




轉載自:https://www.cnblogs.com/itboys/p/9201750.html
這裏只取其前面的部分,跟之前看的一樣,不過自己就懶得去畫圖總結了。然後取前半部分是因爲,目前對於Spark的學習還是在1.6,我也希望後面有時間接觸一下2.x的,因爲之前跟朋友討論過,他告訴我2.x跟1.6還是有不少的差異的,至少在使用姿勢上,然而我也是十分無奈,因爲現階段確實沒有太多的機會去接觸2.x的東西,然而我相信很快就有了。
另外,如果有MapReduce的編程經驗,其實spark的shuffle過程也是很好理解的,之前有寫過MapReduce shuffle過程的文章,其實就是那個很經典的圖。
最近把《Hadoop權威指南》關於Spark的部分翻出來看了下,發現真的都是精華,發現它把之前自己學習Spark的很多基礎理論知識很好的總結到了一塊,尤其是Spark On Yarn-Client&Cluster那一小節,真的總結得太好了!
什麼時候需要 shuffle writer
假如我們有個 spark job 依賴關係如下
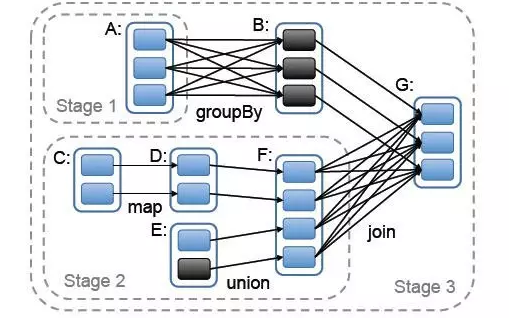
我們抽象出來其中的rdd和依賴關係:
E <-------n------, C <--n---D---n-----F--s---, A <-------s------ B <--n----`-- G
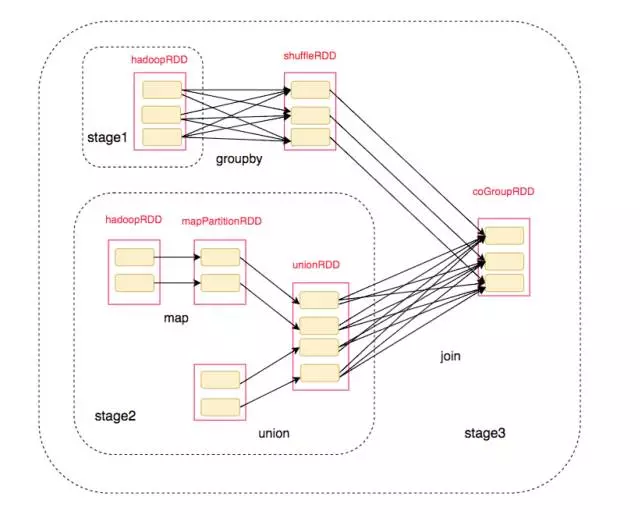
對應的劃分後的RDD結構爲:
最終我們得到了整個執行過程:
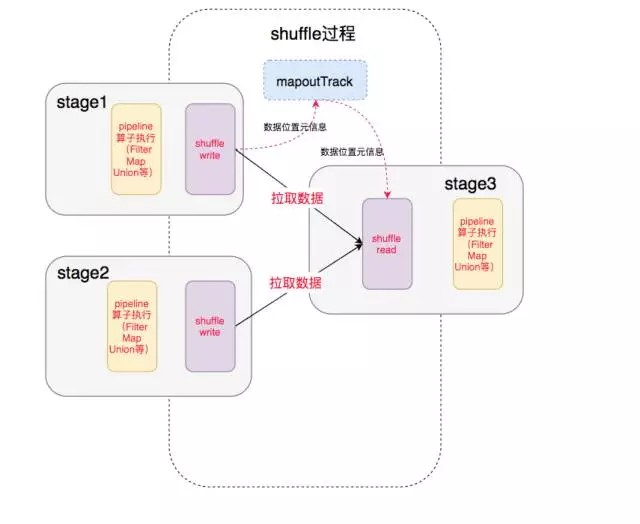
中間就涉及到shuffle 過程,前一個stage 的 ShuffleMapTask 進行 shuffle write, 把數據存儲在 blockManager 上面, 並且把數據位置元信息上報到 driver 的 mapOutTrack 組件中, 下一個 stage 根據數據位置元信息, 進行 shuffle read, 拉取上個stage 的輸出數據。
這篇文章講述的就是其中的 shuffle write 過程。
spark shuffle 演進的歷史
Spark 0.8及以前 Hash Based Shuffle
Spark 0.8.1 爲Hash Based Shuffle引入File Consolidation機制
Spark 0.9 引入ExternalAppendOnlyMap
Spark 1.1 引入Sort Based Shuffle,但默認仍爲Hash Based Shuffle
Spark 1.2 默認的Shuffle方式改爲Sort Based Shuffle
Spark 1.4 引入Tungsten-Sort Based Shuffle
Spark 1.6 Tungsten-sort併入Sort Based Shuffle
Spark 2.0 Hash Based Shuffle退出歷史舞臺
總結一下, 就是最開始的時候使用的是 Hash Based Shuffle, 這時候每一個Mapper會根據Reducer的數量創建出相應的bucket,bucket的數量是M R ,其中M是Map的個數,R是Reduce的個數。這樣會產生大量的小文件,對文件系統壓力很大,而且也不利於IO吞吐量。後面忍不了了就做了優化,把在同一core上運行的多個Mapper 輸出的合併到同一個文件,這樣文件數目就變成了 cores R 個了,
舉個例子:
本來是這樣的,3個 map task, 3個 reducer, 會產生 9個小文件,
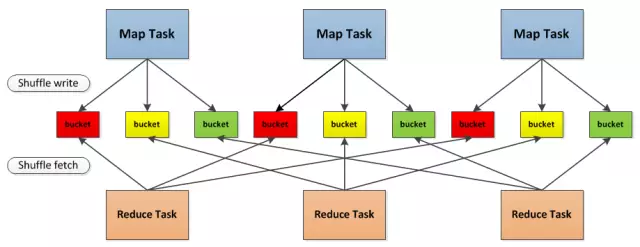
是不是很恐怖, 後面改造之後
4個map task, 4個reducer, 如果不使用 Consolidation機制, 會產生 16個小文件。
但是但是現在這 4個 map task 分兩批運行在 2個core上, 這樣只會產生 8個小文件
在同一個 core 上先後運行的兩個 map task的輸出, 對應同一個文件的不同的 segment上, 稱爲一個 FileSegment, 形成一個 ShuffleBlockFile,
後面就引入了 Sort Based Shuffle, map端的任務會按照Partition id以及key對記錄進行排序。同時將全部結果寫到一個數據文件中,同時生成一個索引文件, 再後面就就引入了 Tungsten-Sort Based Shuffle, 這個是直接使用堆外內存和新的內存管理模型,節省了內存空間和大量的gc, 是爲了提升性能。
現在2.1 分爲三種writer, 分爲 BypassMergeSortShuffleWriter, SortShuffleWriter 和 UnsafeShuffleWriter,顧名思義,大家應該可以對應上,我們本着過時不講的原則, 本文中只描述這三種 writer 的實現細節, Hash Based Shuffle 已經退出歷史舞臺了,我就不講了。