另外的節點,重試。
這一段我稍待講講,不說太多,因爲不是hadoop系列的point,我的point是怎麼能更好的運維好hadoop/yarn。因此懂yarn的人自然懂,不懂yarn的朋友,可以順着看看第二章我介紹的產品,讀一讀“分佈式操作系統”的業界產品的wiki,或者我推薦的論文。
2. yarn相同的領域,還有哪些產品
資源管理領域:
google先有了borg(論文) ,後又開源了 Kubernetes.(Wiki)
hadoop繫有了yarn
twitter開源了Mesos
可謂百花齊放。
因爲hadoop的特點,以及歷史原因,hadoop集羣的資源管控,發展到了yarn這套系統,可以說yarn是專門跑hadoop系應用的,即 mapreduce/spark等等計算作業。有人說yarn上面能否跑一些別的項目應用啊? 答案當然是可以。
用戶需要自己編寫一個on yarn的程序,寫自己的application-master (Hadoop: Writing YARN Applications ),自己寫資源申請模塊等等。
我這裏也找了一些開源屆的人嘗試寫的on-yarn應用:
4.Introducing Hoya - HBase on YARN - Hortonworks
但是我相信,在實際的應用場景中,大多數規模以上公司,hadoop集羣光跑mapreduce/spark的job,集羣資源就基本耗盡了,所以other on-yarn application,也不在本文的討論範疇內。這一篇只討論競爭激烈的真正跑滿了hadoop application的 hadoop yarn cluster。
3. yarn的設計,多租戶,並行app,隊列/標籤
3.1 yarn設計的最大初衷,是多租戶,並行app。
在早版本hadoop 0.x.x時期,hadoop job是提交給jobtracker的,mapreduce作業的mapper和reducer任務會跑在tasktracker上。整個集羣其實是一個first-in-first-out的調度隊列。每個app都在排隊跑,當一個app佔不滿集羣的資源,整個集羣的空閒計算資源就浪費在那裏了。
到了yarn時期,hadoop終於可以允許多個app同時跑,按自己的需求共享集羣資源。這使得集羣的資源利用率得到了大幅度的提升。這也解決了大數據底層的大規模集羣空置問題,可謂業界向大數據落地的一次大前進。
下圖列出了yarn的一些主要的特點:
 yarn 優點
yarn 優點
3.2 隊列/標籤
3.2.1 隊列
在當下穩定的hadoop版本下,資源的調度,都是基於隊列的。
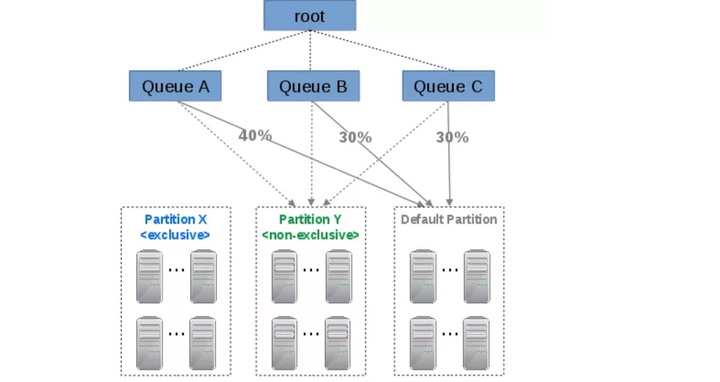 隊列-標籤的映射關係
隊列-標籤的映射關係
在一個公司裏,不同的team,可以按需求把作業提交到不同的隊列裏。 這就好比,銀行的門店,可以辦理不同的業務。不同的業務會分散不同的窗口(queue)。根據業務強度,銀行會給不同的窗口分配不同的人(機器),有的窗口分配能力強的人(多cpu),甚至開多個窗口(子隊列),有的子隊列只服務“軍人”/“老人” (sub-queue)。有的窗口分配普通員工。
yarn的主流調度器 Hadoop: Fair Scheduler & Hadoop: Capacity Scheduler 都是基於隊列設計的。對這一塊沒了解的朋友,可以點擊上面scheduler鏈接,讀讀官網的原版wiki.
CapacityScheduler

FairScheduler

本文的重點第5部分,就會提到基於queue history data 分析。
本文不對這兩種調度器的對比做過多的評價,這裏提供一些講調度器的文章:
3.2.2 標籤
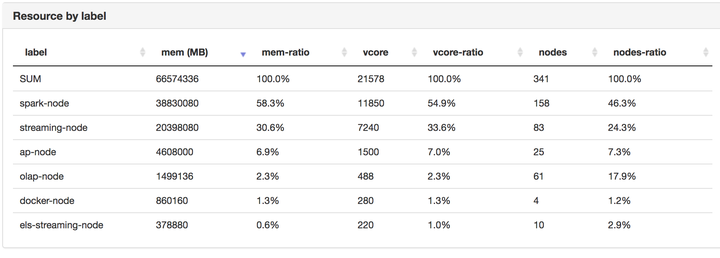
Node label (YARN Node Labels )是一個爲了給相同特點的集羣機器分組的解決方案,說直白點,就是異構機器分組。這一波機器A,用來跑 map-reduce,另一波機器B,用來跑spark. 還有一部分機器C,用來跑ai/machine-learning job.
爲什麼會產生這種需求呢?
因爲hadoop技術棧已經產生了很多年了,在公司集羣中,有的機器是3年5年前買的,有的是近1年買的。那麼隨着時間的推移,集羣中的機器配置必然會是異構性。一般來講,都會用老的機器跑一些“實時性不是很重要”的batch job,而讓一些新一些的機器,跑一些需要快速處理的"spark/ streaming" 甚至olap的計算任務。而這種分組,就是使用yarn node label功能做到的。
這裏有幾篇講nodelabel的很好的文章:
1.https://www.slideshare.net/Hadoop_Summit/node-labels-in-yarn-49792443
2.YARN Node Labels: Label-based scheduling and resource isolation - Hadoop Dev
3.Node labels configuration on Yarn
總之,hadoop的admin可以把一個或多個label關聯到queue上。一個hadoop application只能使用一個queue下面的一種label.
例子:
提交mr作業到label X:
提交mr作業到Xlabel: yarn jar /usr/iop/<iopversion>/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount -D mapreduce.map.node-label-expression="X" /tmp/source /tmp/result
提交spark作業到label Y:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 3g --executor-memory 2g --conf spark.yarn.am.nodeLabelExpression=Y --conf spark.yarn.executor.nodeLabelExpression=Y jars/spark-examples.jar 10
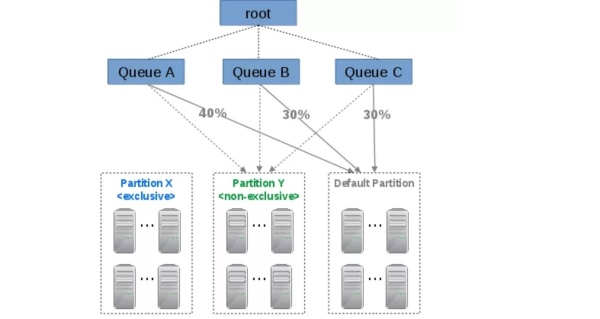 yarn queue label
yarn queue label
Tip! YARN node-labels 功能在Apache Hadoop 2.6被開發出來,但並沒有被merge到官方版本中,只能通過打patch的方式使用. 是有很多bug的,官方推薦 hadoop 2.8.x 之後在使用,fix了很多bug,而事實上在Apache Hadoop 2.7.3 版本的官方主業裏,nodelabel功能被正式介紹出來。
我司使用的是CDH-5.7.3,即cloudera公司發行的hadoop版本,底下是Apache hadoop 2.6.0. 對hadoop部署版本感興趣的朋友,請看《大數據SRE的總結(1)--部署》。 我們就踩坑了, cloudera 把node-label的feature打入了,但很多bug並沒有fix。我在下一小節會着重講。
最後,yarn發展到了,多queue 多租戶,以及成熟的label管理。已經到了一個相對完備的功能階段。下面,我講講我自己在運維yarn的工作時碰到的各種問題。
4.real world裏,yarn的問題
4.1 用戶問題
YARN resources are always complained insufficiently by big-data users.
在我們公司,big data infrastructure team,是有一個內網的聊天channel的。hadoop user總是會來這裏抱怨,抱怨他們的job今天跑的慢了,pending太久了,爲什麼還拿不到資源等等。
我們分析了產生問題的原因Reason (R) 。總結出來有一下幾種:
R1.資源分配問題。
給某些隊列劃分了過多的資源,導致某些隊列的job卡住很久,隊列資源使用率達到100%時,另一個隊列的資源使用還不到50%. 比如下圖,streaming隊列明顯快滿了,olap隊列還使用了不到1/4.
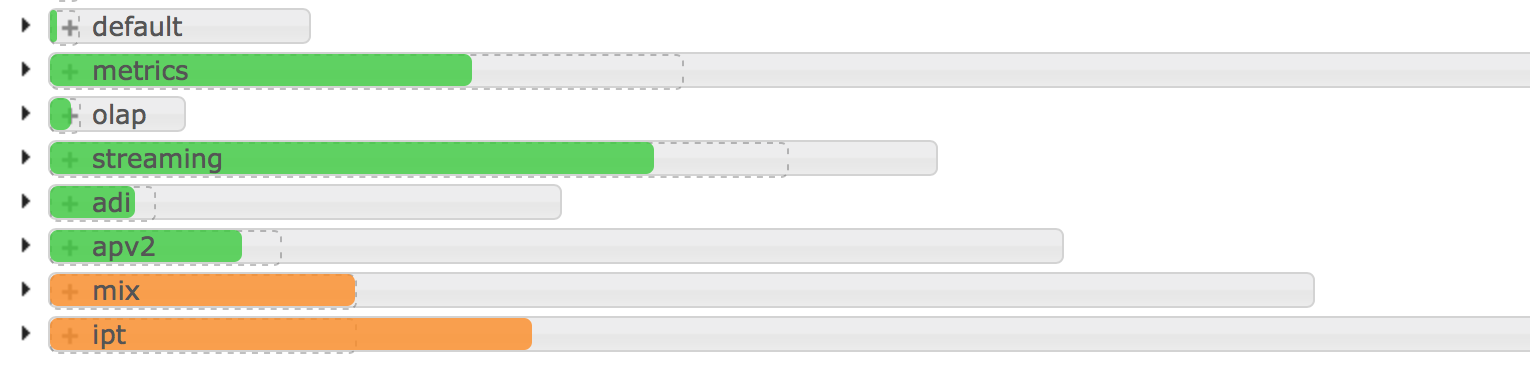
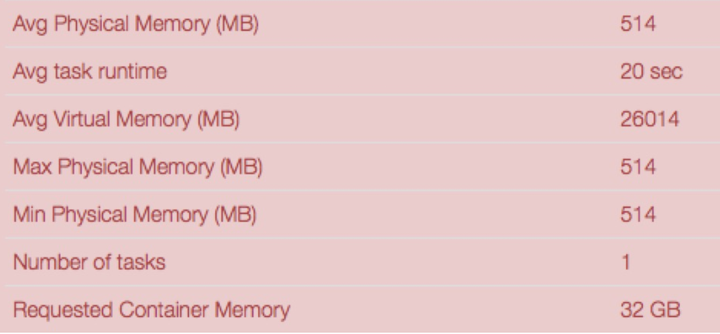
R2.應用程序濫用問題。
先給大家show幾個圖,第一個圖是一個app,經過分析,他申請了32GB的內存,而統計後平均使用的內存是514MB ! what ! 作爲管理員,看到這種用戶,是不是想罵街。。
第二個是app申請的資源,這一個app申請了740個cpu,3000GB的總內存,這類app很多。這種app我認爲調優的空間都很大。一個mapper/reducer能優化30%的內存佔用量,總體看就是一個很客觀的數字。

4.2 yarn的管理員問題
1.我們怎麼才能知道隊列的資源使用長期情況呢? 拿什麼數據來作爲調整yarn隊列queue級別資源的依據呢?
2.每次在新加入了一批機器後,我們當然要給機器打label,yarn的shell cmd中,打label:
yarn rmadmin -replaceLabelsOnNode “node1[:port]=label1 node2=label2
如果一次加入100臺機器,打label去輸入這麼多命令,很容易出問題。怎麼能又快速又安全的搞定這個工作呢?
3.用戶在channel不停的問application的問題,有什麼辦法能減少admin人工回覆用戶的工作,讓用戶自助解決問題?
4.3 node-label問題
然後在上一節,我提到我司使用的hadoop版本是基於apache hadoop 2.6.0,在node-label這裏有bug。
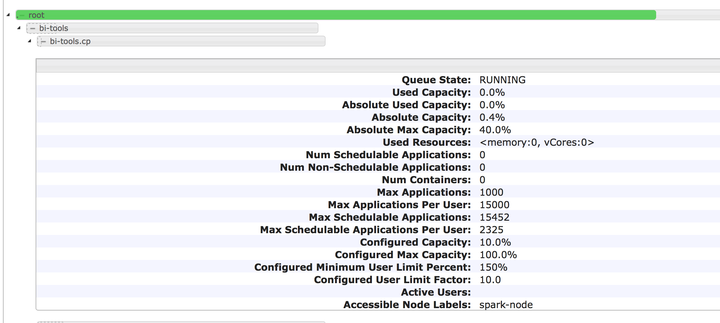
Bug1.缺乏 node-label 資源顯示。
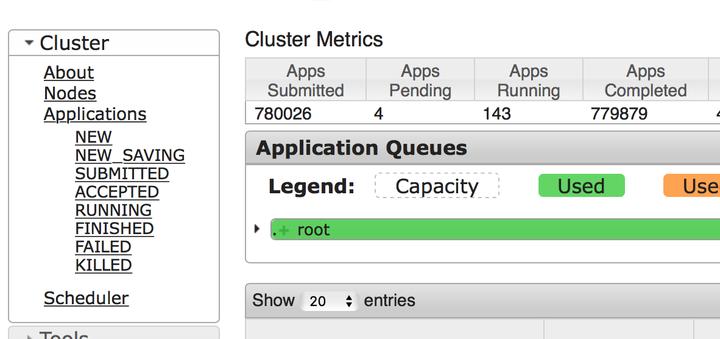 cdh-5.7.3-hadoop-2.6.0的yarn ui
cdh-5.7.3-hadoop-2.6.0的yarn ui
而穩定版本,是可以顯示出哪種label,有多少機器,有多少memory和cpu資源的。
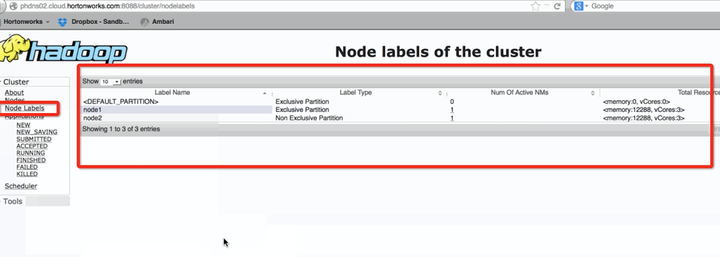 node-label 穩定版本 hadoop 2.8.x
node-label 穩定版本 hadoop 2.8.x
Bug2. yarn shell 功能不全。甚至不能使用list all labels功能。

Bug3. yarn ui沒有分label去顯示queue的資源使用率。
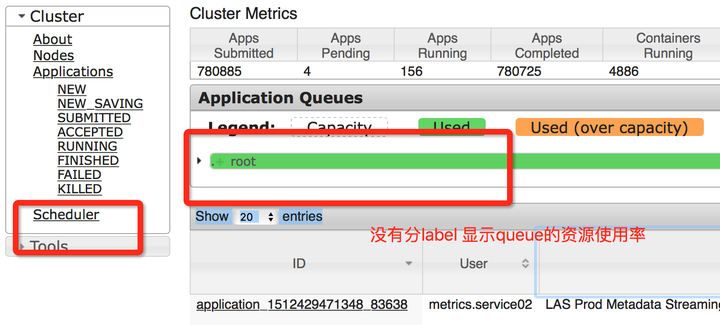 非穩定版
非穩定版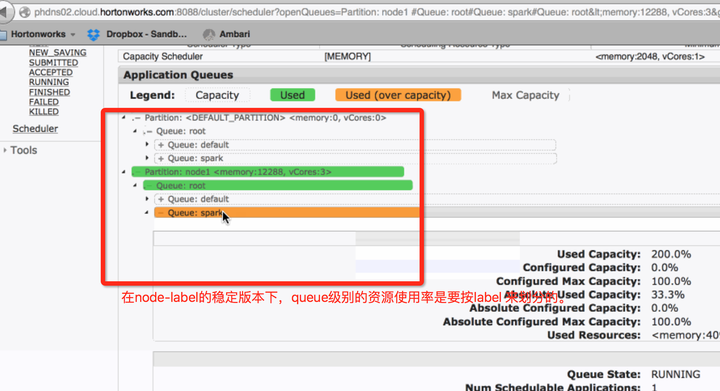 穩定版
穩定版
5. 數據驅動的yarn管理,資源治理
爲了解決上一節提出來的種種問題,我們做了很多自動化的工具。
我們用搜集“時間序列”的數據,來評估隊列的使用情況
用ui tool 來加快運維操作的批量性/安全性
用更簡潔明瞭的圖表,來給用戶展示他能得到的資源
等等。
5.1 yarn資源調配
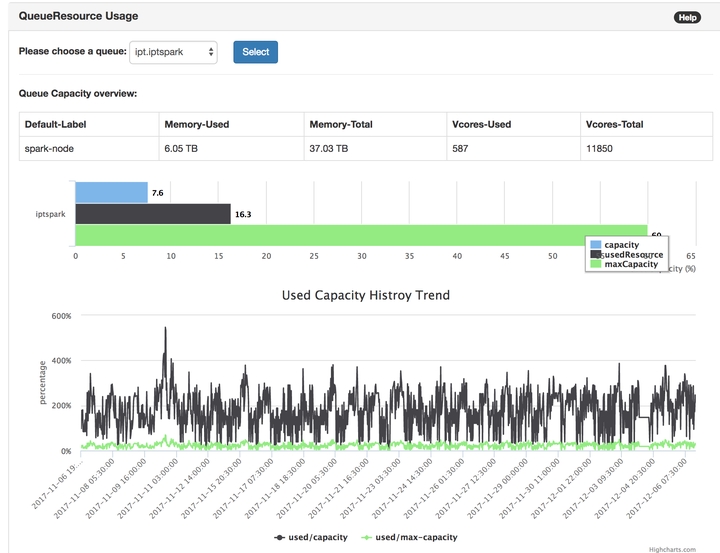
爲了解決yarn queue資源調配的公平。我們製作了yarn queue level 的 capacity 佔比history 趨勢圖。
總攬圖:所有子隊列的歷史資源使用都在這裏,可以看出哪個隊列長期超負荷運轉,哪些queue長期用不滿資源。總攬圖主要用來做對比,發現有問題的queue。
超負荷queue (長期capacity使用量都在100%以上的。配置了過高的max-capacity)
低負荷queue (長期capacity使用量低於50%的 )
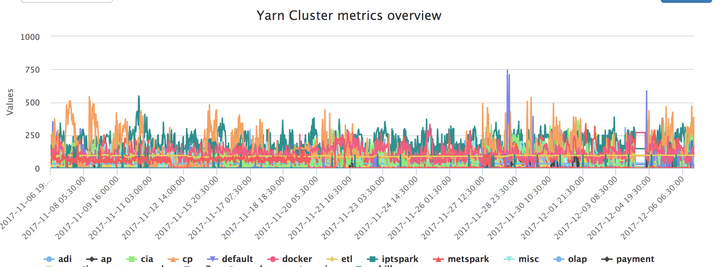
隊列圖:隊列圖是針對一個queue進行詳細的分析用的。包括隊列裏使用哪種label的機器,隊列有多少資源。隊列資源的歷史使用佔比,超負荷佔比,running/pending app歷史,以及reserve 的container歷史等等。
有了這兩張圖,在user對隊列資源提出質疑時,我們admin會先讓user自己看,是否本隊列的使用量已經滿了,以及是否隊列已經在reserve container,讓user心理有一個reasonable的預期。
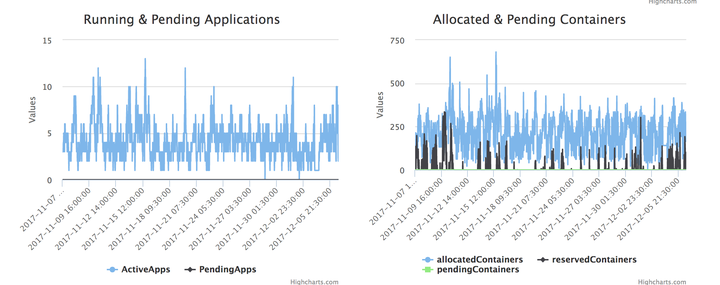
那麼,一次yarn的queue 級別資源調配應該是這樣的:
1.從“總攬圖”找到長期“低負荷queue”和“超負荷的queue”。
2.把相對“低負荷queue”隊列的資源,劃歸給“超負荷”的隊列。
3.等一段時間,觀察“總攬圖”,看“超負荷”隊列的資源使用情況是否變好,不是則重複1
5.2 yarn運維
在上一節,我們提到了給新加入集羣的機器打label是個漫長的過程。沒關係,本着在《大數據SRE的總結(0)--開篇 》提到的“讓一切人對機器的操作儘可能的自動化”的原則。我們設計的給node批量打label的ui界面。可以按着ctrl健,然後點擊鼠標來進行“多選”。這和window等操作系統的文件多選邏輯是相同的。最後選擇一個label,點擊完成按鈕。
5.3 yarn queue 級別資源分配頁面展示邏輯不友好
開源版本的yarn ui,樣式很土不說,很多重要的信息展示的也不夠透徹,比如:
yarn的queue資源分配到底佔了資源的多少。
缺失不同queue之間的資源對比
像這種文字類的ui,作爲使用hadoop的數據團隊user,是不夠直觀的。
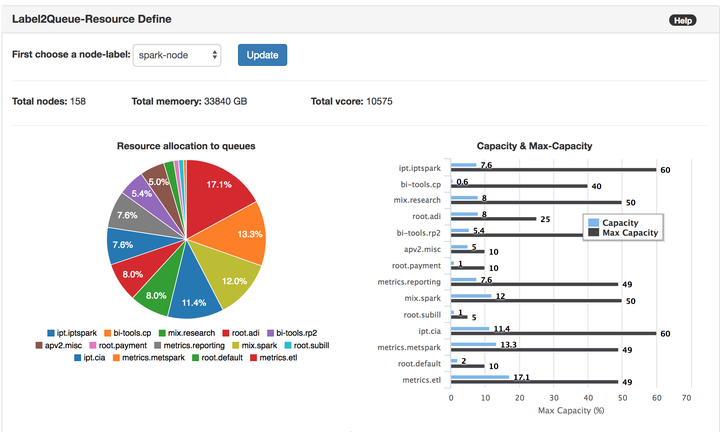
我們重繪了yarn 的queue level 資源分配。哪個queue分多少資源,一目瞭然。包括capacity和max-capacity的柱狀圖。
並且着重強調了node-label在劃分資源裏的重要性。
5.4 解決用戶自助排查問題。
這一塊我們使用了linkedin開源的dr.elephant linkedin/dr-elephant.
這個工具提供了很多針對hadoop job的診斷/調優信息,可以幫助用戶調優自己的hadoop job。我們也基於他做了很多二次開發,比如我們需要這樣的功能:
在某個“queue”下面,按“浪費”的內存數量倒排,分別羅列出所有浪費內存絕對數量/相對數量最多的 application。
這個工具的意義,就好比很多公司的“客服系統”。一些簡單的問題,先讓用戶自行解決,包括查閱文檔啊,語音機器人啊。當遇到實在很難解決的問題時,再進行人工介入。要知道,hadoop admin的人數在公司內是很少的,每個人的時間資源更是很寶貴的,不能陷入“運維陷阱”。
6 分析規律 反哺線上
如何調整yarn queue級別的資源分配,我們上一章已經做了簡單的介紹。
至於實操,每個公司都不一樣。但有一個通用的原則,即hadoop 運維團隊可以按 月/季度,設定運維日。所有需要調整yarn資源的需求,都發給管理員,待管理員在 運維日統一調整。
另外一個比較有意思的地方是,觀察yarn集羣資源使用率歷史走勢,往往有的高峯期和低谷期。
高峯期,可能會讓集羣的使用率持續打滿。 而低谷期,使用率往往又可能下降到50%甚至更低。通過我們繪製的集羣使用率“總攬圖”,以及隊列的“隊列圖”。可以分別觀察集羣總體的規律,和每個隊列的規律。
比如我們的yarn總體使用量走勢,如下圖所示:
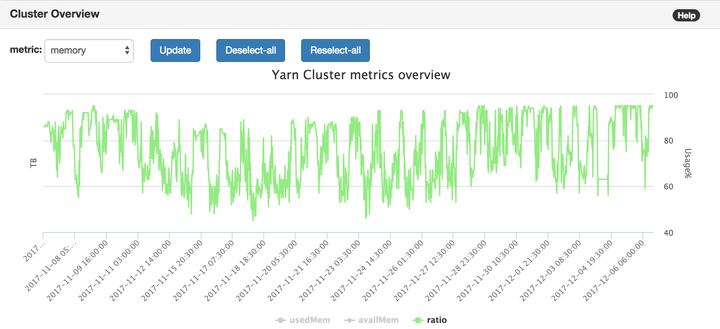
我們分析,yarn job的最大的來源,是來自於作業的調度,即調度系統!
我們可以看到。每一天的凌晨零點左右,資源使用率都會爬上去直到100%,而每一天的早上6點到下午3點,集羣資源使用率都會下降,甚至下探到50%以下。
很多調度系統都是按天級別來調度作業的,允許用戶配置類似cron語法的job。很多調度系統還提供了簡單的daily選項(airflow daily),而這個選項就默認把作業的調度時間設置爲了0點。這樣在0點附近,大規模的作業被同時調度出去,互相擠佔資源,大家都跑的慢。
我們會建議數據團隊們,把不那麼重要的job,更改其daily運行的小時點,“錯峯”運行。
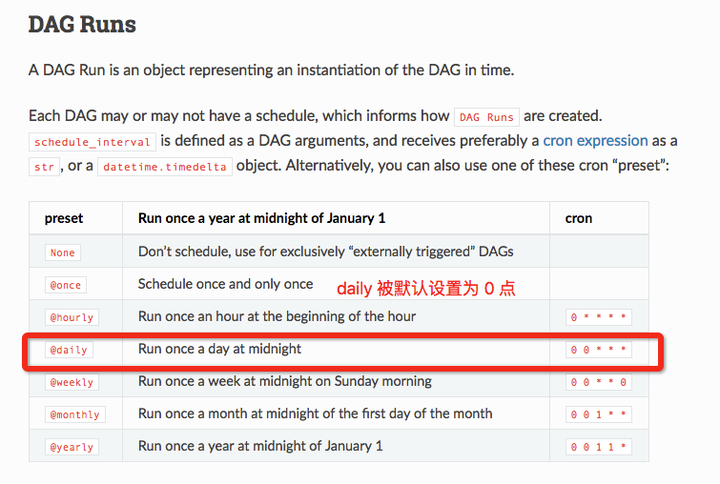 airflow 的 daily 調度默認爲0點
airflow 的 daily 調度默認爲0點
總結
1. 用數據說話,讓一切人的決策基於數據
2. 開發靈活方便的tool ,讓一切人對機器的操作儘可能的自動化
3. 謹慎使用開源版本,尤其是非穩定的需要打patch的功能,做好踩坑填坑的準備