




The x86 has Streaming SIMD Extensions(SSE) instruction sets. By processing 4 data items in parallel, theoretically SSE can improve performance to 400%. Advanced Vector Extensions (AVX) is 8-wide and can improve to 800% ! It is really amazing.
※ The vectorization instruction sets is called NEON in ARM architecture.
Theory aside, in practice, it is difficult for SSE to give us to over 300% without some careful coding. In some cases SSE might worsen the speed.
The figure below show what are vectorization instructions.
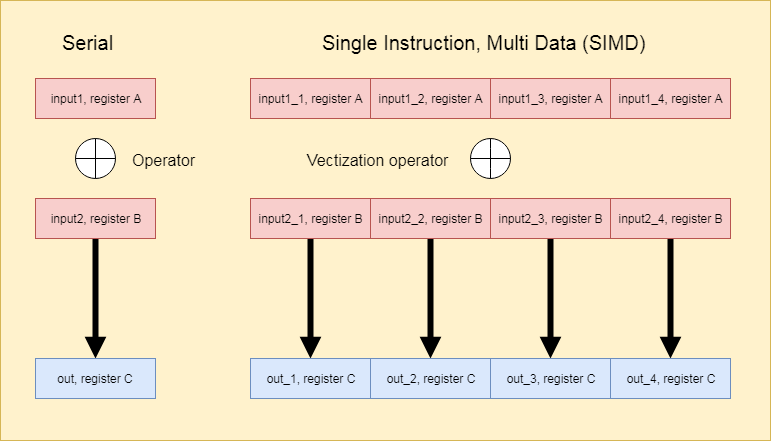
On the left is single instruction with single datum - basically standard instructions. One the right shows what is vectorization : single instruction-multi-data(SIMD). That is, the 4 data items are proceeded in the same time with one operation. It is the root cause why SSE can achieve speed up to 400% : the SSE registers contain 4 data item, and the instructions simultaneously operate the data.
Thus, to vectorize a processing, needs the two necessary conditions :
1. SIMD-wide register to load multi data.
2. Instructions to operate on SIMD-wide data.
If there is no vectorization instruction meeting the programmer requires, he needs to use a sequence of SIMD instructions to achieve the same goal. As this figure iluminates for dot-product:
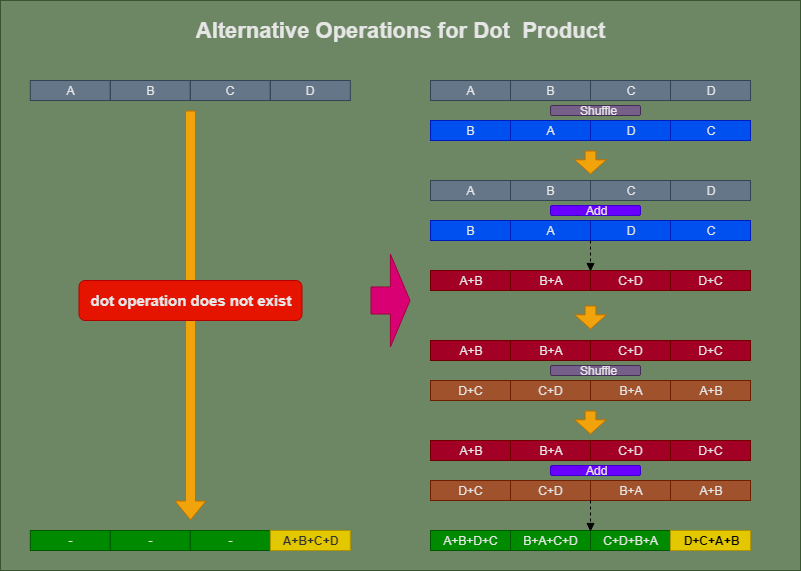
The sequence may be not short, and there must be some overhead operation unable to be vectorized (e.g. loop control, suffle etc). Therefore, the improvement to 400% is unreachable. By my experience, if we can improve to over 220%, the optimization could be called "nice work".
Of course, if the procedure is very simple, e.g. one-array multiple a constant, the improvement could be very closed to 400%.
The SSE registers, called xmm, are 128 bits. The xmm registers are able to contain integer types and float types. The AVX registers are 256 bit-wide, called ymm.

AVX looks like better, right ? Theoretically, Yes, AVX is the better choice, But : Not all CPUs support AVX instruction sets, (the CPUs lower than Pentium) ; And if the instruction sets do not directly support the operation you want, the longer data, the longer the sequence of operations be; Besides, current AVX instruction sets are not as diverse as SSE. Therefore, it is not definitely a procedure adopting AVX would be faster than SSE.
Ahead, I would like to show the simplest SSE code example.
The code sums two arrays serially.
float *p_src1, *p_src2, *p_dst;
int n;
:/*init p_src1 p_src2 and p_dst*/
n = 1000 * 10000;
#pragma loop(no_vector)
for (i = 0; i < n; i++)
p_dst[i] = p_src1[i] + p_src2[i];
The SSE version :
#include <xmmintrin.h>
:
:
float *p_src1, *p_src2, *p_dst;
int n, end;
int step_size;
n = 1000 * 10000;
:/*init p_src1 p_src2 and p_dst*/
step_size = sizeof(__m128) / sizeof(float);
end = n / step_size;
n /= step_size;
for (i = 0; i < end; i++) {
__m128 m128_tmp[3];
m128_tmp[0] = _mm_loadu_ps(p_src1 + i*step_size);
m128_tmp[1] = _mm_loadu_ps(p_src2 + i*step_size);
m128_tmp[2] = _mm_add_ps(m128_tmp[0], m128_tmp[1]);
_mm_storeu_ps(p_dst + i*step_size, m128_tmp[2]);
}/*for i end*/
for (i = end*step_size; i < n; i++)
p_dst[i] = p_src1[i] + p_src2[i];
I use those instructions:
_mm_loadu_ps : loading non-aligned 4-wide data from memory.
_mm_add_ps : 4-wide add.
_mm_storeu_ps : store 4-wide non-aligned data into memory.
In my environment, VS2015 on i5-4750 and windows 7, the result is:
100 ROUND :
Serial : 1820 ms
SSE : 1568 ms
It is a simple case, but why the improvement is not to 400%? It is because the processing is without branch and totally data-independent. The out of order engine in the CPU is able to bring its full effect in this case. Even so, the SSE version is better.
In the most case, the procedure must not be so simple : the effect of the out of order engine would be much less. Therefore, to exploit SSE instructions brings much more performance.
In addition, it's worth mentioning : There is some room in above SSE code to be optimized. For example, use _mm_load_ps/_mm_store_ps (with aligned memory, _aligned_malloc/_aligned_free) instead of _mm_loadu_ps/_mm_storeu_ps to improve memory accessing speed ; Or use moving pointers to avoid the computing of accessing address.
零. Optimization the serial code of convolution.
This post emphasizes programming optimization, hence, I do not want to discuss convolution algorithm optimization , e.g. separable convolution and so forth. I discuss the general form only.
The complete function for the general form of convolution is as below :
int ConvolutionSerialCPU(int width, int height, float *p_input,
int kernel_length, float *p_kernel,
float *p_output)
{
int i, j;
int kernel_radius;
if (0 == width || 0 == height)
return -1;
if (kernel_length > width || kernel_length > height)
{
return -2;
}/*if */
if (NULL == p_input
|| NULL == p_kernel
|| NULL == p_output)
{
return -3;
}
kernel_radius = kernel_length / 2;
for (j = 0; j < height; j++) {
for (i = 0; i < width; i++) {
int ii, jj;
float sum;
sum = 0;
for (jj = 0; jj < kernel_length; jj++) {
for (ii = 0; ii < kernel_length; ii++) {
int x, y;
x = i + ii - kernel_radius;
y = j + jj - kernel_radius;
if ((x < 0 || x >= width)
|| (y < 0 || y >= height))
{
continue;
}/*out of bound*/
sum += p_kernel[kernel_length*jj + ii]
* p_input[y*width + x];
}/*ii*/
}/*jj*/
p_output[j*width + i] = sum;
}/*for i*/
}/*for j*/
return 0;
}/*ConvolutionSerialCPU*/
Aware that the "if block" in the most inner loop is a performance killer due to branch mispredict:
if ((x < 0 || x >= width)
|| (y < 0 || y >= height))
{
continue;
}/*out of bound*/
The instruction pipelines in the CPU is optimized for sequential code. It has to be stopped and flushed while there is conditional-branch.
To avoid the branch I pad the source data, called "extension source":

Extend the input:
kernel_radius = kernel_length/2; //assume kernel_length is an odd number
extended_width = width + 2 * kernel_radius;
extended_height = height + 2 * kernel_radius;
p_extended_data = (float*)malloc(
extended_width*extended_height * sizeof(float));
for (j = 0; j < extended_height; j++) {
for (i = 0; i < extended_width; i++) {
if (i < kernel_radius || i >= (kernel_radius + width)
|| j < kernel_radius || j >= (kernel_radius + height)
)
{
p_extended_data[i + extended_width*j] = 0;
}
else
{
int ii, jj;
jj = j - kernel_radius;
ii = i - kernel_radius;
p_extended_data[i + extended_width*j]
= p_input_data[jj*width + ii];
}/*if */
}/*for j*/
}/*for i*/
And the convolution function to deal with the extended input becomes more simple:
extended_width = width + kernel_length - 1;
for (j = 0; j < height; j++) {
for (i = 0; i < width; i++) {
int ii, jj;
float sum;
sum = 0;
for (jj = 0; jj < kernel_length; jj++) {
for (ii = 0; ii < kernel_length; ii++) {
int x, y;
x = i + ii;
y = j + jj;
sum += p_kernel[kernel_length*jj + ii]
* p_extended_input[extended_width*y + x];
}/*for ii*/
}/*for jj*/
p_output[j*width + i] = sum;
}/*for i*/
}/*for j*/
For a 1200x1200 source data, and the kernel size is 15x15, 10 rounds, the run times are :
ConvolutionSerialCPU : 3056 ms
ConvolutionSerialExtensionCPU : 2696 ms
It is typical example of "trading space for time". The performance increases by 13.4%, and the side effect is wasting some memory to contain zero. But I think it worthwhile.
壹. Optimization for SSE 1 :
SSE 1 instruction set features the operation of single precision float points, so I adopt them to operate the"multiply then sum" procedure (which is inside the most inner loop). See the following figure:

It totally takes 4 instructions.
The corresponding code is :
#include <xmmintrin.h>
:
for (ii = 0; ii < steps; ii++) {
__m128 m_kernel, m_src;
__m128 m_temp0, m_temp1, m_temp2, m_temp3, m_temp4;
float temp_sum;
int x, y;
x = i + ii*step_size;
y = j + jj;
m_kernel = _mm_loadu_ps(
p_kernel + kernel_length*jj + ii*step_size);
m_src = _mm_loadu_ps(
p_extended_input + y*extended_width + x);
m_temp0 = _mm_mul_ps(m_kernel, m_src);
m_temp1 = _mm_movehl_ps(_mm_setzero_ps(), m_temp0);
m_temp2 = _mm_add_ps(m_temp0, m_temp1);
m_temp3 = _mm_shuffle_ps(m_temp2, _mm_setzero_ps(),
_MM_SHUFFLE(0, 0, 0, 1));
m_temp4 = _mm_add_ps(m_temp3, m_temp2);
temp_sum = _mm_cvtss_f32(m_temp4);
sum += temp_sum;
}/*for ii*/
Use the same test size and round, the run time is 1354 ms. Comparing with the serial extension version, it is improved to 199.7%.
If we scrutinize the code, we may find there are some places for improvement . For example, the address calculations are complicated and in the inner loop:
x = i + ii*step_size;
y = j + jj;
m_kernel = _mm_loadu_ps(
p_kernel + kernel_length*jj + ii*step_size);
m_src = _mm_loadu_ps(
p_extended_input + y*extended_width + x);
If we use the two pointers to store the current addresses for the source and kernel and use '+=' to advance. The corresponding code is:
int y;
y = j;
for (jj = 0; jj < kernel_length; jj++) {
float *p_mov_input;
float *p_mov_kernel;
p_mov_kernel = p_kernel + kernel_length*jj;
p_mov_input = p_extended_input + y*extended_width + i;
for (ii = 0; ii < steps; ii++) {
__m128 m_kernel, m_src;
__m128 m_temp0, m_temp1, m_temp2, m_temp3, m_temp4;
float temp_sum;
m_kernel = _mm_loadu_ps(p_mov_kernel);
m_src = _mm_loadu_ps(p_mov_input);
m_temp0 = _mm_mul_ps(m_kernel, m_src);
m_temp1 = _mm_movehl_ps(_mm_setzero_ps(), m_temp0);
m_temp2 = _mm_add_ps(m_temp0, m_temp1);
m_temp3 = _mm_shuffle_ps(m_temp2, _mm_setzero_ps(),
_MM_SHUFFLE(0, 0, 0, 1));
m_temp4 = _mm_add_ps(m_temp3, m_temp2);
temp_sum = _mm_cvtss_f32(m_temp4);
sum += temp_sum;
p_mov_kernel += step_size;
p_mov_input += step_size;
}/*for ii*/
The address computation has been reduced from two multiplication and two addition to an addition.
Use the same test size and round, the run time is 1211 ms. It is improved to 222.6% from serial code.
貳. Optimization for SSE 3.
SSE3 features horizontal operation, can we exploit them in the computing of sum? The procedure is as the below figure.
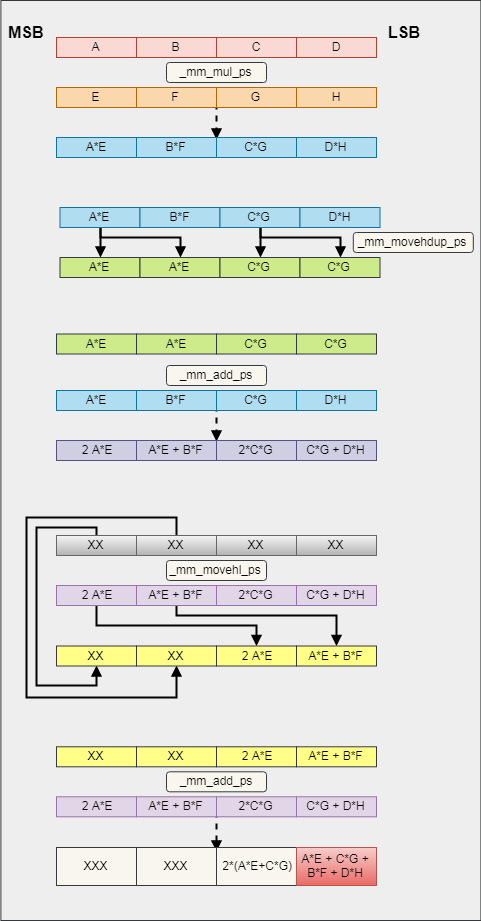
The code is :
#include <pmmintrin.h>
:
for (ii = 0; ii < steps; ii++) {
__m128 m_kernel, m_src, m_dst;
__m128 m_temp0, m_temp1, m_temp2, m_temp3;
float temp_sum;
m_kernel = _mm_loadu_ps(p_mov_kernel);
m_src = _mm_loadu_ps(p_mov_input);
m_temp0 = _mm_mul_ps(m_kernel, m_src);
/*
temp0 = a0, a1, a2, a3
*/
m_temp1 = _mm_movehdup_ps(m_temp0);
//m_temp1 = a1, a1, a3, a3
m_temp2 = _mm_add_ps(m_temp0, m_temp1);
//m_temp2 = a1+a0, a1+ a1, a2 + a3, a3 + a3,
m_temp3 = _mm_movehl_ps(_mm_setzero_ps(), m_temp2);
//m_temp3 = a2 + a3, a3 + a3, 0, 0
m_dst = _mm_add_ps(m_temp1, m_temp3);
temp_sum = _mm_cvtss_f32(m_dst);
sum += temp_sum;
p_mov_kernel += step_size;
p_mov_input += step_size;
}/*for ii*/
The run time is 1210 ms, it is almost as the same as previous version.
Here, I analyze why the performance is the same:
The numbers in side the braces are throughput in Haswell.
SSE version
_mm_mul_ps(0.5)
_mm_movehl_ps (1)
_mm_add_ps (1)
_mm_shuffle_ps (1)
_mm_add_ps (1)
total throughput : 4.5.
SSE3 is :
_mm_mul_ps(0.5)
_mm_movehdup_ps(1)
_mm_add_ps (1)
_mm_movehl_ps(1)
_mm_add_ps (1)
total throughput : 4.5.
Total throughout is the same. Thus, the performance is the same.
※ Counting throughput to predict performance is very inaccurate, it could only explain the very limited cases, not for forecasting the improvement.
※ You could refer to here to know the definition of latency and throughput.
Below is another SSE3 version, uses horizontal add instruction, but it gets a little worse (1311 ms, only 205.6% )
:
m_temp0 = _mm_mul_ps(m_kernel, m_src);
m_temp1 = _mm_hadd_ps(m_temp0, _mm_setzero_ps());
m_temp2 = _mm_hadd_ps(m_temp1, _mm_setzero_ps());
temp_sum = _mm_cvtss_f32(m_temp2);
:
參. Optimization for SSE4.
SSE4 directly support vector dot instruction, _mm_dp_ps. Therefore the procedure is extremely succinct:
m_temp1 = _mm_dp_ps(m_kernel, m_src, 0xf1);
temp_sum = _mm_cvtss_f32(m_temp1);
The run time is 1162 ms(232.0%), a little better than SSE version.
肆. Optimization for AVX
AVX register length is 256 bits, Hence, the variables about steps need to be amended :
int step_size_avx;
int steps_avx;
int remainder_avx;
int step_size_sse;
int steps_sse;
int remainder_sse;
:
step_size_avx = sizeof(__m256) / sizeof(float);
steps_avx = kernel_length / step_size_avx;
remainder_avx = kernel_length % step_size_avx;
step_size_sse = sizeof(__m128) / sizeof(float);
steps_sse = remainder_avx / step_size_sse;
remainder_sse = remainder_avx % step_size_sse;
if the remainder of 8 be greater or equal to 4, I use SSE4 procedure to deal with the data:
for (ii = 0; ii < steps_sse; ii++)
{
__m128 m_kernel, m_src;
__m128 m_temp0, m_temp1;
float temp_sum;
m_kernel = _mm_loadu_ps(p_mov_kernel);
m_src = _mm_loadu_ps(p_mov_input);
m_temp1 = _mm_dp_ps(m_kernel, m_src, 0xf1);
temp_sum = _mm_cvtss_f32(m_temp1);
sum += temp_sum;
}/*(kernel_length%8) /4 > 0*/
The procedure of major body,adopted AVX, is :
#include <immintrin.h>
:
_m256 m256_kernel, m256_src;
__m256 m256_temp0;
m256_kernel = _mm256_loadu_ps(p_mov_kernel);
m256_src = _mm256_loadu_ps(p_mov_input);
{
__m256 m256_temp1, m256_temp2, m256_temp3;
m256_temp1 = _mm256_dp_ps(m256_kernel, m256_src, 0xf1);
{
__m128 m128_low, m128_high;
__m128 m128_sum;
m128_low = _mm256_castps256_ps128(m256_temp1);
m128_high = _mm256_extractf128_ps(m256_temp1, 1);
m128_sum = _mm_add_ps(m128_low, m128_high);
temp_sum = _mm_cvtss_f32(m128_sum);
}
}
Note that _mm256_dp_ps derives the dot-products of two 4-packed floats, not derives the dot-product of 8-packed floats. There needs a procedure adds the two packs.
The run time is a little worse than SSE4 version, 1206 ms (223.5%)
Another AVX try :
#include <immintrin.h>
:
__m256 m256_kernel, m256_src;
__m256 m256_temp0;
__m128 m128_temp0, m128_temp1, m128_temp2, m128_temp3;
__m128 m128_temp4, m128_temp5, m128_temp6;
float temp_sum;
m256_kernel = _mm256_loadu_ps(p_mov_kernel);
m256_src = _mm256_loadu_ps(p_mov_input);
m256_temp0 = _mm256_mul_ps(m256_kernel, m256_src);
m128_temp0 = _mm256_castps256_ps128(m256_temp0);
m128_temp1 = _mm256_extractf128_ps(m256_temp0, 1);
m128_temp2 = _mm_add_ps(m128_temp0, m128_temp1);
#if(0) // crash !!
m128_temp3 = _mm_movehl_ps(_mm_setzero_ps(), m128_temp2);
#else
m128_temp3 = _mm_shuffle_ps(m128_temp2, _mm_setzero_ps(),
_MM_SHUFFLE(0, 0, 3, 2));
#endif
m128_temp4 = _mm_add_ps(m128_temp2, m128_temp3);
m128_temp5 = _mm_shuffle_ps(m128_temp4, _mm_setzero_ps(),
_MM_SHUFFLE(0, 0, 0, 1));
m128_temp6 = _mm_add_ps(m128_temp4, m128_temp5);
temp_sum = _mm_cvtss_f32(m128_temp6);
I use the AVX instructions to multiply two 8-packed floats, and separate the output as 2 SSE packets, then use the procedure of SSE to combination the two 128 bits packets.
※ The lines in #if() and #else are equivalent. But if I use the line containing _mm_movehl_ps instead of _mm_shuffle_ps in release mode VS2015 would show the instruction _mm_movehl_ps is illegal and crash and I do not know why.
The run time is 1042 ms, improved to 258.7%.
Below version is to use AVX horizontal add:
#include <immintrin.h>
:
__m256 m256_kernel, m256_src;
__m256 m256_temp0;
__m256 m256_temp1, m256_temp2;
float temp_sum;
m256_kernel = _mm256_loadu_ps(p_mov_kernel);
m256_src = _mm256_loadu_ps(p_mov_input);
m256_temp0 = _mm256_mul_ps(m256_kernel, m256_src);
m256_temp1 = _mm256_hadd_ps(m256_temp0, _mm256_setzero_ps());
m256_temp2 = _mm256_hadd_ps(m256_temp1, _mm256_setzero_ps());
{
__m128 m128_low, m128_high;
__m128 m128_sum;
m128_low = _mm256_castps256_ps128(m256_temp2);
m128_high = _mm256_extractf128_ps(m256_temp2, 1);
m128_sum = _mm_add_ps(m128_low, m128_high);
temp_sum = _mm_cvtss_f32(m128_sum);
}
The run time is 1071 ms, 251.7% .
伍. Benchmark:
All data are runs 10 times, the run time units is millisecond.
1000x1000
|
instruction\kernel |
9x9 |
15x15 |
21x21 |
31x31 |
|---|---|---|---|---|
|
Serial extension |
568 |
1929 |
3990 |
8815 |
|
SSE |
300 |
845 |
1611 |
3474 |
|
SSE3 shuffle |
292 |
852 |
1576 |
3506 |
|
SSE4 |
242 |
816 |
1429 |
3256 |
|
AVX shuffle |
206 |
727 |
1323 |
3058 |
2000x2000
|
instruction\kernel |
9x9 |
15x15 |
21x21 |
31x31 |
|---|---|---|---|---|
|
Serial extension |
2185 |
7691 |
15511 |
34821 |
|
SSE |
1150 |
3401 |
5927 |
13571 |
|
SSE3 shuffle |
1174 |
3400 |
5435 |
13572 |
|
SSE4 |
971 |
3248 |
4917 |
12549 |
|
AVX shuffle |
841 |
2896 |
4849 |
10864 |
4000x4000
|
instruction\kernel |
9x9 |
15x15 |
21x21 |
31x31 |
|---|---|---|---|---|
|
Serial extension |
8733 |
30899 |
62712 |
141096 |
|
SSE |
4674 |
13816 |
24655 |
54979 |
|
SSE3 shuffle |
4694 |
13629 |
23279 |
54079 |
|
SSE4 |
3953 |
12995 |
21922 |
49503 |
|
AVX shuffle |
3471 |
11525 |
19606 |
43701 |
Beware the more large the kernel size is, the more significant the improvement shows (AVX improved to over 300%). It is natural : the longer kernel size is, the less preparations relative to the computation of the sum is.
The key points to use the vectorization instructions to improve the performance, are :
零. Avoid your performance code with condition-branch, it slow the speed immensely.
一. Reduce the computing for memory addressing, the computing obviously affects the performance.
二. Try to use several procedure to achieve the same goal. Some instructions are sluggish, may be slower than a sequence of instructions.
The performance is not bad, right ? Yes, but the optimizing has not be ended : if kernel size is fixed, there are still room to be improved. About that, please refer to my next post.
Reference :
"Fastest way to do horizontal float vector sum on x86" discussed in stack overflow
Agner Fog's Optimization manuals