




項目架構: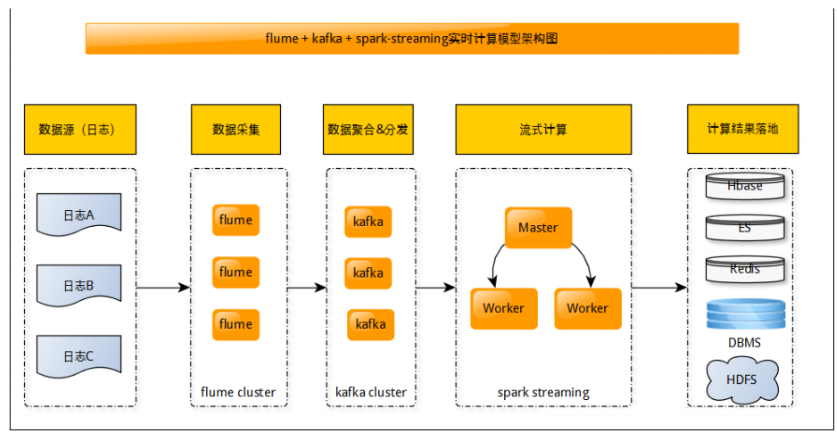
日誌數據---->flume----->kafka-------->spark streaming---------->mysql/redis/hbase
前置條件:
- 安裝zookeeper
- 安裝flume
- 安裝kafak
- hadoop實現高可用
(1)實現flume收集數據到kafka
啓動kafak:
nohup kafka-server-start.sh \
/application/kafka_2.11-1.1.0/config/server.properties \
1>/home/hadoop/logs/kafka_std.log \
2>/home/hadoop/logs/kafka_err.log &創建一個沒有的kafaktopic:
kafka-topics.sh \
--create \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka \
--replication-factor 3 \
--partitions 3 \
--topic zy-flume-kafka查看是否創建成功:
kafka-topics.sh \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka \
--describe \
--topic zy-flume-kafka
配置flume的採集方案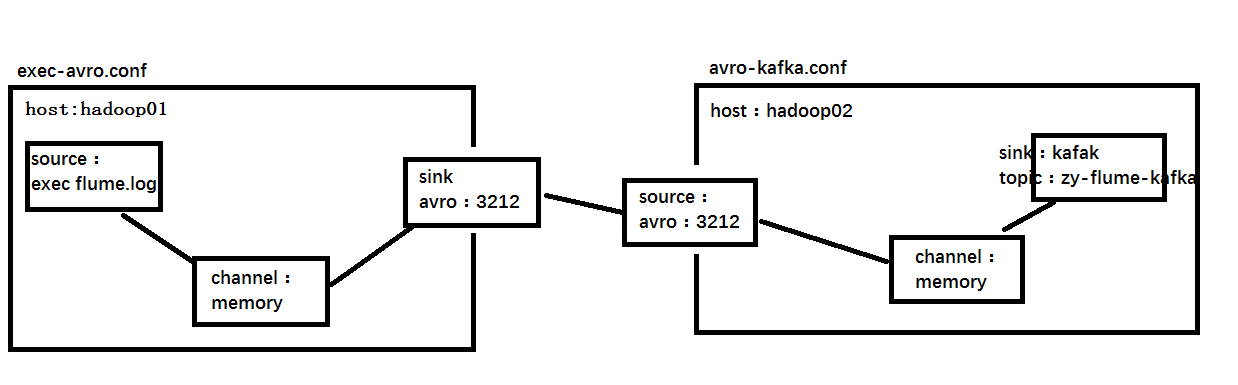
第一級:exec-avro.conf
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
#define sources
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /application/flume-1.8.0-bin/data/sample.log
#define channels
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
#define sink
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop02
agent1.sinks.k1.port = 3212
#bind sources and sink to channel
agent1.sources.r1.channels = c1
agent1.sinks.k1.channel = c1第二級:avro-kafka.conf
agent2.sources = r2
agent2.channels = c2
agent2.sinks = k2
#define sources
agent2.sources.r2.type = avro
agent2.sources.r2.bind = hadoop02
agent2.sources.r2.port = 3212
#define channels
agent2.channels.c2.type = memory
agent2.channels.c2.capacity = 1000
agent2.channels.c2.transactionCapacity = 100
#define sink
agent2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent2.sinks.k2.brokerList = hadoop01:9092,hadoop02:9092,hadoop03:9092
agent2.sinks.k2.topic = zy-flume-kafka
agent2.sinks.k2.batchSize = 4
agent2.sinks.k2.requiredAcks = 1
#bind sources and sink to channel
agent2.sources.r2.channels = c2
agent2.sinks.k2.channel = c2啓動flume
hadoop02:
flume-ng agent \
--conf /application/flume-1.8.0-bin/conf/ \
--name agent2 \
--conf-file /application/flume-1.8.0-bin/flume_sh/avro-kafka.conf \
-Dflume.root.logger=DEBUG,consolehadoop01:
flume-ng agent \
--conf /application/flume-1.8.0-bin/conf/ \
--name agent1 \
--conf-file /application/flume-1.8.0-bin/flume_sh/exec-avro.conf \
-Dflume.root.logger=DEBUG,console注意:一定要先啓動第二級在啓動第一級
測試
啓動一個kafakconsumer
kafka-console-consumer.sh \
--bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 \
--from-beginning \
--topic zy-flume-kafka向監控文件下添加數據:tail -10 sample.temp>>sample.log
觀察kafkaconsumer:消費到數據!!
(2)實現sparkStreaming讀取kafka中數據並處理
SparkStreaming整合kafka有兩種方式:
- receiver +checkpoint方式
- direct +zookeeper方式
1)receiver +checkpoint方式
代碼:
/**
* 基於Receiver的方式去讀取kafka中的數據
*/
object _01SparkKafkaReceiverOps {
def main(args: Array[String]): Unit = {
//判斷程序傳入的參數個數是否正確
//2 hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka first zy-flume-kafka
if (args == null || args.length < 4) {
println(
"""
|Parameter Errors! Usage: <batchInterval> <zkQuorum> <groupId> <topics>
|batchInterval : 批次間隔時間
|zkQuorum : zookeeper url地址
|groupId : 消費組的id
|topic : 讀取的topic
""".stripMargin)
System.exit(-1)
}
//獲取程序傳入的參數
val Array(batchInterval, zkQuorum, groupId, topic) = args
//1.構建程序入口
val conf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("_01SparkKafkaReceiverOps")
val ssc =new StreamingContext(conf,Seconds(2))
/**2.使用Receiver方式讀取數據
* @param ssc
* @param zkQuorum
* @param groupId
* @param topics
* @param storageLevel default: StorageLevel.MEMORY_AND_DISK_SER_2
* @return DStream of (Kafka message key, Kafka message value)
*/
val topics = topic.split("\\s+").map((_,3)).toMap
//2.讀取數據
val message: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,zkQuorum,groupId,topics)
//3.打印數據
message.print()
//4.提交任務
ssc.start()
ssc.awaitTermination()
}
}注意(receiver +checkpoint):
- kafka中的topic和sparkstreaming中生成的RDD分區沒有關係,在KafkaUtils.createStream中增加分區數只會增加單個receiver的線程數,不會增加spark的並行度
- 可以創建多個kafka的輸入DStream,使用不同的group和topic,使用多個receiver並行接收數據
- 如果啓用了HDFS等有容錯的存儲系統,並且啓用了寫入日,則接收到的數據已經被複制到日誌中。
2)direct +zookeeper方式
代碼實現
package com.zy.streaming
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.curator.framework.{CuratorFramework, CuratorFrameworkFactory}
import org.apache.curator.retry.ExponentialBackoffRetry
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用zk來管理的消費的偏移量,確保當SparkStreaming掛掉之後在重啓的時候,
* 能夠從正確的offset偏移量的位置開始消費,而不是從頭開始消費
*/
object SparkStreamingDriverHAOps {
//設置zookeeper中存放偏移量的位置
val zkTopicOffsetPath="/offset"
//獲取zookeeper的編程入口
val client:CuratorFramework={
val client=CuratorFrameworkFactory.builder()
.connectString("hadoop01:2181,hadoop02:2181,hadoop03:2181/kafka")
.namespace("2019_1_7")
.retryPolicy(new ExponentialBackoffRetry(1000,3))
.build()
client.start()
client
}
def main(args: Array[String]): Unit = {
//屏蔽日誌
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.project-spark").setLevel(Level.WARN)
//2 direct zy-flume-kafka
if(args==null||args.length<3){
println(
"""
|Parameter Errors! Usage: <batchInterval> <groupId> <topics>
|batchInterval : 批次間隔時間
|groupId : 消費組的id
|topic : 讀取的topic
""".stripMargin)
System.exit(-1)
}
//獲取傳入的參數
val Array(batchInterval,groupId,topic)=args
//1.構建程序入口
val conf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkStreamingDriverHAOps")
val ssc =new StreamingContext(conf,Seconds(batchInterval.toLong))
//連接kafka的參數
val kafkaParams=Map(
"bootstrap.servers"->"hadoop01:9092,hadoop02:9092,hadoop03:9092", //集羣入口
"auto.offset.reset"->"smallest" //消費方式
)
//2.創建kafka的message
val message:DStream[(String,String)]=createMessage(topic,groupId,ssc,kafkaParams)
//3.業務處理,這裏主要是介紹如何kafka整合sparkStreaming,所以這裏不做業務處理
message.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
println(
"""
|####################>_<####################
""".stripMargin+rdd.count())
}
//更新偏移量
storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges,groupId)
})
//4.啓動程序
ssc.start()
ssc.awaitTermination()
}
/**
* 創建kafka對應的message
* 分兩種情況:
* 1.第一次消費的時候,從zk中讀取不到偏移量
* 2.之後的消費從zk中才能讀取到偏移量
*/
def createMessage(topic: String, groupId: String, ssc: StreamingContext, kafkaParams: Map[String, String]): InputDStream[(String, String)] = {
//獲取偏移量,以及判斷是否是第一次消費
val (fromOffsets,flag)=getFromOffsets(topic, groupId)
var message:InputDStream[(String, String)] = null
//構建kafka對應的message
if(flag){ //標記位,使用zk中得到的對應的partition偏移量信息,如果有爲true
/**
* recordClass: Class[R],
* kafkaParams: JMap[String, String],
* fromOffsets: JMap[TopicAndPartition, JLong],
* messageHandler: JFunction[MessageAndMetadata[K, V], R]
*/
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key, mmd.message)
message = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder,(String,String)](ssc,kafkaParams,fromOffsets,messageHandler)
}else{ //如果是第一次讀取爲false
/**
* createDirectStream[
* String, key的類型
* String, value的類型
* StringDecoder, key的序列化的類型
* StringDecoder] value的序列化的類型
*
*/
message=KafkaUtils.createDirectStream[String,
String,
StringDecoder
, StringDecoder](ssc,kafkaParams,topic.split("\\s+").toSet)
}
message
}
//獲取對應的topic中的每一個partition的偏移量信息
def getFromOffsets(topic: String, groupId: String):(Map[TopicAndPartition, Long], Boolean)= {
//構建存儲offset的位置信息的路徑
val zkPath=s"${zkTopicOffsetPath}/${topic}/${groupId}"
//判斷當前路徑是否存在,不存在則創建
nsureZKPathExists(zkPath)
//獲取所有分區中存儲的offset信息
import scala.collection.JavaConversions._
val offsets=for{p<-client.getChildren.forPath(zkPath)}yield{
val offset=new String(client.getData.forPath(s"${zkPath}/${p}")).toLong
(new TopicAndPartition(topic,p.toInt),offset)
}
//如果未空表示第一次讀取,無偏移量信息
if(offsets.isEmpty){
(offsets.toMap,false)
}else{
(offsets.toMap,true)
}
}
def storeOffsets(offsetRanges: Array[OffsetRange], groupId: String): Unit = {
for(offsetRange<-offsetRanges){
val partition=offsetRange.partition
val topic=offsetRange.topic
//獲取偏移量
val offset=offsetRange.untilOffset
//構建存放偏移量的znode
val path=s"${zkTopicOffsetPath}/${topic}/${groupId}/${partition}"
//判斷是否存在,不存在則創建
nsureZKPathExists(path)
client.setData().forPath(path,(""+offset).getBytes())
}
}
def nsureZKPathExists(zkPath: String) = {
//如果爲空的話就創建
if(client.checkExists().forPath(zkPath)==null){
//如果父目錄不存在,連父目錄一起創建
client.create().creatingParentsIfNeeded().forPath(zkPath)
}
}
}注意(direct +zookeeper):
- 不需要創建多個輸入kafka流並將其合併,使用directStream,spark Streaming將創建於使用kafka分區一樣多的RDD分區,這些分區的數據全部從kafka並行讀取數據,kafka和RDD分區之間有一對一的映射關係。
- Direct方式沒有接收器,不需要預先寫入日誌,只要kafka數據保留時間足夠長就行
- 保證了正好一次的消費語義(offset保存在zookeeper中)