




架構
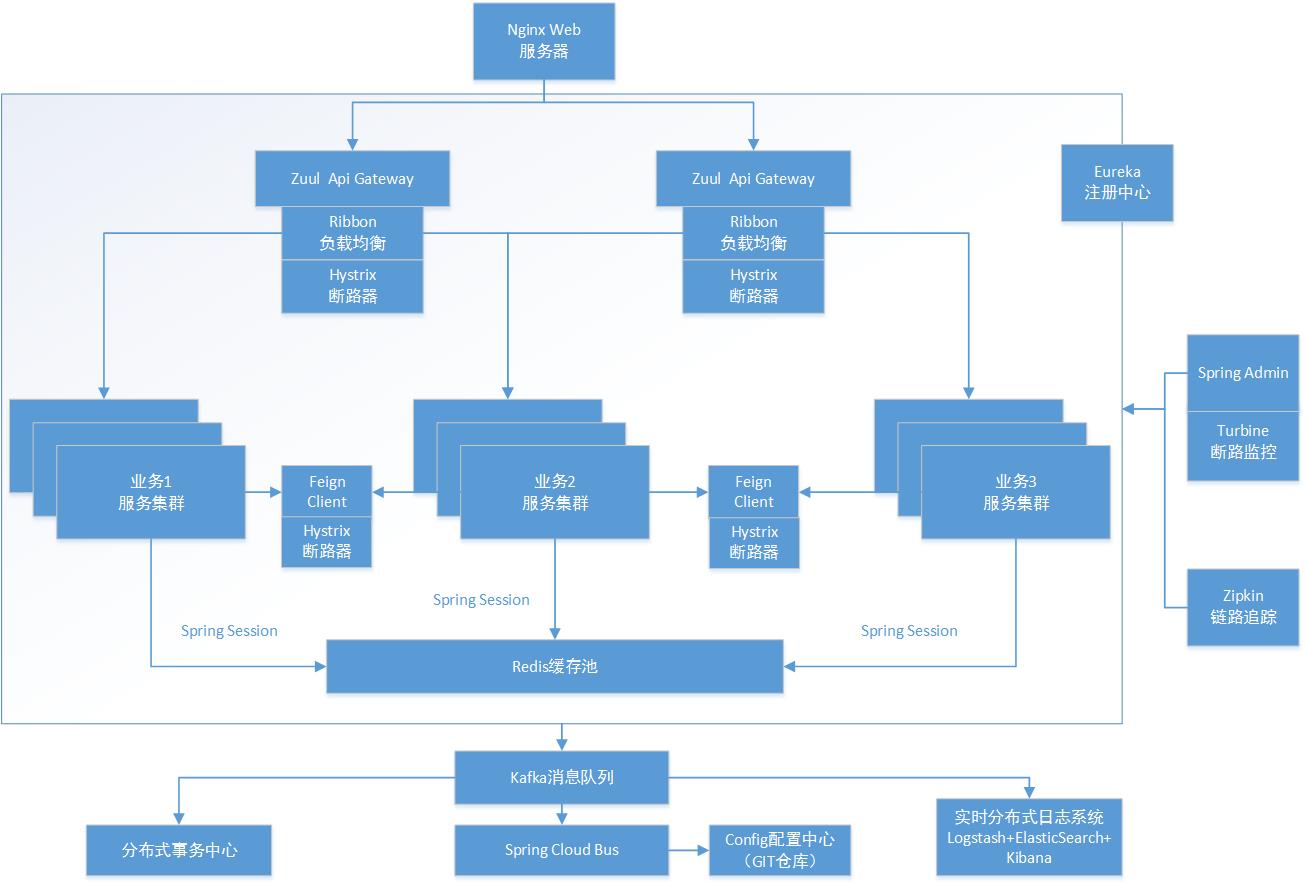
說明
針對這個架構圖我分層介紹一下:
1、是web服務器的選型,這個我選擇的是nginx+keepalived,haproxy也是一個選擇,但是haproxy在反向代理處理跨域訪問的時候問題很多。所以我們nginx有些地方做了keep-alive模式處理,減少了三次握手的次數,提高了連接效率。keepalived做nginx的負載,虛擬一個vip對外,兩個nginx做高可用,nginx本身反向代理zuul集羣。
2、api gateway,這裏的zuul很多人詬病,說是速度慢推薦直接用nginx,這裏我還是推薦使用zuul的,畢竟zuul含有攔截器和反向代理,在權限管理、單點登錄、用戶認證時候還是很有用的,而且zuul自帶ribbon負載均衡,如果你直接用nginx,還需要單獨做一個feign或者ribbon層,用來做業務集羣的負載層,畢竟直接把接口暴露給web服務器太危險了。這裏zuul帶有ribbon負載均衡和hystrix斷路器,直接反向代理serviceId就可以代理整個集羣了。
3、業務集羣,這一層我有些項目是分兩層的,就是上面加了一個負載層,下面是從service開始的,底層只是單純的接口,controller是單獨一層由feign實現,然後內部不同業務服務接口互調,直接調用controller層,只能說效果一般,多了一次tcp連接。所以我推薦合併起來,因爲做過spring cloud項目的都知道,feign是含有ribbon的,而zuul也含有ribbon,這樣的話zuul調用服務集羣,和服務集羣間接口的互調都是高可用的,保證了通訊的穩定性。Hystrix還是要有的,沒有斷路器很難實現服務降級,會出現大量請求發送到不可用的節點。當然service是可以改造的,如果改造成rpc方式,那服務之間互調又是另外一種情況了,那就要做成負載池和接口服務池的形式了,負載池調用接口池,接口池互相rpc調用,feign client只是通過實現接口達到了仿rpc的形式,不過速度表現還是不錯的。
4、redis緩存池,這個用來做session共享,分佈式系統session共享是一個大問題。同時呢,redis做二級緩存對降低整個服務的響應時間,並且減少數據庫的訪問次數是很有幫助的。當然redis cluster還是redis sentinel自己選擇。
5、eurake註冊中心這個高可用集羣,這裏有很多細節,比如多久刷新列表一次,多久監測心跳什麼的,都很重要。
6、spring admin,這個是很推薦的,這個功能很強大,可以集成turbine斷路器監控器,而且可以定義所有類的log等級,不用單獨去配置,還可以查看本地log日誌文件,監控不同服務的機器參數及性能,非常強大。它加上elk動態日誌收集系統,對於項目運維非常方便。
7、zipkin,這個有兩種方式,直接用它自己的功能界面查看方式,或者用stream流的方式,由elk動態日誌系統收集。但是我必須要說,這個對系統的性能損害非常大,因爲鏈路追蹤的時候會造成響應等待,而且等待時間非常長接近1秒,這在生產環境是不能忍受的,所以生產環境最好關掉,有問題調試的時候再打開。
8、消息隊列,這個必須的,分佈式系統不可能所有場景都滿足強一致性,這裏只能由消息隊列來作爲緩衝,這裏我用的是Kafka。
9、分佈式事物,我認爲這是分佈式最困難的,因爲不同的業務集羣都對應自己的數據庫,互相數據庫不是互通的,互相服務調用只能是相互接口,有些甚至是異地的,這樣造成的結果就是網絡延遲造成的請求等待,網絡抖動造成的數據丟失,這些都是很可怕的問題,所以必須要處理分佈式事物。我推薦的是利用消息隊列,採取二階段提交協議配合事物補償機制,具體的實現需要結合業務,這裏篇幅有限就不展開說了。
10、config配置中心,這是很有必要的,因爲服務太多配置文件太多,沒有這個很難運維。這個一般利用消息隊列建立一個spring cloud bus,由git存儲配置文件,利用bus總線動態更新配置文件信息。
11、實時分佈式日誌系統,logstash收集本地的log文件流,傳輸給elasticsearch,logstash有兩種方式,1、是每一臺機器啓動一個logstash服務,讀取本地的日誌文件,生成流傳給elasticsearch。2、logback引入logstash包,然後直接生產json流傳給一箇中心的logstash服務器,它再傳給elasticsearch。elasticsearch再將流傳給kibana,動態查看日誌,甚至zipkin的流也可以直接傳給elasticsearch。這個配合spring admin,一個查看動態日誌,一個查看本地日誌,同時還能遠程管理不同類的日誌級別,對集成和運維非常有利。
最後要說說,spring cloud的很多東西都比較精確,比如斷路器觸發時間、事物補償時間、http響應時間等,這些都需要好好的設計,而且可以優化的點非常多。比如:http通訊可以使用okhttp,jvm優化,nio模式,數據連接池等等,都可以很大的提高性能。
還有一個docker問題,很多人說不用docker就不算微服務。其實我個人意見,spring cloud本身就是微服務的,只需要jdk環境即可。編寫dockerfile也無非是集成jdk、添加jar包、執行jar而已,或者用docker compose,將多個不同服務的image組合run成容器而已。但是帶來的問題很多,比如通訊問題、服務器性能損耗問題、容器進程崩潰問題,當然如果你有一套成熟的基於k8s的容器管理平臺,這個是沒問題的,如果沒有可能就要斟酌了。而spring cloud本身就是微服務分佈式的架構,所以個人還是推薦直接機器部署的,當然好的DevOps工具將會方便很多。
請求過程
服務註冊到eureka
請求統一通過API網關(Zuul)來訪問內部服務.
網關接收到請求後,從註冊中心(Eureka)獲取可用服務
由Ribbon進行均衡負載後,分發到後端具體實例
微服務之間通過Feign進行通信處理業務
Hystrix負責處理服務超時熔斷
本文轉載自:https://blog.csdn.net/cyc3552637/article/details/80254490