




背景信息
目標
本文主要介紹如何讓阿里雲日誌服務與您的SIEM方案(如Splunk)對接, 以便確保阿里雲上的所有法規、審計、與其他相關日誌能夠導入到您的安全運維中心(SOC)中。
名詞解釋
LOG(SLS) - 阿里雲日誌服務,簡寫SLS表示(Simple Log Service)。
SIEM - 安全信息與事件管理系統(Security Information and Event Management),如Splunk, QRadar等。
Splunk HEC - Splunk的Http事件接收器(Splunk Http Event Collector), 一個 HTTP(s)接口,用於接收日誌。
審計相關日誌
安全運維團隊一般對阿里雲相關的審計日誌感興趣,如下列出所有存在於所有目前在日誌服務中可用的相關日誌(但不限於):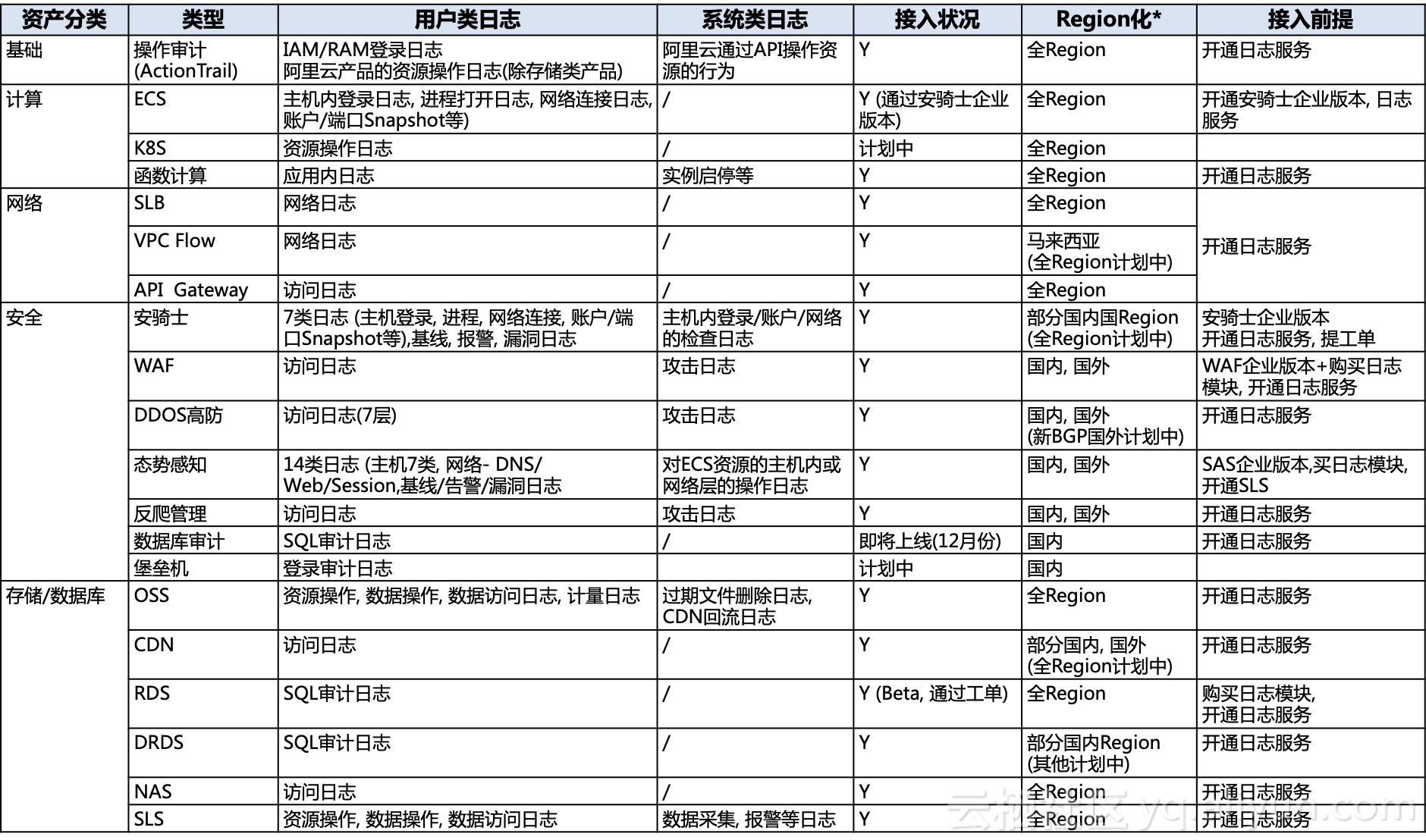
Regions化 - 時刻更新,請以最新的產品文檔爲準。
阿里雲日誌服務
阿里雲的日誌服務(log service)是針對日誌類數據的一站式服務,無需開發就能快捷完成海量日誌數據的採集、消費、投遞以及查詢分析等功能,提升運維、運營效率。日誌服務主要包括 實時採集與消費、數據投遞、查詢與實時分析 等功能,適用於從實時監控到數據倉庫的各種開發、運維、運營與安全場景:
目前,以上各個阿里雲產品已經與日誌服務打通,提供近實時的日誌自動採集存儲、並提供基於日誌服務的查詢分析、報表報警、下游計算對接與投遞的能力。
集成方案建議
概念
項目(Project)
項目(Project)是日誌服務中的資源管理單元,用於資源隔離和控制。您可以通過項目來管理某一個應用的所有日誌及相關的日誌源。它管理着用戶的所有日誌庫(Logstore),採集日誌的機器配置等信息,同時它也是用戶訪問日誌服務資源的入口。
日誌庫(Logstore)
日誌庫(Logstore)是日誌服務中日誌數據的收集、存儲和查詢單元。每個日誌庫隸屬於一個項目,且每個項目可以創建多個日誌庫。
分區(Shard)
每個日誌庫分若干個分區(Shard),每個分區由MD5左閉右開區間組成,每個區間範圍不會相互覆蓋,並且所有的區間的範圍是MD5整個取值範圍。
服務入口(Endpoint)
日誌服務入口是訪問一個項目(Project)及其內部日誌數據的 URL。它和 Project 所在的阿里雲區域(Region)及 Project 名稱相關。
https://help.aliyun.com/document_detail/29008.html
訪問祕鑰(AccessKey)
阿里雲訪問祕鑰是阿里云爲用戶使用 API(非控制檯)來訪問其雲資源設計的“安全口令”。您可以用它來簽名 API 請求內容以通過服務端的安全驗證。
https://help.aliyun.com/document_detail/29009.html
假設
這裏假設您的SIEM(如Splunk)位於組織內部環境(on-premise)中,而不是雲端。爲了安全考慮,沒有任何端口開放讓外界環境來訪問此SIEM。
概覽
推薦使用SLS消費組構建程序來從SLS進行實時消費,然後通過Splunk API(HEC)來發送日誌給Splunk。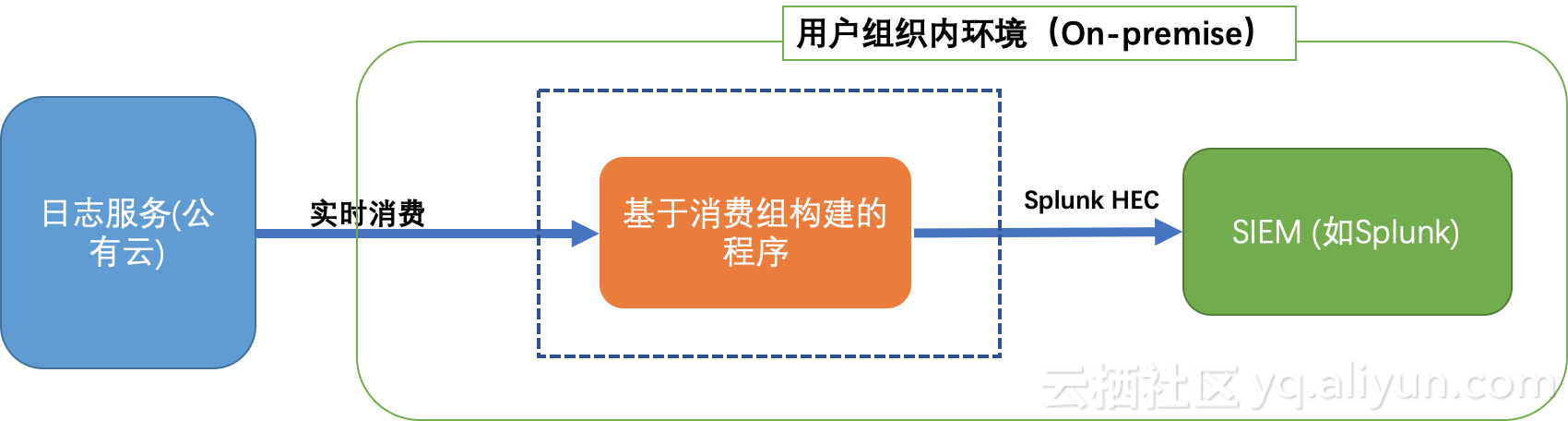
使用消費組編程
協同消費庫(Consumer Library)是對日誌服務中日誌進行消費的高級模式,提供了消費組(ConsumerGroup)的概念對消費端進行抽象和管理,和直接使用SDK進行數據讀取的區別在於,用戶無需關心日誌服務的實現細節,只需要專注於業務邏輯,另外,消費者之間的負載均衡、failover等用戶也都無需關心。
Spark Streaming、Storm 以及Flink Connector都以Consumer Library作爲基礎實現。
基本概念
消費組(Consumer Group) - 一個消費組由多個消費者構成,同一個消費組下面的消費者共同消費一個logstore中的數據,消費者之間不會重複消費數據。
消費者(Consumer) - 消費組的構成單元,實際承擔消費任務,同一個消費組下面的消費者名稱必須不同。
在日誌服務中,一個logstore下面會有多個shard,協同消費庫的功能就是將shard分配給一個消費組下面的消費者,分配方式遵循以下原則:
每個shard只會分配到一個消費者。
一個消費者可以同時擁有多個shard。
新的消費者加入一個消費組,這個消費組下面的shard從屬關係會調整,以達到消費負載均衡的目的,但是上面的分配原則不會變,分配過程對用戶透明。
協同消費庫的另一個功能是保存checkpoint,方便程序故障恢復時能接着從斷點繼續消費,從而保證數據不會被重複消費。
部署建議
硬件建議
硬件參數:
需要一臺機器運行程序,安裝一個Linux(如Ubuntu x64),推薦硬件參數如下:
2.0+ GHZ X 8核
16GB 內存,推薦32GB
1 Gbps網卡
至少2GB可用磁盤空間,建議10GB以上
網絡參數:
從組織內的環境到阿里雲的帶寬應該大於數據在阿里雲端產生的速度,否則日誌無法實時消費。假設數據產生一般速度均勻,峯值在2倍左右,每天100TB原始日誌。5倍壓縮的場景下,推薦帶寬應該在4MB/s(32Mbps)左右。
使用(Python)
這裏我們描述用Python使用消費組進行編程。對於Java語言用法,可以參考這篇文章.
注意:本篇文章的代碼可能會更新,最新版本在這裏可以找到:Github樣例.
安裝
環境
強烈推薦PyPy3來運行本程序,而不是使用標準CPython解釋器。
日誌服務的Python SDK可以如下安裝:
pypy3 -m pip install aliyun-log-python-sdk -U
更多SLS Python SDK的使用手冊,可以參考這裏
程序配置
如下展示如何配置程序:
配置程序日誌文件,以便後續測試或者診斷可能的問題。
基本的日誌服務連接與消費組的配置選項。
消費組的一些高級選項(性能調參,不推薦修改)。
SIEM(Splunk)的相關參數與選項。
請仔細閱讀代碼中相關注釋並根據需要調整選項:
#encoding: utf8
import os
import logging
from logging.handlers import RotatingFileHandler
root = logging.getLogger()
handler = RotatingFileHandler("{0}_{1}.log".format(os.path.basename(file), current_process().pid), maxBytes=10010241024, backupCount=5)
handler.setFormatter(logging.Formatter(fmt='[%(asctime)s] - [%(threadName)s] - {%(module)s:%(funcName)s:%(lineno)d} %(levelname)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S'))
root.setLevel(logging.INFO)
root.addHandler(handler)
root.addHandler(logging.StreamHandler())
logger = logging.getLogger(name)
def get_option():
##########################
基本選項
##########################
# 從環境變量中加載SLS參數與選項
endpoint = os.environ.get('SLS_ENDPOINT', '')
accessKeyId = os.environ.get('SLS_AK_ID', '')
accessKey = os.environ.get('SLS_AK_KEY', '')
project = os.environ.get('SLS_PROJECT', '')
logstore = os.environ.get('SLS_LOGSTORE', '')
consumer_group = os.environ.get('SLS_CG', '')
# 消費的起點。這個參數在第一次跑程序的時候有效,後續再次運行將從上一次消費的保存點繼續。
# 可以使”begin“,”end“,或者特定的ISO時間格式。
cursor_start_time = "2018-12-26 0:0:0"
##########################
# 一些高級選項
##########################
# 一般不要修改消費者名,尤其是需要併發跑時
consumer_name = "{0}-{1}".format(consumer_group, current_process().pid)
# 心跳時長,當服務器在2倍時間內沒有收到特定Shard的心跳報告時,服務器會認爲對應消費者離線並重新調配任務。
# 所以當網絡不是特別好的時候,不要調整的特別小。
heartbeat_interval = 20
# 消費數據的最大間隔,如果數據生成的速度很快,並不需要調整這個參數。
data_fetch_interval = 1
# 構建一個消費組和消費者
option = LogHubConfig(endpoint, accessKeyId, accessKey, project, logstore, consumer_group, consumer_name,
cursor_position=CursorPosition.SPECIAL_TIMER_CURSOR,
cursor_start_time=cursor_start_time,
heartbeat_interval=heartbeat_interval,
data_fetch_interval=data_fetch_interval)
# Splunk選項
settings = {
"host": "10.1.2.3",
"port": 80,
"token": "a023nsdu123123123",
'https': False, # 可選, bool
'timeout': 120, # 可選, int
'ssl_verify': True, # 可選, bool
"sourcetype": "", # 可選, sourcetype
"index": "", # 可選, index
"source": "", # 可選, source
}
return option, settings數據消費與轉發
如下代碼展示如何從SLS拿到數據後轉發給Splunk。
from aliyun.log.consumer import *
from aliyun.log.pulllog_response import PullLogResponse
from multiprocessing import current_process
import time
import json
import socket
import requests
class SyncData(ConsumerProcessorBase):
"""
這個消費者從SLS消費數據併發送給Splunk
"""
def init(self, splunk_setting):
"""初始化並驗證Splunk連通性"""
super(SyncData, self).init()
assert splunk_setting, ValueError("You need to configure settings of remote target")
assert isinstance(splunk_setting, dict), ValueError("The settings should be dict to include necessary address and confidentials.")
self.option = splunk_setting
self.timeout = self.option.get("timeout", 120)
# 測試Splunk連通性
s = socket.socket()
s.settimeout(self.timeout)
s.connect((self.option["host"], self.option['port']))
self.r = requests.session()
self.r.max_redirects = 1
self.r.verify = self.option.get("ssl_verify", True)
self.r.headers['Authorization'] = "Splunk {}".format(self.option['token'])
self.url = "{0}://{1}:{2}/services/collector/event".format("http" if not self.option.get('https') else "https", self.option['host'], self.option['port'])
self.default_fields = {}
if self.option.get("sourcetype"):
self.default_fields['sourcetype'] = self.option.get("sourcetype")
if self.option.get("source"):
self.default_fields['source'] = self.option.get("source")
if self.option.get("index"):
self.default_fields['index'] = self.option.get("index")
def process(self, log_groups, check_point_tracker):
logs = PullLogResponse.loggroups_to_flattern_list(log_groups, time_as_str=True, decode_bytes=True)
logger.info("Get data from shard {0}, log count: {1}".format(self.shard_id, len(logs)))
for log in logs:
# 發送數據到Splunk
# 如下代碼只是一個樣例(注意:所有字符串都是unicode)
# Python2: {u"__time__": u"12312312", u"__topic__": u"topic", u"field1": u"value1", u"field2": u"value2"}
# Python3: {"__time__": "12312312", "__topic__": "topic", "field1": "value1", "field2": "value2"}
event = {}
event.update(self.default_fields)
if log.get(u"__topic__") == 'audit_log':
# suppose we only care about audit log
event['time'] = log[u'__time__']
event['fields'] = {}
del log['__time__']
event['fields'].update(log)
data = json.dumps(event, sort_keys=True)
try:
req = self.r.post(self.url, data=data, timeout=self.timeout)
req.raise_for_status()
except Exception as err:
logger.debug("Failed to connect to remote Splunk server ({0}). Exception: {1}", self.url, err)
# TODO: 根據需要,添加一些重試或者報告的邏輯
logger.info("Complete send data to remote")
self.save_checkpoint(check_point_tracker)主邏輯
如下代碼展示主程序控制邏輯:
def main():
option, settings = get_monitor_option()
logger.info("*** start to consume data...")
worker = ConsumerWorker(SyncData, option, args=(settings,) )
worker.start(join=True)if name == 'main':
main()
啓動
假設程序命名爲"sync_data.py",可以如下啓動:
export SLS_ENDPOINT=<Endpoint of your region>
export SLS_AK_ID=<YOUR AK ID>
export SLS_AK_KEY=<YOUR AK KEY>
export SLS_PROJECT=<SLS Project Name>
export SLS_LOGSTORE=<SLS Logstore Name>
export SLS_CG=<消費組名,可以簡單命名爲"syc_data">
pypy3 sync_data.py
限制與約束
每一個日誌庫(logstore)最多可以配置10個消費組,如果遇到錯誤ConsumerGroupQuotaExceed則表示遇到限制,建議在控制檯端刪除一些不用的消費組。
監測
在控制檯查看消費組狀態
通過雲監控查看消費組延遲,並配置報警
性能考慮
啓動多個消費者
基於消費組的程序可以直接啓動多次以便達到併發作用:
nohup pypy3 sync_data.py &
nohup pypy3 sync_data.py &
nohup pypy3 sync_data.py &
...
注意:
所有消費者使用了同一個消費組的名字和不同的消費者名字(因爲消費者名以進程ID爲後綴)。
因爲一個分區(Shard)只能被一個消費者消費,假設一個日誌庫有10個分區,那麼最多有10個消費者同時消費。
Https
如果服務入口(endpoint)配置爲https://前綴,如https://cn-beijing.log.aliyuncs.com,程序與SLS的連接將自動使用HTTPS加密。
服務器證書*.aliyuncs.com是GlobalSign簽發,默認大多數Linux/Windows的機器會自動信任此證書。如果某些特殊情況,機器不信任此證書,可以參考這裏下載並安裝此證書。
性能吞吐
基於測試,在沒有帶寬限制、接收端速率限制(如Splunk端)的情況下,以推進硬件用pypy3運行上述樣例,單個消費者佔用大約10%的單核CPU下可以消費達到5 MB/s原始日誌的速率。因此,理論上可以達到50 MB/s原始日誌每個CPU核,也就是每個CPU核每天可以消費4TB原始日誌。
注意: 這個數據依賴帶寬、硬件參數和SIEM接收端(如Splunk)是否能夠較快接收數據。
高可用性
消費組會將檢測點(check-point)保存在服務器端,當一個消費者停止,另外一個消費者將自動接管並從斷點繼續消費。
可以在不同機器上啓動消費者,這樣當一臺機器停止或者損壞的清下,其他機器上的消費者可以自動接管並從斷點進行消費。
理論上,爲了備用,也可以啓動大於shard數量的消費者。
更多參考
日誌服務Python消費組實戰(一):日誌服務與SIEM(如Splunk)集成實戰
日誌服務Python消費組實戰(二):實時日誌分發
日誌服務Python消費組實戰(三):實時跨域監測多日誌庫數據
本文Github樣例