




點擊鏈接加入羣【悅分享測試聯盟】:https://jq.qq.com/?_wv=1027&k=5DiePik
摘要
本文主要介紹瞭如何利用Kafka自帶的性能測試腳本及Kafka Manager測試Kafka的性能,以及如何使用Kafka Manager監控Kafka的工作狀態,最後給出了Kafka的性能測試報告。
性能測試及集羣監控工具
Kafka提供了非常多有用的工具,如Kafka設計解析(三)- Kafka High Availability (下)中提到的運維類工具——Partition Reassign Tool,Preferred Replica Leader Election Tool,Replica Verification Tool,State Change Log Merge Tool。本文將介紹Kafka提供的性能測試工具,Metrics報告工具及Yahoo開源的Kafka Manager。
Kafka性能測試腳本
$KAFKA_HOME/bin/kafka-producer-perf-test.sh該腳本被設計用於測試Kafka Producer的性能,主要輸出4項指標,總共發送消息量(以MB爲單位),每秒發送消息量(MB/second),發送消息總數,每秒發送消息數(records/second)。除了將測試結果輸出到標準輸出外,該腳本還提供CSV Reporter,即將結果以CSV文件的形式存儲,便於在其它分析工具中使用該測試結果$KAFKA_HOME/bin/kafka-consumer-perf-test.sh該腳本用於測試Kafka Consumer的性能,測試指標與Producer性能測試腳本一樣
Kafka Metrics
Kafka使用Yammer Metrics來報告服務端和客戶端的Metric信息。Yammer Metrics 3.1.0提供6種形式的Metrics收集——Meters,Gauges,Counters,Histograms,Timers,Health Checks。與此同時,Yammer Metrics將Metric的收集與報告(或者說發佈)分離,可以根據需要自由組合。目前它支持的Reporter有Console Reporter,JMX Reporter,HTTP Reporter,CSV Reporter,SLF4J Reporter,Ganglia Reporter,Graphite Reporter。因此,Kafka也支持通過以上幾種Reporter輸出其Metrics信息。
使用JConsole查看單服務器Metrics
使用JConsole通過JMX,是在不安裝其它工具(既然已經安裝了Kafka,就肯定安裝了Java,而JConsole是Java自帶的工具)的情況下查看Kafka服務器Metrics的最簡單最方便的方法之一。
首先必須通過爲環境變量JMX_PORT設置有效值來啓用Kafka的JMX Reporter。如export JMX_PORT=19797。然後即可使用JConsole通過上面設置的端口來訪問某一臺Kafka服務器來查看其Metrics信息,如下圖所示。
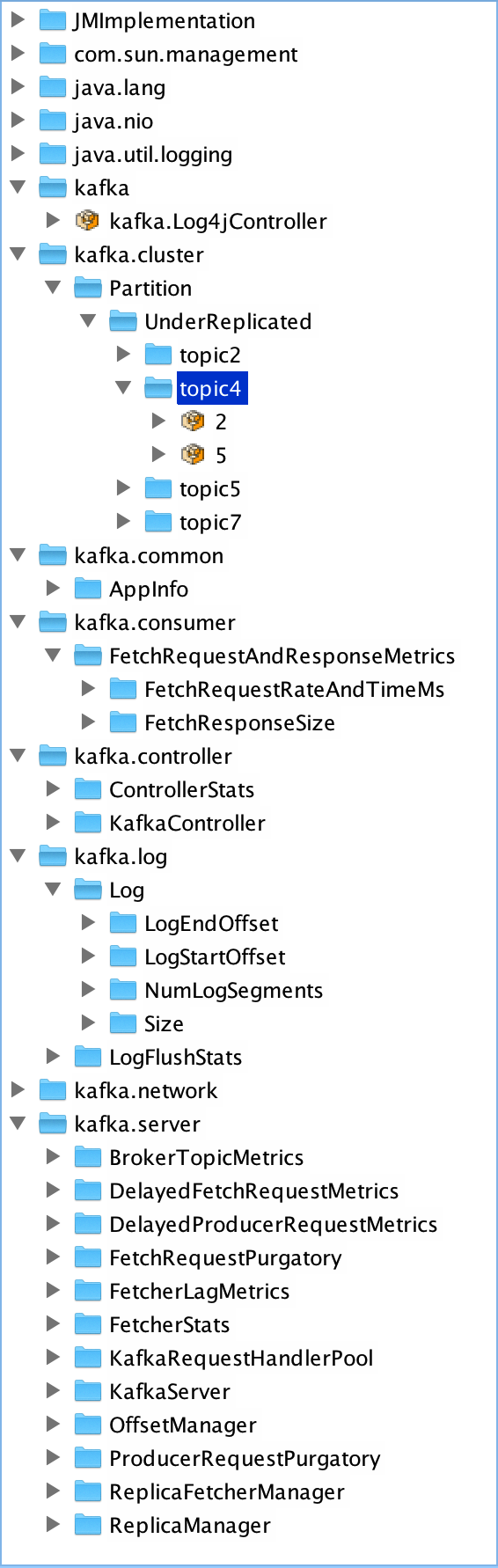
使用JConsole的一個好處是不用安裝額外的工具,缺點很明顯,數據展示不夠直觀,數據組織形式不友好,更重要的是不能同時監控整個集羣的Metrics。在上圖中,在kafka.cluster->Partition->UnderReplicated->topic4下,只有2和5兩個節點,這並非因爲topic4只有這兩個Partition的數據是處於複製狀態的。事實上,topic4在該Broker上只有這2個Partition,其它Partition在其它Broker上,所以通過該服務器的JMX Reporter只看到了這兩個Partition。
通過Kafka Manager查看整個集羣的Metrics
Kafka Manager是Yahoo開源的Kafka管理工具。它支持如下功能
管理多個集羣
方便查看集羣狀態
執行preferred replica election
批量爲多個Topic生成並執行Partition分配方案
創建Topic
刪除Topic(只支持0.8.2及以上版本,同時要求在Broker中將
delete.topic.enable設置爲true)爲已有Topic添加Partition
更新Topic配置
在Broker JMX Reporter開啓的前提下,輪詢Broker級別和Topic級別的Metrics
監控Consumer Group及其消費狀態
支持添加和查看LogKafka
安裝好Kafka Manager後,添加Cluster非常方便,只需指明該Cluster所使用的Zookeeper列表並指明Kafka版本即可,如下圖所示。
這裏要注意,此處添加Cluster是指添加一個已有的Kafka集羣進入監控列表,而非通過Kafka Manager部署一個新的Kafka Cluster,這一點與Cloudera Manager不同。
Kafka Benchmark
Kafka的一個核心特性是高吞吐率,因此本文的測試重點是Kafka的吞吐率。
本文的測試共使用6檯安裝Red Hat 6.6的虛擬機,3臺作爲Broker,另外3臺作爲Producer或者Consumer。每臺虛擬機配置如下
CPU:8 vCPU, Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz,2 Sockets,4 Cores per socket,1 Thread per core
內存:16 GB
磁盤:500 GB
開啓Kafka JMX Reporter並使用19797端口,利用Kafka-Manager的JMX polling功能監控性能測試過程中的吞吐率。
本文主要測試如下四種場景,測試的指標主要是每秒多少兆字節數據,每秒多少條消息。
Producer Only
這組測試不使用任何Consumer,只啓動Broker和Producer。
Producer Number VS. Throughput
實驗條件:3個Broker,1個Topic,6個Partition,無Replication,異步模式,消息Payload爲100字節
測試項目:分別測試1,2,3個Producer時的吞吐量
測試目標:如Kafka設計解析(一)- Kafka背景及架構介紹所介紹,多個Producer可同時向同一個Topic發送數據,在Broker負載飽和前,理論上Producer數量越多,集羣每秒收到的消息量越大,並且呈線性增漲。本實驗主要驗證該特性。同時作爲性能測試,本實驗還將監控測試過程中單個Broker的CPU和內存使用情況
測試結果:使用不同個數Producer時的總吞吐率如下圖所示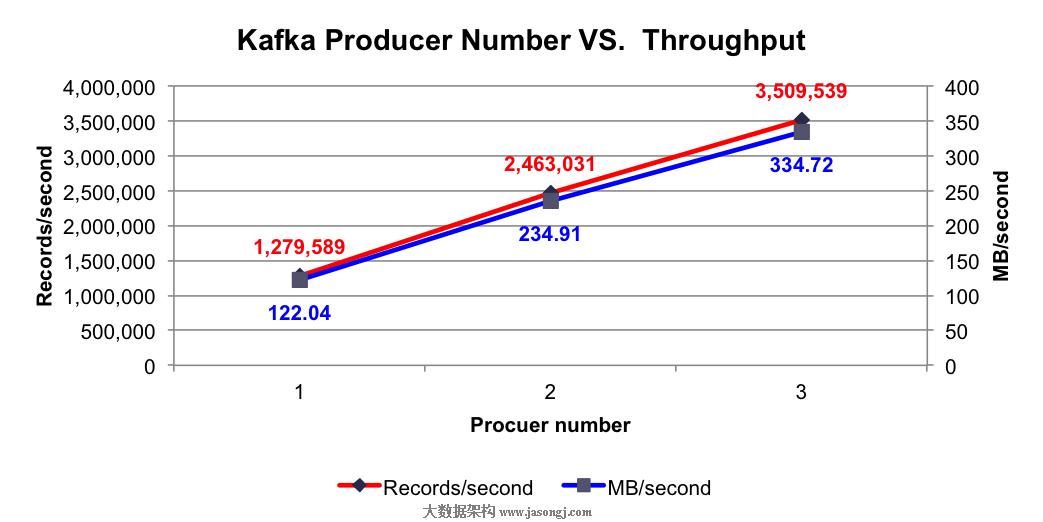
由上圖可看出,單個Producer每秒可成功發送約128萬條Payload爲100字節的消息,並且隨着Producer個數的提升,每秒總共發送的消息量線性提升,符合之前的分析。
性能測試過程中,Broker的CPU和內存使用情況如下圖所示。
由上圖可知,在每秒接收約117萬條消息(3個Producer總共每秒發送350萬條消息,平均每個Broker每秒接收約117萬條)的情況下,一個Broker的CPU使用量約爲248%,內存使用量爲601 MB。
Message Size VS. Throughput
實驗條件:3個Broker,1個Topic,6個Partition,無Replication,異步模式,3個Producer
測試項目:分別測試消息長度爲10,20,40,60,80,100,150,200,400,800,1000,2000,5000,10000字節時的集羣總吞吐量
測試結果:不同消息長度時的集羣總吞吐率如下圖所示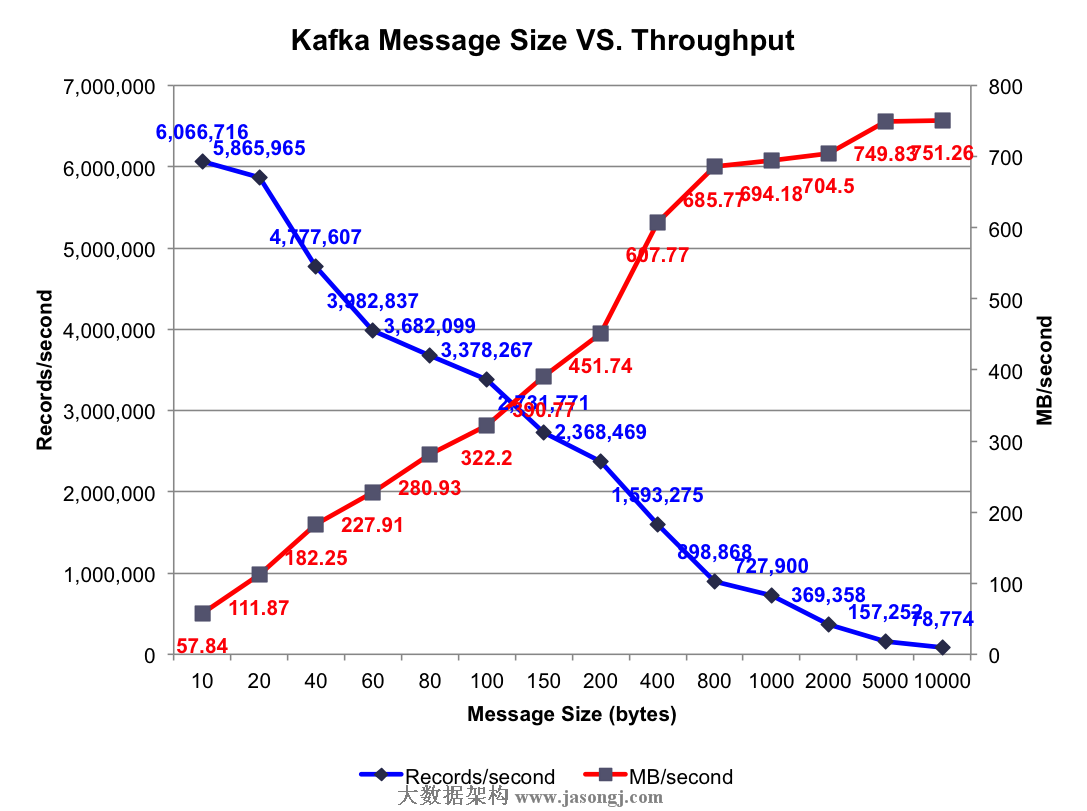
由上圖可知,消息越長,每秒所能發送的消息數越少,而每秒所能發送的消息的量(MB)越大。另外,每條消息除了Payload外,還包含其它Metadata,所以每秒所發送的消息量比每秒發送的消息數乘以100字節大,而Payload越大,這些Metadata佔比越小,同時發送時的批量發送的消息體積越大,越容易得到更高的每秒消息量(MB/s)。其它測試中使用的Payload爲100字節,之所以使用這種短消息(相對短)只是爲了測試相對比較差的情況下的Kafka吞吐率。
Partition Number VS. Throughput
實驗條件:3個Broker,1個Topic,無Replication,異步模式,3個Producer,消息Payload爲100字節
測試項目:分別測試1到9個Partition時的吞吐量
測試結果:不同Partition數量時的集羣總吞吐率如下圖所示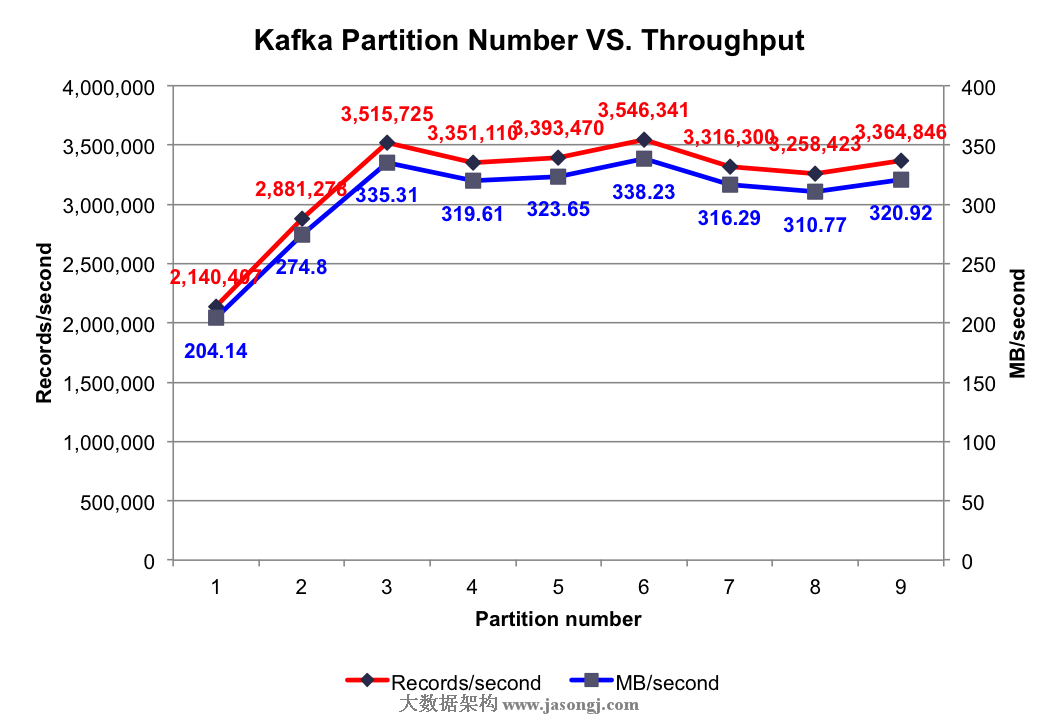
由上圖可知,當Partition數量小於Broker個數(3個)時,Partition數量越大,吞吐率越高,且呈線性提升。本文所有實驗中,只啓動3個Broker,而一個Partition只能存在於1個Broker上(不考慮Replication。即使有Replication,也只有其Leader接受讀寫請求),故當某個Topic只包含1個Partition時,實際只有1個Broker在爲該Topic工作。如之前文章所講,Kafka會將所有Partition均勻分佈到所有Broker上,所以當只有2個Partition時,會有2個Broker爲該Topic服務。3個Partition時同理會有3個Broker爲該Topic服務。換言之,Partition數量小於等於3個時,越多的Partition代表越多的Broker爲該Topic服務。如前幾篇文章所述,不同Broker上的數據並行插入,這就解釋了當Partition數量小於等於3個時,吞吐率隨Partition數量的增加線性提升。
當Partition數量多於Broker個數時,總吞吐量並未有所提升,甚至還有所下降。可能的原因是,當Partition數量爲4和5時,不同Broker上的Partition數量不同,而Producer會將數據均勻發送到各Partition上,這就造成各Broker的負載不同,不能最大化集羣吞吐量。而上圖中當Partition數量爲Broker數量整數倍時吞吐量明顯比其它情況高,也證實了這一點。
Replica Number VS. Throughput
實驗條件:3個Broker,1個Topic,6個Partition,異步模式,3個Producer,消息Payload爲100字節
測試項目:分別測試1到3個Replica時的吞吐率
測試結果:如下圖所示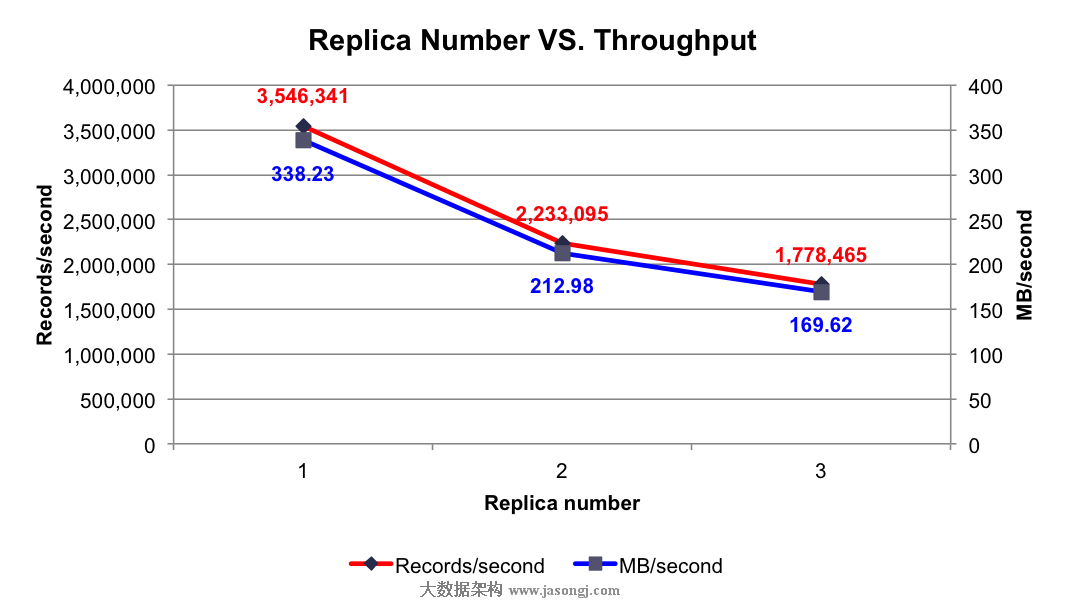
由上圖可知,隨着Replica數量的增加,吞吐率隨之下降。但吞吐率的下降並非線性下降,因爲多個Follower的數據複製是並行進行的,而非串行進行。
Consumer Only
實驗條件:3個Broker,1個Topic,6個Partition,無Replication,異步模式,消息Payload爲100字節
測試項目:分別測試1到3個Consumer時的集羣總吞吐率
測試結果:在集羣中已有大量消息的情況下,使用1到3個Consumer時的集羣總吞吐量如下圖所示
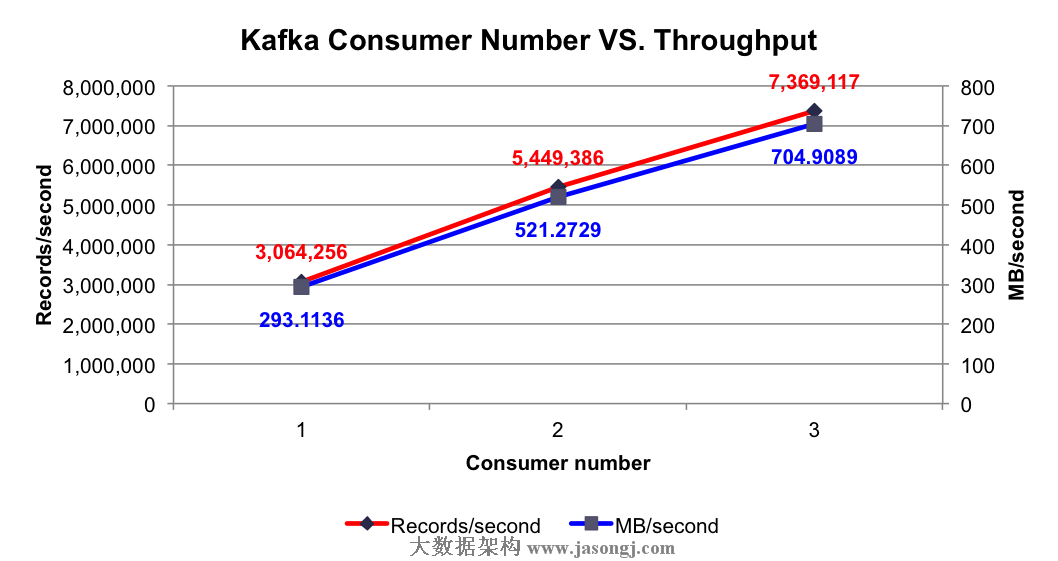
由上圖可知,單個Consumer每秒可消費306萬條消息,該數量遠大於單個Producer每秒可消費的消息數量,這保證了在合理的配置下,消息可被及時處理。並且隨着Consumer數量的增加,集羣總吞吐量線性增加。
根據Kafka設計解析(四)- Kafka Consumer設計解析所述,多Consumer消費消息時以Partition爲分配單位,當只有1個Consumer時,該Consumer需要同時從6個Partition拉取消息,該Consumer所在機器的I/O成爲整個消費過程的瓶頸,而當Consumer個數增加至2個至3個時,多個Consumer同時從集羣拉取消息,充分利用了集羣的吞吐率。
Producer Consumer pair
實驗條件:3個Broker,1個Topic,6個Partition,無Replication,異步模式,消息Payload爲100字節
測試項目:測試1個Producer和1個Consumer同時工作時Consumer所能消費到的消息量
測試結果:1,215,613 records/second