




今天大家一起來學習一下參數化的一個重要工具,我們在寫腳本時,經常要用到參數化,而實現參數化最常用的方法之一就是使用CSV Data Set Config元件,使用方便,功能強大。
簡單的使用方法估計大家都會,或者說很容易就會了,但是,如果說是比較複雜的配置,估計就有很多人會被繞暈了(我剛開始也經常暈~),今天咱們就詳細看看,怎麼才能不暈!哈哈
首先來看一眼長啥樣,相信大家都比較熟悉
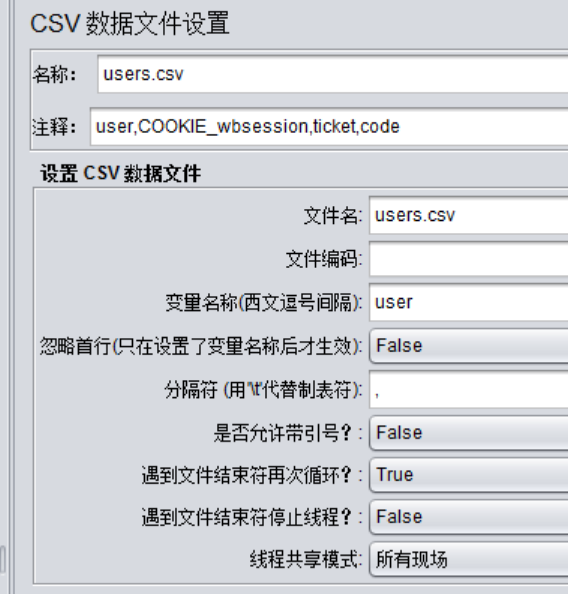
該元件的作用:
從文件中讀取變量值,用於變量的參數化,可設置多種讀取方式。
各填寫項說明:
1、名稱、註釋:元件的名稱及註釋,可自定義
2、Config the CSV Data Source:配置數據源
1)Filename:csv文件的名稱
注意:這裏要包括文件的路徑,在4.0版本中可以點擊右側的瀏覽按鈕選擇文件,會自動帶上文件的絕對路徑;
另外,當csv文件在jmeter的bin目錄或腳本目錄時,只需給出文件名即可;
使用相對路徑時,jmeter默認先去bin目錄下查找,然後去腳本目錄下查找;
2)File encoding:csv文件編碼
默認使用當前操作系統的編碼格式;
如果文件中包含中文亂碼時,可嘗試utf-8、gbk等;
3)Variable Names(comma-delimited):
csv文件中各列的名字(有多列時,用英文逗號隔開列名);
名字順序要與內容對應,這個變量名稱是在其他處被引用的,所以爲必填項。
4)Delimiter(use “t” for tab):csv文件中的分隔符(用”t”代替tab鍵)
一般情況下,分隔符爲英文逗號,保持默認就行
5)Allow quoted data?:是否允許數據內容加引號
6)Recycle on EOF?:
到了文件尾是否循環,True—繼續從文件第一行開始讀取,False—不再循環;
此項與下一項的設置爲互斥關係,即true-false,或false-true;
7)Stop thread on EOF?:
到了文件尾是否停止線程,True—停止,False—不停止;
注意:當Recycle on EOF設置爲True時,此項設置無效。
8)Sharing mode:共享模式
All threads –所有線程,此元件作用範圍內的所有線程共享csv數據,每個線程依次讀取csv數據,互不重複;
Current thread group—當前線程組,在此元件作用範圍內,以線程組爲單位,每個線程組內的線程共享csv數據,依次讀取數據,互不重複;
Current thread—當前線程,在此元件作用範圍內,每次循環中所有線程取值一樣;
下面重點分析一下Allow quoted data和Sharing mode:
1、Allow quoted data?:是否允許帶雙引號的數據
此項實際是控制csv文件中的雙引號是否爲有效字符;
如果數據帶有雙引號且此項設置TRUE,則會自動去掉數據中的引號使能夠正常讀取數據,且即使引號之間的內容包含有分隔符時,仍作爲一個整體而不進行分隔;
如果數據帶有引號且此項設置爲FALSE,則讀取數據報錯;
如果希望雙引號字段中間再包含雙引號,則需要加兩個雙引號來代表單個雙引號。(啊啊啊,太拗口了!!!)
如下圖所示,此項設置爲true時,"2,3"-->2,3;"4""5"-->4"5
2、Sharing mode:共享模式
(1)All threads:針對所有線程組的所有線程,每個線程取值不一樣,依次取csv文件中的下一行。
假如說有線程1到線程n (n>1),線程1取了一次值後,線程2取值時,取到的是csv文件中的下一行,即與線程1取的不是同一行。不管是單個線程組還是多個線程組,每個線程都是依次取下一行。需要注意的是,當一個線程組中有多個請求時,對於每個線程來說,在一次循環中每個請求的取值是一樣的。
下面舉例說明:
A、設置線程組1、2、3分別爲1併發、1次循環,且各線程組按順序執行: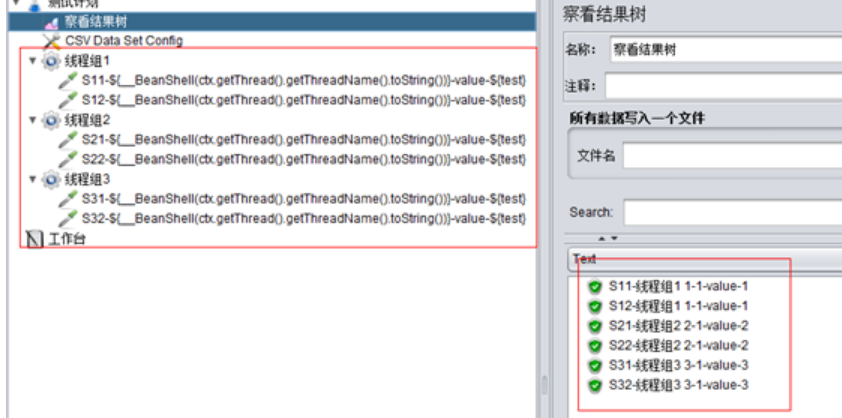
B、設置線程組1、2、3分別爲1併發、2次循環,且各線程組按順序執行: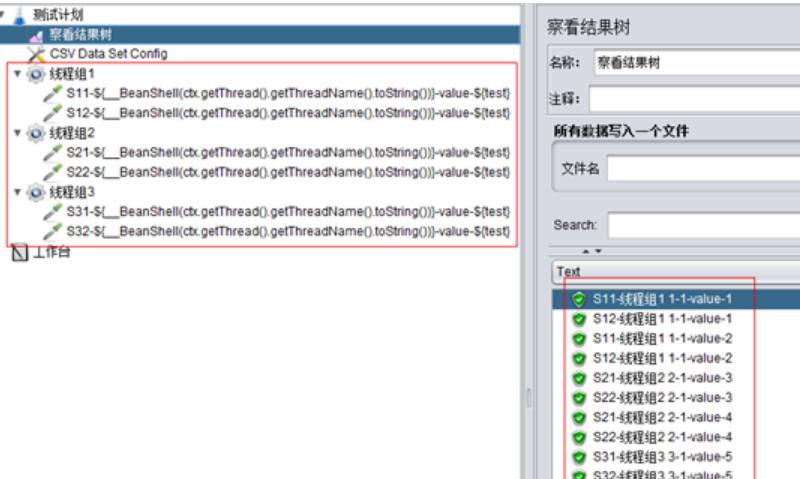
C、設置線程組1、2、3分別爲2併發、1次循環,且各線程組按順序執行: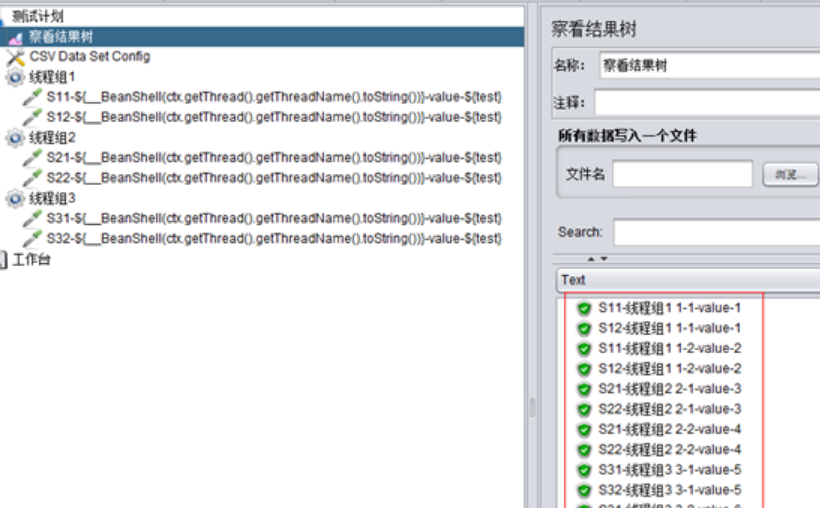
大家可以仔細比較一下上圖和上上圖的區別,乍一看貌似是一樣的,但是實際卻是不同的線程,怎麼區分不同線程呢?
可以使用一個函數來判斷:
${__BeanShell(ctx.getThread().getThreadName().toString())}
這個函數可以輸出類似這樣的內容:“線程組1 1-2“,前面是當前線程組的名稱-線程組1,後面是線程組id,然後是線程id,現在再比較上面兩圖中,發現是線程id不一樣。
總體來說就是,在All Threads模式下,併發數和循環數都會讀取不同的csv數據,但是同一線程組內的多個sampler總是取相同的值。
(2)Current thread group:當前線程組,
取值情況是:以線程組爲單位,每個線程組內的線程都會從第1行開始取值並依次往下進行取值。
舉例如下:
A、設置線程組1、2均爲2併發、1循環: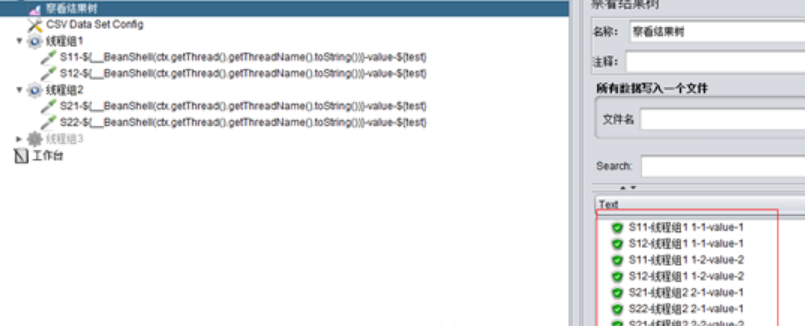
(3)Current thread:當前線程。
取值情況是:每個線程都會從第1行開始取值並依次往下進行取值,在同一次循環中所有的線程取值一樣。
舉例如下:
A、設置線程組1、2均爲2併發、1循環:
上面兩個圖看起來好像是一樣的呀?再仔細看一下,後面的test參數取值是不同的。
爲什麼不同呢?本來想認真的解釋一番,但是組織了很久的語言,還是感覺沒說清楚。
這一塊的邏輯是“只可意會,不可言傳”,必須要靠自己親自實驗,慢慢體會才行。
最後,給大家一個小作業:
如何通過設置Sharing moder的方法來實現多個sampler中的參數可以依次不重複的取同一個csv文件中的值?