




隨之互聯網的快速化發展,因特網變成大批量信息的傳遞,怎樣有效性地獲取並運用這種信息內容變成1個極大的挑戰。剛開始,互聯網技術都還沒檢索。在百度搜索引擎被開發設計出去以前,互聯網技術僅僅文件傳輸協議(FTP)站點的集合,普通用戶還可以在這種站點地圖中導行以尋找特殊的共享文件。以便搜索和組合移動互聯網上能用的分佈式系統統計數據,大家建立了一個自動化技術程序流程,稱之爲網絡爬蟲,還可以爬取移動互聯網上的所有網頁,隨後將所有頁面上的內容複製到數據庫中製作索引。
目前我們所使用的搜索引擎作爲一個輔助人們檢索信息的工具,成爲用戶訪問萬維網的入口和指南。其中網絡爬蟲是一個自動提取網頁的程序,它爲搜索引擎從萬維網上下載網頁,是搜索引擎的重要組成。(1993年首個基於爬蟲技術的網絡搜索引擎JumpStation誕生,成爲了首個依靠網絡爬蟲的WWW搜索引擎)
隨着萬維網數據形式的豐富和網絡技術的不斷髮展,圖片、數據庫、音頻/視頻多媒體等不同數據大量出現,互聯網變成了一個巨大的數據源,隨着數據不斷積累,數據源不斷豐富,信息越來越容易搜索,但同時不同領域、不同背景的用戶往往具有不同的檢索目的和需求,通過搜索引擎所返回的結果也包含了越來越多用戶並不關心的信息,而通用搜索引擎往往對這些信息含量密集且具有一定結構的數據無能爲力,不能很好地發現和獲取,有限的搜索引擎服務器資源與無限的網絡數據資源之間的矛盾將進一步加深。
爲了解決這個問題,定向抓取相關網頁資源的聚焦爬蟲應運而生。聚焦爬蟲是一個自動下載網頁的程序,它根據既定的抓取目標,有選擇的訪問萬維網上的網頁與相關的鏈接,獲取所需要的信息。與通用爬蟲不同,聚焦爬蟲並不追求大的覆蓋,而將目標定爲抓取與某一特定主題內容相關的網頁,爲面向主題的用戶查詢準備數據資源。
以聚焦爬蟲在互聯網金融領域的應用爲例,簡述聚焦爬蟲是如何發揮作用;
互聯網金融(ITFIN)是指傳統金融機構與互聯網企業利用互聯網技術和信息通信技術實現資金融通、支付、投資和信息中介服務的新型金融業務模式。在利用這些技術的基礎上,首先必須要獲取到最基本最必須也是最核心的數據。那麼獲取數據有很多種辦法,比如聚焦爬蟲。互聯網金融一般都是使用垂直型爬蟲(聚焦爬蟲的一種),垂直型爬蟲關注內容與準確還有效率。比較常見的就是輿情項目,財經項目等。僅僅抓取到有效有用的數據,並且在爬蟲 抓取之初就能夠把抓取到的內容進行簡單的處理,如:提取標題,內容,時間等。
(附加內容)幾種互聯網金融常用的爬蟲架構圖:
1、應用場景:獲取網絡公開信息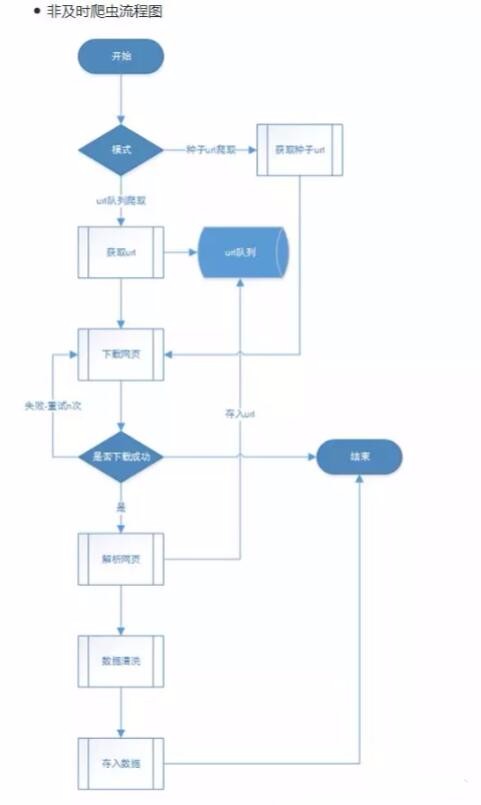
2、 應用場景:獲取實時信息
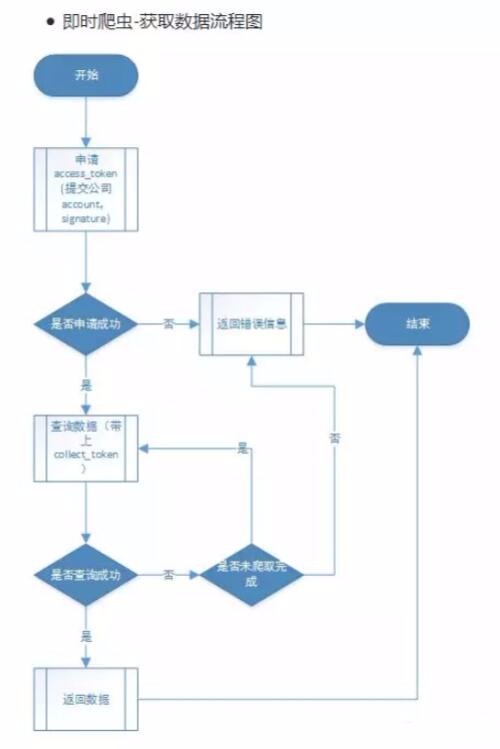
3、應用場景:獲取部分授權信息
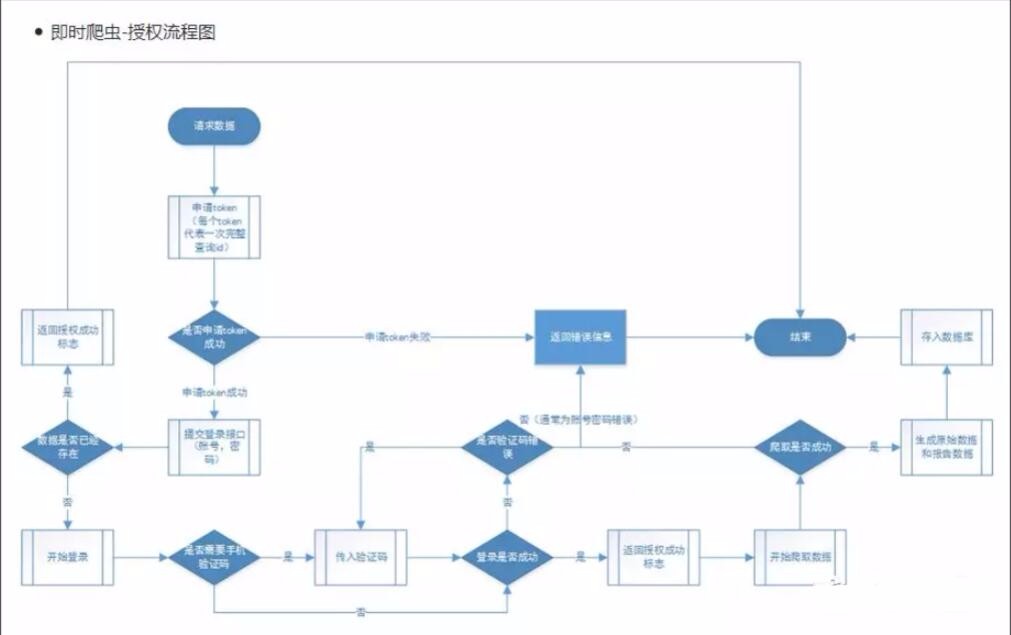
由於與網絡爬蟲仍處於發展階段,所以它的發展仍然未定且難以預測。然而,有一件事是肯定的,那就是,只要有互聯網,就會有爬蟲。