深度&&廣度優先算法
1.爬蟲系列 深度&廣度優先搜索 介紹
1.DFS(Depth-First-Search)深度優先搜索,是計算機術語,是一種在開發爬蟲早期使用較多的方法,
是搜索算法的一種。它的目的是要達到被搜索結構的葉結點(即那些不包含任何超鏈的HTML文件) 。
深度優先搜索沿着HTML文件上的超鏈走到不能再深入爲止,然後返回到這個HTML文件,再繼續選擇該HTML文件中的其他超鏈。
當不再有其他超鏈可選擇時,說明搜索已經結束。
深度優先搜索是一個遞歸的過程
2.深度優先和廣度優先搜索模型
廣度優先搜索算法(Breadth First Search),又稱爲"寬度優先搜索"或"橫向優先搜索",簡稱BFS
理解了深度優先搜索,也可以說是縱向,而廣度優先搜索可以理解爲橫向同步搜索。初始點開始後以層次的方式,從第一層的鄰接點開始,從第一層的1節點到2節點等。然後第二層的3節點到4節點5節點再三層的5節點到6節點7節點8節點等。
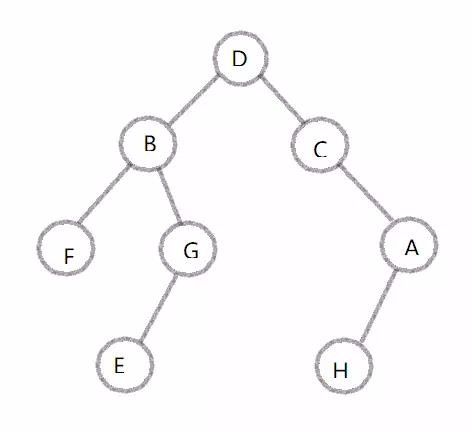
圖:
![深度&&廣度優先算法]()
# 深度優先:根左右 遍歷
#廣度優先: 層次遍歷,即一層一層遍歷
# 深度優先:根左右 遍歷
def depth_tree(tree_node):
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left) #遞歸遍歷
if tree_node._right is not None:
return depth_tree(tree_node._right) #遞歸遍歷
#廣度優先: 層次遍歷,即一層一層遍歷
def level_queue(root):
if root is None:
return
my_queue=[]
node = root
my_queue.append(node) # 根結點入隊列
while my_queue:
node = my_queue.pop(0) # 出隊列
print(node.elem) # 訪問結點
if node.lchild is not None:
my_queue.append(node.lchild) # 入隊列
if node.rchild is not None:
my_queue.append(node.rchild) # 入隊列
3.數據結構設計、遍歷代碼
3.1列表法
根據樹形圖來實現
# 簡述:列表裏包含三個元素:根結點、左結點、右結點
my_Tree = [
'D', # 根結點
['B',
['F',[],[]],
['G',['E',[],[]],[]]
], # 左子樹
['C',
[],
['A',['H',[],[]],[]]
] # 右子樹
]
# 列表操作函數
#POP(0) 函數用於一處列表中的一個元素(默認最後一個元素),並且返回該元素的值。
#insert()函數用於將制定對象插入列表的制定位置,沒有返回值。
# 深度優先: 根左右 遍歷 (遞歸實現)
def depth_tree(tree_node):
if tree_node:
print(tree_node[0])
#訪問左子樹
if tree_node[1]:
depth_tree(tree_node[1]) #遞歸遍歷
#訪問右子樹
if tree_node[2]:
depth_tree(tree_node[2]) #遞歸遍歷
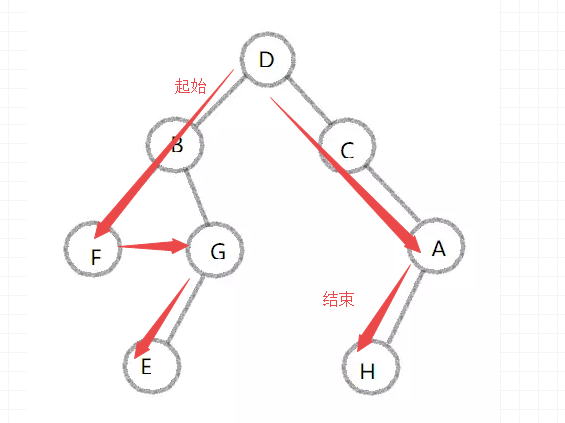
depth_tree(my_Tree)
執行結果:爲縱向搜索
D
B
F
G
E
C
A
H
廣度優先: 層次遍歷,一層一層遍歷(隊列實現)
def level_queue(root):
if not root:
return
my_queue = []
node = root
my_queue.append(node) # 根節點入隊列
while my_queue:
node = my_queue.pop(0) # 根節點出隊列
print(node[0]) #訪問節點
if node[1]:
my_queue.append(node[1])
if node[2]:
my_queue.append(node[2])
level_queue(my_Tree)
執行結果:結果爲橫向搜索
D
B
C
F
G
A
E
H
3.2 構建類節點法
# tree類,類變量root爲根節點,爲str類型
#類變量right/left 爲左右節點,爲tree型,默認爲空
class Tree:
root = ''
right = None
left = None
# 初始化類
def __init__(self,node):
self.root = node
def set_root(self,node):
self.root = node
def get_root(self):
return self.root
#初始化樹
#設置所有根節點
a = Tree('A')
b = Tree('B')
c = Tree('C')
d = Tree('D')
e = Tree('E')
f = Tree('F')
g = Tree('G')
h = Tree('H')
# 設置節點之間聯繫,生成樹
a.left = h
b.left = f
b.right = g
c.right = a
d.left = b
d.right = c
g.left = e
#深度優先:根左右 遍歷(遞歸實現)
def depth_tree(tree_node):
if tree_node is not None:
print(tree_node.root)
if tree_node.left is not None:
depth_tree(tree_node.left) # 遞歸遍歷
if tree_node.right is not None:
depth_tree(tree_node.right) # 遞歸遍歷
depth_tree(d) # 傳入根節點
執行結果:
D
B
F
G
E
C
A
H
讀取順序
![深度&&廣度優先算法]()
#廣度優先:層次遍歷,一層一層遍歷(隊列實現)
def level_queue(root):
if root is None:
return
my_queue = []
node = root
my_queue.append(node)# 根節點入隊列
while my_queue:
node = my_queue.pop(0) #出隊列
print(node.root) #訪問節點
if node.left is not None:
my_queue.append(node.left) #入隊列
if node.right is not None:
my_queue.append(node.right) #出隊列
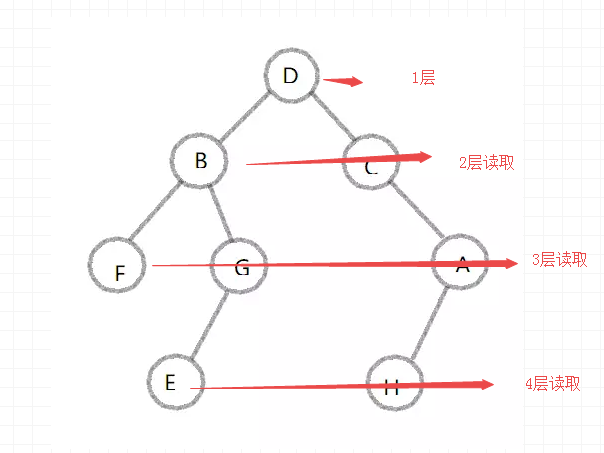
level_queue(d)
#result:
結果:
D
B
C
F
G
A
E
H
讀取順序
![深度&&廣度優先算法]()
做完深度優先和廣度優先策略算法後,返回來講,主要實現什麼?
這兩種策略是爬蟲系統抓取url的抓取策略,他們決定了爬取的url以什麼樣的順序隊列進行排列,深度優先就是一條路走到黑,廣度優先就是多條併發路線同時進行排列。