




後端服務性能壓測實踐
標籤: 性能 壓測 後端服務 壓測實踐
作者:王清培(Plen wang)
- 背景
- 環境檢測
- 壓力機及壓力工具檢測
- Linux openfiles limit 設置
- 排查周邊依賴
- 空接口壓測檢測
- 聚合報告中 throughput 計算
- 壓測及性能排查方法
- 關注各緯度 log
- Linux 常規命令
- 性能排查兩種方式(從上往下、從下往上)
- 總結
背景
最近大半年內有過兩次負責性能壓測的一些工作。一件事情做了一次可能還無法總結出一些東西,兩次過後還是能發現一些共性問題,所以總結下性能壓測的一般性實踐。但是問題肯定不止這些,還有更多深層次的問題等着發現,等我們遇到了在逐個解決再來總結分享。
做性能壓測的原因就不多說了,一般兩個時間點是必須要做的,大促前、新系統上線。壓測都是爲了系統在線上的處理能力和穩定性維持在一個標準範圍內,做到心中有數。
從整個行業來看,拋開一些大廠不說,全自動化的性能壓測環境還是比較少的,要想建設好一套全自動化的性能壓測環境起碼涉及到幾個問題,CI\CD、獨立、隔離的壓測環境,自動化壓測工具、日常壓測性能報警、性能報表分析、排查/解決性能問題流程等等。這樣才能將性能壓測常規化,一旦不是常規化性能壓測,就會有代碼、中間件配置滯後於生產環境的問題。時間一長,就等於要重新開始搭建、排查壓測環境。
如果性能壓測的環境是全自動化的,那麼就可以把性能壓測工作常規化變成研發過程中的一個例行的事項,執行起來效率就會非常高,壓測的時候也會比較輕鬆,好處也是比較明顯的。
但是大多數的時候我們還是需要從零開始進行性能壓測的工作。畢竟搭建這樣一套環境給企業帶來的成本也是巨大的。性能壓測對環境敏感,必須劃分獨立的部署、隔離單元,才能在後續的常規壓測流程中直觀的閱讀壓測報告。
題外話,如果有了自動化的壓測環境,也還是需要去了解下整個壓測環境的基本架構,畢竟壓測環境不是真實的生產環境,有些問題我們需要知道是正常的還是不正常的。
環境檢測
當我們需要進行性能壓測時首先要面對的問題就是環境問題,環境問題包含了常見的幾個點:
1.機器問題(實體機還是虛擬機、CPU、內存、網絡適配器進出口帶寬、硬盤大小,硬盤是否 SSD、內核基本參數配置)
2.網絡問題(是否有跨網段問題、網段是否隔離、如果有跨網段機器,是否能訪問、跨網段是否有帶寬限速)
3.中間件問題(程序裏所有依賴的中間件是否有部署,中間件的配置是否初始化、中間件 cluster 結構什麼樣、這些中間件是否都進行過性能壓測、壓測的緯度是什麼,是 benchmark 還是針對特定業務場景的壓測)
這些環境問題第一次排查的時候會有點累,但是掌握了一些方法、工具、流程之後剩下的也就是例行的事情,只不過人工參與的工作多點。
上面的問題裏,有些問題查看是比較簡單的,這裏就不介紹了,比如機器的基本配置等。有些配置只需要你推動下,走下相關流程回頭驗收下,比如網段隔離等,也還是比較簡單的。
比較說不清楚的是中間件問題,看上去都是能用的,但是就是壓不上去,這時候就需要你自己去進行簡單的壓測,比如 db 的單表插入、cache 的併發讀取、mq 的落地寫入等。這時候就涉及到一個問題,你需要對這些中間件都有一定深度的瞭解,要知道內在的運行機制,要不然出現異常情況排查起來確實很困難。
其實沒有人能熟悉市面上所有的中間件,每一箇中間件都很複雜,我們也不可能掌握一箇中間件的所有點,但是常用的一些我們是需要掌握的,至少知道個大概的內部結構,可以順藤摸瓜的排查問題。
但是事實上總有你不熟悉的,這個時候求助下大家的力量互相探討再自己摸索找點資料,我們沒遇到過也許別人遇到過,學技術其實就是這麼個過程。
壓力機及壓力工具檢測
既然做性能壓測就需要先對壓測機、壓力工具先進行了解,壓測工具我們主要有 locust、jmeter、ab,前兩者主要是壓測同事進行準出驗收測試使用的。
後兩者主要是用來提交壓測前的自檢使用,就是開發自己用來檢查和排錯使用的。這裏需要強調下 ab 其實是做基準測試的,不同於 jmeter 的作用。
需要知道壓力機是否和被壓測機器服務器在一個網段,且網段之間沒有任何帶寬限制。壓力機的壓測工具配置是否有瓶頸,一般如果是 jmeter 的話需要檢查 java 的一些基本配置。
但是一般如果壓力機是固定不變的,一直在使用的,那麼基本不會有什麼問題,因爲壓力機壓測同事一直維護者,反而是自己使用的壓測工具的參數要做好配置和檢測。
用 jmeter 壓測的時候,如果壓測時間過長,記得關掉 監聽器->圖形結果 面板,因爲那個渲染如果時間太長基本會假死,誤以爲會是內存的問題,其實是渲染問題。
在開發做基準壓測的時候有一個問題就是辦公網絡與壓測服務器的網絡之間的帶寬問題,壓力過大會導致辦公網絡出現問題。所以需要錯開時間段。
大致梳理好後,我們需要通過一些工具來查看下基本配置是否正常。比如,ethtool 網絡適配器信息、nload 流量情況等等,當然還有很多其他優秀的工具用來查看各項配置,這裏就不羅列了。
使用 ethtool 查看網絡適配器信息前需要先確定當前機器有幾個網絡適配器,最好的辦法是使用 ifconfig 找到你正在使用的網絡適配器。
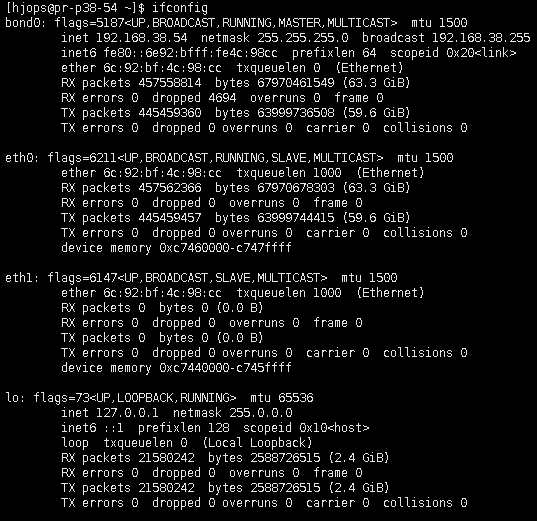
排除 127.0.0.1 的適配器外,還有三個適配器信息,只有第一個 bond0 纔是我們正在使用的,然後使用 ethtool 查看當前 bond0 的詳細適配器信息。重點關注下 speed 域,它表示當前網絡適配器的帶寬。
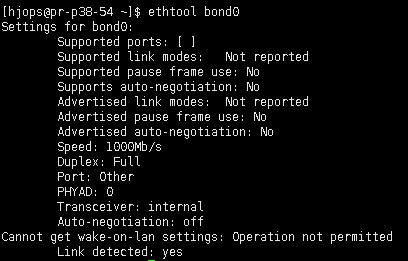
雖然網絡適配器可能配置的沒有問題,但是整個網絡是否沒問題還需要諮詢相關的運維同事進行排查下,中間還可能存在限速問題。
要確定網絡帶寬確實沒有問題,我們還需要一個實時的監控網絡流量工具,這裏我們使用nload來監控下進出口流量問題。

這個工具還是很不錯的,尤其是在壓測的過程中可以觀察流量的進出口情況,尤其是排查一些間隙抖動情況。
如果發現進口流量一直很正常,出口流量下來了有可能系統對外調用再放慢,有可能是下游調用 block,但是 request 線程池還未跑滿,也有可能內部是純 async ,request 線程根本不會跑滿,也有可能是壓測工具本身的壓力問題等等。但是我們至少知道是自己的系統對外調用這個邊界出了問題。
Linux openfiles limit 設置
工作環境中,一般情況下 linux 打開文件句柄數上限是不需要我們設置的,這些初始化的值運維同事一般是設置過的,而且是符合運維統一標準的。但是有時候關於最大連接數設置還要根據後端系統的使用場景來決定。
以防萬一我們還是需要自己檢查下是否符合當前系統的壓測要求。
在 Linux 中一切都是文件,socket 也是文件,所以需要查看下當前機器對於文件句柄打開的限制,查看 ulimit -a 的 open files 域,也可以直接查看ulimit -n 。
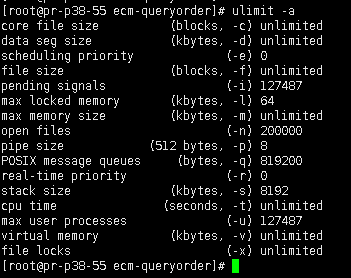
如果覺得配置的參數需要調整,可以通過編輯 /etc/security/limits.conf 配置文件。
排查周邊依賴
要想對一個服務進行壓測,就需要對這個服務周邊依賴進行一個排查,有可能你所依賴的服務不一定具備壓測條件。並不是每個系統的壓測都在一個時間段內,所以你在壓測的時候別人的服務也許並不需要壓測等等。
還有類似中間件的問題,比如,如果我們依賴中間件 cache ,那麼是否有本地一級 cache ,如果有的話也許對壓測環境的中間件 cache 依賴不是太大。如果我們依賴中間件 mq ,是不是在業務上可以斷開對 mq 的依賴,因爲我們畢竟不是對 mq 進行壓測。還有我們所依賴服務也不關心我們的壓測波動。
整理出來之後最好能畫個草圖,再重新 git branch -b 重新拉一個性能壓測的 branch 出來根據草圖進行調整代碼依賴。然後壓測的時候觀察流量和數據的走向,是否符合我們梳理之後的路線。
空接口壓測檢測
爲了快速驗證壓測服務一個簡單的辦法,就是通過壓測一個空接口,查看下整個網絡是否通暢,各個參數是否大體上正常。

一般在任何一個後端服務中,都有類似 __health_check 的 endpoint,方便起見可以直接找一個沒有任何下游依賴的接口進行壓測,這類接口主要是爲了驗證服務器的 online、offline__ 狀態。
如果當前服務沒有類似 __health_check__ 新建一個空接口也可以,而且實踐證明,一個服務在生產環境非常需要這麼一個接口,必要情況下可以幫助來排查調用鏈路問題。
《發佈!軟件的設計與部署》Jolt 大獎圖書 第17章 透明性 介紹了架構的透明性設計作用。
聚合報告中 throughput 計算
我們在用 jmeter 進行壓測的時候關於 聚合報告 中的 throughput 理解需要統一下。
正常情況下在使用 jmeter 壓測的時候會仔細觀察 throughput 這一列的變化情況,但是沒有搞清楚 thourghput 的計算原理的時候就會誤以爲是 tps/qps 下來了,其實有時候是整個遠程服務器根本就沒有 response 了。
throughput=samples/壓測時間
throughput(吞吐量) 是單位時間內的請求處理數,一般是按 second 計算,如果是壓測 write 類型的接口,那麼就是 tps 指標。如果壓測 read 類型的接口,那麼就是 qps 指標。這兩種類型的指標是完全不一樣的,我們不能搞混淆了。
200(throughput) tps=1000(write)/5(s)
1000(throughput) qps=2000(read)/2(s)
當我們發現 throughput 逐漸下來的時候要考慮一個時間的緯度。
也就是說我們的服務有可能已經不響應了,但是隨着壓測時間的積累,整個吞吐量的計算自然就在緩慢下滑,像這種刺尖問題是發現不了的。
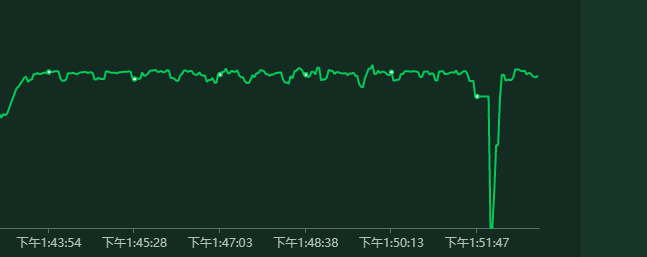
這一點用ui版本的 jmeter 尤其明顯,因爲它的表現方式就是在歡歡放慢。用 Linux 版本的 jmeter 還好點,因爲它的輸出打印是隔斷時間纔打印。
關於這個點沒有搞清楚非常影響我們對性能壓測的結果判斷。所以我們在壓測的時候一定要有監控報表,才能知道在整個壓測過程中服務器的各項指標是否出現過異常情況。
大多數的時候我們還會使用 apache ab 做下基本的壓測,主要是用來與 jmeter 對比下,兩個工具壓測的結果是否相差不大,主要用來糾偏一些性能虛高問題。
apache ab 與 jmeter 各有側重,ab 可以按固定請求數來壓,jmeter 可以按時間來壓,最後計算的時候需要注意兩者區別。ab 好像是沒有請求錯誤提示和中斷的,jmeter 是有錯誤提示,還有各個緯度斷言設置。
我們在使用壓測工具的時候,大致瞭解下工具的一些原理有助於準確的使用這款工具。
壓測及性能排查方法
在文章的前面部分講到了 排查周邊依賴 的環境檢查步驟。其實要想順利的進行壓測,這一步是必須要有的。經過這一步分析我們會有一個基本的 系統依賴 roadmap 。
基於這份 系統依賴 roadmap 我們將進行性能壓測和問題定位及性能優化。
合理的系統架構應該是上層依賴下層,在沒有確定下游系統性能的情況下,是沒辦法確定上游系統性能的瓶頸在哪裏。
所以壓測的順序應該儘可能的從下往上依次進行,這樣可以避免無意義的排查由於下游吞吐量不夠帶來的性能問題。越是下游系統性能要求越高,因爲上游系統的性能瓶頸直接依賴下游系統。
比如,商品系統的 v1/product/{productid} 前臺接口,吞吐量爲 qps 8000,那麼所有依賴這個接口的上游服務在這個代碼路徑上最高吞吐量瓶頸就是 8000 ,代碼路徑不管是 tps 還是 qps 都是一樣的瓶頸。
上層服務可以使用 async方式來提高 request 併發量,但是無法提高代碼路徑在 v1/product/{productid} 業務上的吞吐量。
我們不能將併發和吞吐量搞混淆了,系統能扛住多少併發不代表吞吐量就很高。可以有很多方式來提高併發量,threadpool 提高線程池大小 、socket 類c10k 、nio事件驅動,諸如此類方法。
關注各緯度 log
當在壓測的過程中定位性能問題的性價比較高的方法就是請求處理的log,請求處理時長log,對外接口調用時長log,這一般能定位大部分比較明顯的問題。當我們用到了一些中間件的時候都會輸出相應的執行log。
如下所示,在我們所使用的開發框架中支持了很多緯度的執行log,這在排查問題的時候就會非常方便。
slow.log 類型的慢日誌還是非常有必要記錄下來的,這不僅在壓測的時候需要,在生產上我們也是非常需要。
如果我們使用了各種中間件,那就需要輸出各種中間件的處理日誌,mq.log、cache.log、search.log 諸如此類。
除了這些 log 之外,我們還需要重點關注運行時的 gc log。
我們主要使用 Java 平臺,在壓測的時候關注 gc log 是正常的事。哪怕不是 Java 程序,類似基於 vm 的語言都需要關注 gc log 。根據 jvm gcer 配置的不同,輸出的日誌也不太一樣。
一般電商類的業務,以響應爲優先時 gc 主要是使用 cms+prenew ,關注 full gc 頻次,關注 cms 初始標記、併發標記、重新標記、併發清除 各個階段執行時間, gc 執行的 real time ,pernew 執行時的內存回收大小等 。
java gc 比較複雜涉及到的東西也非常多,對 gc log 的解讀也需要配合當前的內存各個代的大小及一系列 gc 的相關配置不同而不同。
《Java性能優化權威指南》 java之父gosling推薦,可以長期研究和學習。
Linux 常規命令
在壓測的過程中爲了能觀察到系統的各項資源消耗情況我們需要藉助各種工具來查看,主要包括網絡、內存、處理器、流量。
###netstat
主要是用來查看各種網絡相關信息。
比如,在壓測的過程中,通過 netstat wc 看下 tcp 連接數是否和服務器 threadpool 設置的匹配。
netstat -tnlp | grep ip | wc -l
如果我們服務器的 threadpool 設置的是50,那麼可以看到 tcp 連接數應該是50纔對。然後再通過統計 jstack 服務器的 request runing 狀態的線程數是不是>=50。
request 線程數的描述信息可能根據使用的 nio 框架的不同而不同。
還有使用頻率最高的查看系統啓動的端口狀態、tcp 連接狀態是 establelished 還是 listen 狀態。
netstat -tnlp
再配合 ps 命令查看系統啓動的狀態。這一般用來確定程序是否真的啓動了,如果啓動了是不是 listen 的端口與配置中指定的端口不一致。
ps aux | grep ecm-placeorder
netstat 命令很強大有很多功能,如果我們需要查看命令的其他功能,可以使用man netstat 翻看幫助文檔。
vmstat
主要用來監控虛擬處理器的運行隊列統計信息。
vmstat 1
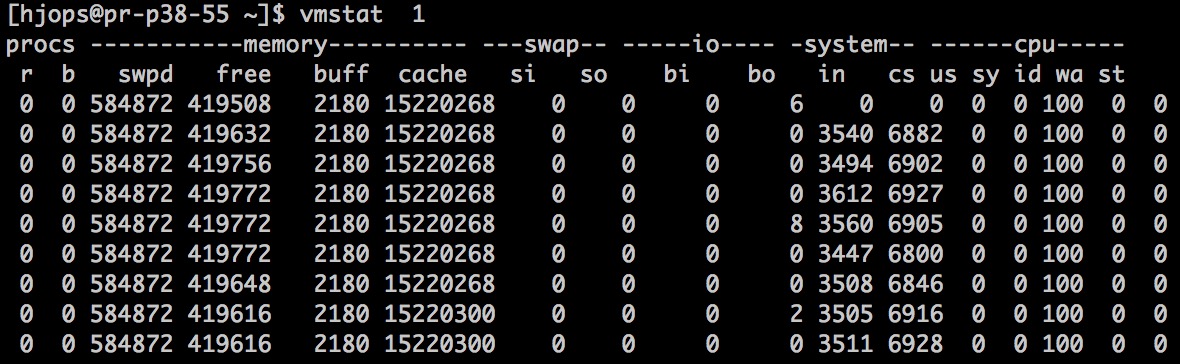
在壓測的時候可以每隔 1s 或 2s 打印一次,可以查看處理器負載是不是過高。procs 列 r 子列就是當前處理器的處理隊列,如果這個值超高當前 cpu core 數那麼處理器負載將過高。可以和下面將介紹的 top 命令搭配着監控。
同時此命令可以在處理器過高的時候,查看內存是否夠用是否出現大量的內存交換,換入換出的量多少 swap si 換入 swap so 換出。是否有非常高的上下文切換 system cs 每秒切換的次數,system us 用戶態運行時間是否很少。是否有非常高的 io wait 等等。
關於這個命令網上已經有很多優秀的文章講解,這裏就不浪費時間重複了。同樣可以使用 man vmstat 命令查看各種用法。
mpstat
主要用來監控多處理器統計信息
mpstat -P ALL 1
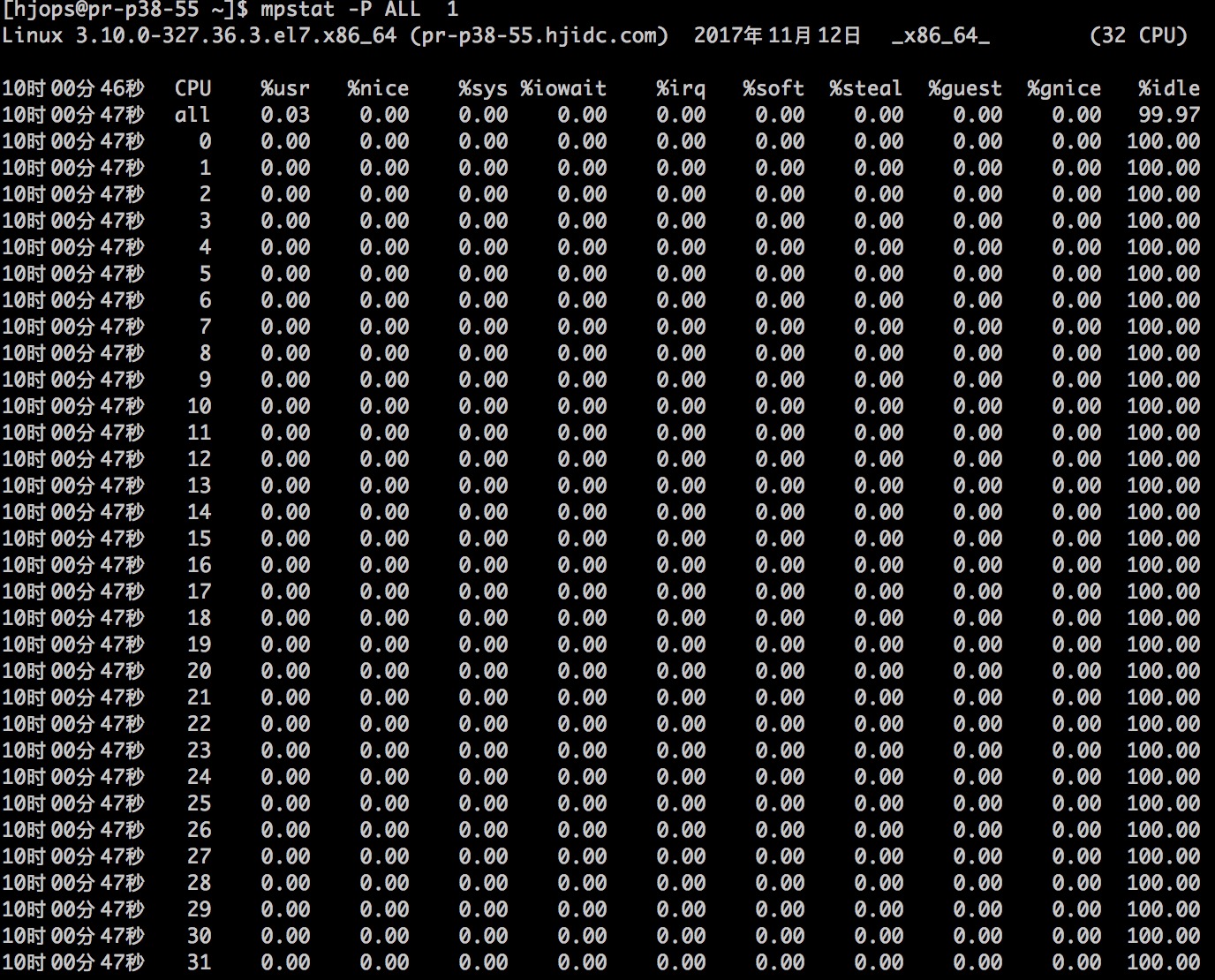
我這是一個 32 core 的壓測服務器,通過 mpstat 可以監控每一個虛擬處理器的負載情況。也可以查看總的處理器負載情況。
mpstat 1

可以看到 %idle 處於閒置狀態的 cpu 百分比,%user 用戶態任務佔用的 cpu 百分比,%sys 系統態內核佔用 cpu 百分比,%soft 軟中斷佔用 cpu 百分比,%nice 調整任務優先級佔用的 cpu 百分比等等。
iostat
主要用於監控io統計信息
iostat 1
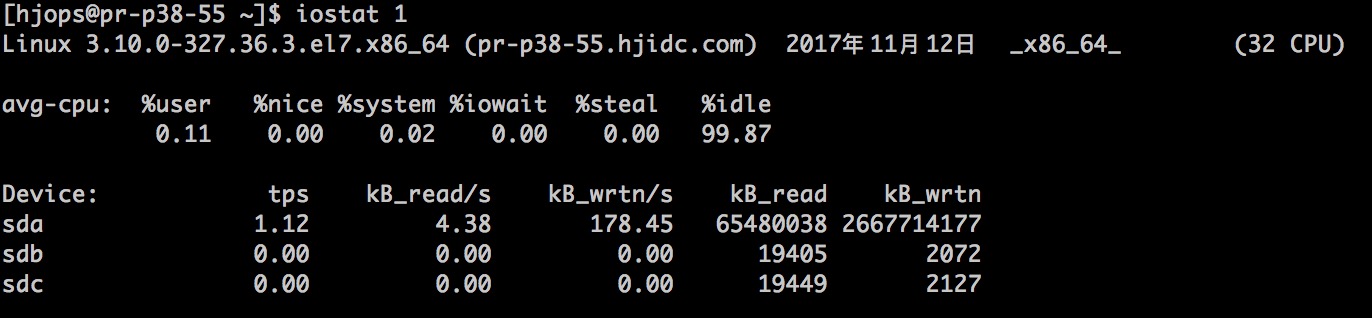
如果我們有大量的 io 操作的話通過 iostat 監控 io 的寫入和讀取的數據量,同時也能看到在 io 負載特別大的情況下 cpu 的平均負載情況。
top
監控整個系統的整體性能情況
top 命令是我們在日常情況下使用頻率最高的,可以對當前系統環境瞭如指掌。處理器 load 率情況,memory 消耗情況,哪個 task 消耗 cpu 、memory 最高。
top
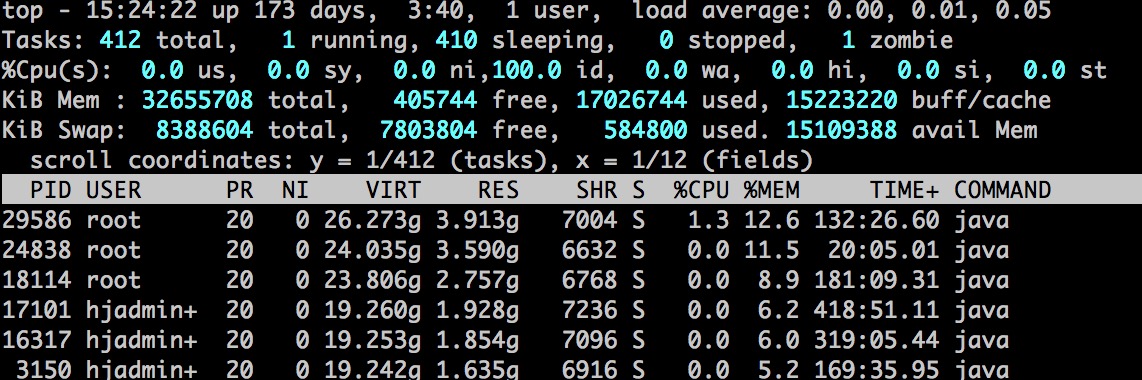
top 命令功能非常豐富,可以分別根據 %MEM、%CPU 排序。
load average 域表示 cpu load 率情況,後面三段分別表示最近1分鐘、5分鐘、15分鐘的平均 load 率。這個值不能大於當前 cpu core 數,如果大於說明 cpu load 已經嚴重過高。就要去查看是不是線程數設置的過高,還要考慮這些任務是不是處理時間太長。設置的線程數與任務所處理的時長有直接關係。
Tasks 域表示任務數情況,total 總的任務數,running 運行中的任務數,sleeping 休眠中的任務數,stopped 暫停中的任務數,zombie 殭屍狀態任務數。
Swap 域表示系統的交換區,壓測的時候關注 used 是否會持續升高,如果持續升高說明物理內存已經用完開始進行內存頁的交換。
free
查看當前系統的內存使用情況
free -m

total 總內存大小,used 已經分配的內存大小,free 當前可用的內存大小,shared 任務之間的共享內存大小,buffers 系統已經分配但是還未使用的,用來存放文件 matedata 元數據內存大小,cached 系統已經分配但是還未使用的,用來存放文件的內容數據的內存大小。
-/+buffer/cache
used 要減去 buffers/cached ,也就是說並沒有用掉這麼多內存,而是有一部分內存用在了 buffers/cached 裏。
free 要加上 buffers/cached ,也就是說還有 buffers/cached 空餘內存需要加上。
Swap 交換區統計,total 交換區總大小,used 已經使用的交換區大小,free 交換區可用大小。只需要關注 used 已經使用的交換區大小,如果這裏有佔用說明內存已經到瓶頸。
《深入理解LINUX內核》、《LINUX內核設計與實現》可以放在手邊作爲參考手冊遇到問題翻翻。
性能排查兩種方式(從上往下、從下往上)
當系統出現性能問題的時候可以從兩個層面來排查問題,從上往下、從下網上,也可以綜合運用這兩種方法,壓測的時候可以同時查看這兩個緯度的信息。
一邊打開 top 、free 觀察 cpu 、memory 的系統級別的消耗情況,同時一邊在通過 jstack 、jstat 之類的工具查看應用程序運行時的內部狀態來綜合定位。
總結
本篇文章主要還是從拋磚引玉的角度出發,整理下我們在做一般性能壓測的時候出現的常規問題及排查方法和處理流程,並沒有多麼高深的技術點。
性能問題一旦出現也不會是個簡單的問題,都需要花費很多精力來排查問題,運用各種工具、命令來逐步排查,而這些工具和命令所輸出的信息都是系統底層原理,需要逐一去理解和實驗的,並沒有一個銀彈能解決所有問題。