




ZooKeeper 是 Apache 的一個頂級項目,爲分佈式應用提供高效、高可用的分佈式協調服務,提供了諸如數據發佈/訂閱、負載均衡、命名服務、分佈式協調/通知和分佈式鎖等分佈式基礎服務。由於 ZooKeeper 便捷的使用方式、卓越的性能和良好的穩定性,被廣泛地應用於諸如 Hadoop、HBase、Kafka 和 Dubbo 等大型分佈式系統中。
歡迎學Java和大數據的朋友們加入java架構交流: 855835163
羣內提供免費的架構資料還有:Java工程化、高性能及分佈式、高性能、深入淺出。高架構。性能調優、Spring,MyBatis,Netty源碼分析和大數據等多個知識點高級進階乾貨的免費直播講解 可以進來一起學習交流哦
本文的目標讀者是對 ZooKeeper 有一定了解的技術人員,將從 ZooKeeper 運行模式、集羣組成、容災和水平擴容四方面逐步深入,最終構建出高可用的 ZooKeeper 集羣。
一、運行模式
Zookeeper 有三種運行模式:單機模式、僞集羣模式和集羣模式。
1.1 單機模式
這種模式一般適用於開發測試環境,一方面我們沒有那麼多機器資源,另外就是平時的開發調試並不需要極好的穩定性。
在 Linux 環境下運行單機模式需要執行以下步驟:
-
準備 Java 運行環境
安裝 Java 1.6 或更高版本的 JDK,並配置好 Java 相關的環境變量 $JAVA_HOME 。 -
下載 ZooKeeper 安裝包
下載地址:http://zookeeper.apache.org/releases.html。選擇最新的 stable 版本並解壓到指定目錄,我們用 $ZK_HOME 表示該目錄。 - 配置 zoo.cfg
首次使用 ZooKeeper,需要將 $ZK_HOME 下的 zoo_sample.cfg 文件重命名爲 zoo.cfg,並進行以下配置
tickTime=2000 ##Zookeeper最小時間單元,單位毫秒(ms),默認值爲3000
dataDir=/var/lib/zookeeper ##Zookeeper服務器存儲快照文件的目錄,必須配置
dataLogDir=/var/lib/log ##Zookeeper服務器存儲事務日誌的目錄,默認爲dataDir
clientPort=2181 ##服務器對外服務端口,一般設置爲2181
initLimit=5 ##Leader服務器等待Follower啓動並完成數據同步的時間,默認值10,表示tickTime的10倍
syncLimit=2 ##Leader服務器和Follower之間進行心跳檢測的最大延時時間,默認值5,表示tickTime的5倍
- 啓動服務
使用 $ZK_HOME/bin 目錄下的 zkServer.sh 腳本進行服務的啓動。
1.2 集羣模式
一個 ZooKeeper 集羣通常由一組機器組成,一般 3 臺以上就可以組成一個可用的 ZooKeeper 集羣了。
組成 ZooKeeper 集羣的每臺機器都會在內存中維護當前的服務器狀態,並且每臺機器之間都會互相保持通信。
重要的一點是,只要集羣中存在超過一半的機器能夠正常工作,那麼整個集羣就能夠正常對外服務。
ZooKeeper 的客戶端程序會選擇和集羣中的任意一臺服務器創建一個 TCP 連接,而且一旦客戶端和服務器斷開連接,客戶端就會自動連接到集羣中的其他服務器。
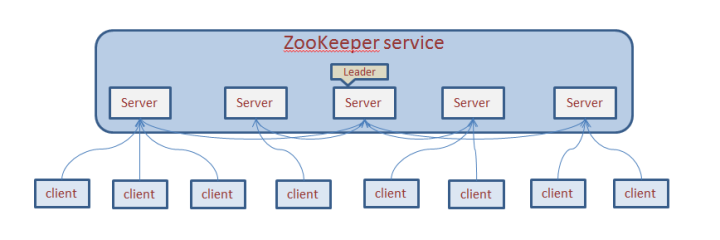
那麼如何運行 ZooKeeper 集羣模式呢?首先假如我們有三臺服務器,IP 分別爲 IP1、IP2 和 IP3,則需要執行以下步驟:
- 準備 Java 運行環境(同上)
- 下載 ZooKeeper 安裝包(同上)
- 配置 zoo.cfg
tickTime=2000
dataDir=/var/lib/zookeeper
dataLogDir=/var/lib/log
clientPort=2181
initLimit=5
syncLimit=2
server.1=IP1:2888:3888
server.2=IP2:2888:3888
server.3=IP3:2888:3888
可以看到,相比於單機模式,集羣模式多了 server.id=host:port1:port2 的配置。
其中,id 被稱爲 Server ID,用來標識該機器在集羣中的機器序號(在每臺機器的 dataDir 目錄下創建 myid 文件,文件內容即爲該機器對應的 Server ID 數字)。host 爲機器 IP,port1 用於指定 Follower 服務器與 Leader 服務器進行通信和數據同步的端口,port2用於進行 Leader 選舉過程中的投票通信。
-
創建 myid 文件
在 dataDir 目錄下創建名爲 myid 的文件,在文件第一行寫上對應的 Server ID。 - 按照相同步驟,爲其他機器配置 zoo.cfg 和 myid文件
- 啓動服務
1.3 僞集羣模式
這是一種特殊的集羣模式,即集羣的所有服務器都部署在一臺機器上。當你手頭上有一臺比較好的機器,如果作爲單機模式進行部署,就會浪費資源,這種情況下,ZooKeeper允許你在一臺機器上通過啓動不同的端口來啓動多個 ZooKeeper 服務實例,以此來以集羣的特性來對外服務。
這種模式下,只需要把 zoo.cfg 做如下修改:
tickTime=2000
dataDir=/var/lib/zookeeper
dataLogDir=/var/lib/log
clientPort=2181
initLimit=5
syncLimit=2
server.1=IP1:2888:3888
server.2=IP1:2889:3889
server.3=IP1:2890:3890
二、集羣組成
要搭建一個高可用的 ZooKeeper 集羣,我們首先需要確定好集羣的規模。
關於 ZooKeeper 集羣的服務器組成,相信很多對 ZooKeeper 瞭解但是理解不夠深入的讀者,都存在或曾經存在過這樣一個錯誤的認識:爲了使得 ZooKeeper 集羣能夠順利地選舉出 Leader,必須將 ZooKeeper 集羣的服務器數部署成奇數。這裏我們需要澄清的一點是:任意臺 ZooKeeper 服務器都能部署且能正常運行。
那麼存在於這麼多讀者中的這個錯誤認識是怎麼回事呢?其實關於 ZooKeeper 集羣服務器數,ZooKeeper 官方確實給出了關於奇數的建議,但絕大部分 ZooKeeper 用戶對於這個建議認識有偏差。在本書前面提到的“過半存活即可用”特性中,我們已經瞭解了,一個 ZooKeeper 集羣如果要對外提供可用的服務,那麼集羣中必須要有過半的機器正常工作並且彼此之間能夠正常通信。基於這個特性,如果想搭建一個能夠允許 N 臺機器 down 掉的集羣,那麼就要部署一個由 2*N+1 臺服務器構成的 ZooKeeper 集羣。因此,一個由 3 臺機器構成的 ZooKeeper 集羣,能夠在掛掉 1 臺機器後依然正常工作,而對於一個由 5 臺服務器構成的 ZooKeeper 集羣,能夠對 2 臺機器掛掉的情況進行容災。注意,如果是一個由6臺服務器構成的 ZooKeeper 集羣,同樣只能夠掛掉 2 臺機器,因爲如果掛掉 3 臺,剩下的機器就無法實現過半了。
因此,從上面的講解中,我們其實可以看出,對於一個由 6 臺機器構成的 ZooKeeper 集羣來說,和一個由 5 臺機器構成的 ZooKeeper 集羣,其在容災能力上並沒有任何顯著的優勢,反而多佔用了一個服務器資源。基於這個原因,ZooKeeper 集羣通常設計部署成奇數臺服務器即可。
三、容災
所謂容災,在 IT 行業通常是指我們的計算機信息系統具有的一種在遭受諸如火災、地震、斷電和其他基礎網絡設備故障等毀滅性災難的時候,依然能夠對外提供可用服務的能力。
對於一些普通的應用,爲了達到容災標準,通常我們會選擇在多臺機器上進行部署來組成一個集羣,這樣即使在集羣的一臺或是若干臺機器出現故障的情況下,整個集羣依然能夠對外提供可用的服務。
而對於一些核心應用,不僅要通過使用多臺機器構建集羣的方式來提供服務,而且還要將集羣中的機器部署在兩個機房,這樣的話,即使其中一個機房遭遇災難,依然能夠對外提供可用的服務。
上面講到的都是應用層面的容災模式,那麼對於 ZooKeeper 這種底層組件來說,如何進行容災呢?講到這裏,可能多少讀者會有疑問,ZooKeeper 既然已經解決了單點問題,那爲什麼還要進行容災呢?
3.1 單點問題
單點問題是分佈式環境中最常見也是最經典的問題之一,在很多分佈式系統中都會存在這樣的單點問題。
具體地說,單點問題是指在一個分佈式系統中,如果某一個組件出現故障就會引起整個系統的可用性大大下降甚至是處於癱瘓狀態,那麼我們就認爲該組件存在單點問題。
ZooKeeper 確實已經很好地解決了單點問題。我們已經瞭解到,基於“過半”設計原則,ZooKeeper 在運行期間,集羣中至少有過半的機器保存了最新的數據。因此,只要集羣中超過半數的機器還能夠正常工作,整個集羣就能夠對外提供服務。
3.2 容災
解決了單點問題,是不是該考慮容災了呢?答案是否定的,在搭建一個高可用的集羣的時候依然需要考慮容災問題。正如上面講到的,如果集羣中超過半數的機器還在正常工作,集羣就能夠對外提供正常的服務。
那麼,如果整個機房出現災難性的事故,這時顯然已經不是單點問題的範疇了。
在進行 ZooKeeper 的容災方案設計過程中,我們要充分考慮到“過半原則”。也就是說,無論發生什麼情況,我們必須保證 ZooKeeper 集羣中有超過半數的機器能夠正常工作。因此,通常有以下兩種部署方案。
3.3.1 雙機房部署
在進行容災方案的設計時,我們通常是以機房爲單位來考慮問題。在現實中,很多公司的機房規模並不大,因此雙機房部署是個比較常見的方案。但是遺憾的是,在目前版本的 ZooKeeper 中,還沒有辦法能夠在雙機房條件下實現比較好的容災效果——因爲無論哪個機房發生異常情況,都有可能使得 ZooKeeper 集羣中可用的機器無法超過半數。當然,在擁有兩個機房的場景下,通常有一個機房是主要機房(一般而言,公司會花費更多的錢去租用一個穩定性更好、設備更可靠的機房,這個機房就是主要機房,而另外一個機房則更加廉價一些)。我們唯一能做的,就是儘量在主要機房部署更多的機器。例如,對於一個由 7 臺機器組成的 ZooKeeper 集羣,通常在主要機房中部署 4 臺機器,剩下的 3 臺機器部署到另外一個機房中。
3.3.2 三機房部署
既然在雙機房部署模式下並不能實現好的容災效果,那麼對於有條件的公司,選擇三機房部署無疑是個更好的選擇,無論哪個機房發生了故障,剩下兩個機房的機器數量都超過半數。假如我們有三個機房可以部署服務,並且這三個機房間的網絡狀況良好,那麼就可以在三個機房中都部署若干個機器來組成一個 ZooKeeper 集羣。
我們假定構成 ZooKeeper 集羣的機器總數爲 N,在三個機房中部署的 ZooKeeper 服務器數分別爲 N1、N2 和 N3,如果要使該 ZooKeeper 集羣具有較好的容災能力,我們可以根據如下算法來計算 ZooKeeper 集羣的機器部署方案。
- 計算 N1
如果 ZooKeeper 集羣的服務器總數是 N,那麼:
1
N1 = (N-1)/2
在 Java 中,“/” 運算符會自動對計算結果向下取整操作。舉個例子,如果 N=8,那麼 N1=3;如果 N=7,那麼 N1 也等於 3。
- 計算 N2 的可選值
N2 的計算規則和 N1 非常類似,只是 N2 的取值是在一個取值範圍內:
1
N2 的取值範圍是 1~(N-N1)/2
即如果 N=8,那麼 N1=3,則 N2 的取值範圍就是 1~2,分別是 1 和 2。注意,1 和 2 僅僅是 N2 的可選值,並非最終值——如果 N2爲某個可選值的時候,無法計算出 N3 的值,那麼該可選值也無效。
- 計算 N3,同時確定 N2 的值
很顯然,現在只剩下 N3 了,可以簡單的認爲 N3 的取值就是剩下的機器數,即:
1
N3 = N - N1 - N2
只是 N3 的取值必須滿足 N3 < N1+N2。在滿足這個條件的基礎下,我們遍歷步驟 2 中計算得到的 N2 的可選值,即可得到三機房部署時每個機房的服務器數量了。
現在我們以 7 臺機器爲例,來看看如何分配三機房的機器分佈。根據算法的步驟 1,我們首先確定 N1 的取值爲 3。根據算法的步驟 2,我們確定了 N2 的可選值爲 1 和 2。最後根據步驟 3,我們遍歷 N2 的可選值,即可得到兩種部署方案,分別是 (3,1,3) 和 (3,2,2)。以下是 Java 程序代碼對以上算法的一種簡單實現:
public class Allocation {
static final int n = 7;
public static void main(String[] args){
int n1,n2,n3;
n1 = (n-1) / 2;
int n2_max = (n-n1) / 2;
for(int i=1; i<=n2_max; i++){
n2 = i;
n3 = n - n1 -n2;
if(n3 >= (n1+n2)){
continue;
}
System.out.println("("+n1+","+n2+","+n3+")");
}
}}
四、水平擴容
水平可擴容可以說是對一個分佈式系統在高可用性方面提出的基本的,也是非常重要的一個要求,通過水平擴容能夠幫助系統在不進行或進行極少改進工作的前提下,快速提高系統對外的服務支撐能力。簡單地講,水平擴容就是向集羣中添加更多的機器,以提高系統的服務質量。
很遺憾的是,ZooKeeper 在水平擴容擴容方面做得並不十分完美,需要進行整個集羣的重啓。通常有兩種重啓方式,一種是集羣整體重啓,另外一種是逐臺進行服務器的重啓。
4.1 整體重啓
所謂集羣整體重啓,就是先將整個集羣停止,然後更新 ZooKeeper 的配置,然後再次啓動。如果在你的系統中,ZooKeeper 並不是個非常核心的組件,並且能夠允許短暫的服務停止(通常是幾秒鐘的時間間隔),那麼不妨選擇這種方式。在整體重啓的過程中,所有該集羣的客戶端都無法連接上集羣。等到集羣再次啓動,這些客戶端就能夠自動連接上——注意,整體啓動前建立起的客戶端會話,並不會因爲此次整體重啓而失效。也就是說,在整體重啓期間花費的時間將不計入會話超時時間的計算中。
4.2 逐臺重啓
這種方式更適合絕大多數的實際場景。在這種方式中,每次僅僅重啓集羣中的一臺機器,然後逐臺對整個集羣中的機器進行重啓操作。這種方式可以在重啓期間依然保證集羣對外的正常服務。
歡迎學Java和大數據的朋友們加入java架構交流: 855835163
羣內提供免費的架構資料還有:Java工程化、高性能及分佈式、高性能、深入淺出。高架構。性能調優、Spring,MyBatis,Netty源碼分析和大數據等多個知識點高級進階乾貨的免費直播講解 可以進來一起學習交流哦