




一、問題起源
Spring Cloud微服務架構體系中,Eureka是一個至關重要的組件,它扮演着微服務註冊中心的角色,所有的服務註冊與服務發現,都是依賴Eureka的。不少初學Spring Cloud的朋友在落地公司生產環境部署時,經常會問:Eureka Server到底要部署幾臺機器?我們的系統那麼多服務,到底會對Eureka Server產生多大的訪問壓力?Eureka Server能不能抗住一個大型系統的訪問壓力?如果你也有這些疑問,彆着急!咱們這就一起去看看,Eureka作爲微服務註冊中心的核心原理下面這些問題,大家先看看,有個大概印象。帶着這些問題,來看後面的內容,效果更佳!Eureka註冊中心使用什麼樣的方式來儲存各個服務註冊時發送過來的機器地址和端口號?各個服務找Eureka Server拉取註冊表的時候,是什麼樣的頻率?各個服務是如何拉取註冊表的?一個有幾百個服務,部署了上千臺機器的大型分佈式系統,會對Eureka Server造成多大的訪問壓力?Eureka Server從技術層面是如何抗住日千萬級訪問量的?先給大家說一個基本的知識點,各個服務內的Eureka Client組件,默認情況下,每隔30秒會發送一個請求到Eureka Server,來拉取最近有變化的服務信息舉個例子:庫存服務原本部署在1臺機器上,現在擴容了,部署到了3臺機器,並且均註冊到了Eureka Server上。然後訂單服務的Eureka Client會每隔30秒去找Eureka Server拉取最近註冊表的變化,看看其他服務的地址有沒有變化。除此之外,Eureka還有一個心跳機制,各個Eureka Client每隔30秒會發送一次心跳到Eureka Server,通知人家說,哥們,我這個服務實例還活着!如果某個Eureka Client很長時間沒有發送心跳給Eureka Server,那麼就說明這個服務實例已經掛了。光看上面的文字,大家可能沒什麼印象。老規矩!咱們還是來一張圖,一起來直觀的感受一下這個過程。
二、Eureka Server設計精妙的註冊表存儲結構
現在咱們假設手頭有一套大型的分佈式系統,一共100個服務,每個服務部署在20臺機器上,機器是4核8G的標準配置。也就是說,相當於你一共部署了100 20 = 2000個服務實例,有2000臺機器。每臺機器上的服務實例內部都有一個Eureka Client組件,它會每隔30秒請求一次Eureka Server,拉取變化的註冊表。此外,每個服務實例上的Eureka Client都會每隔30秒發送一次心跳請求給Eureka Server。那麼大家算算,Eureka Server作爲一個微服務註冊中心,每秒鐘要被請求多少次?一天要被請求多少次?按標準的算法,每個服務實例每分鐘請求2次拉取註冊表,每分鐘請求2次發送心跳這樣一個服務實例每分鐘會請求4次,2000個服務實例每分鐘請求8000次換算到每秒,則是8000 / 60 = 133次左右,我們就大概估算爲Eureka Server每秒會被請求150次那一天的話,就是8000 60 * 24 = 1152萬,也就是每天千萬級訪問量好!經過這麼一個測算,大家是否發現這裏的奧祕了?首先,對於微服務註冊中心這種組件,在一開始設計它的拉取頻率以及心跳發送頻率時,就已經考慮到了一個大型系統的各個服務請求時的壓力,每秒會承載多大的請求量。所以各服務實例每隔30秒發起請求拉取變化的註冊表,以及每隔30秒發送心跳給Eureka Server,其實這個時間安排是有其用意的。按照我們的測算,一個上百個服務,幾千臺機器的系統,按照這樣的頻率請求Eureka Server,日請求量在千萬級,每秒的訪問量在150次左右。即使算上其他一些額外操作,我們姑且就算每秒鐘請求Eureka Server在200次~300次吧。所以通過設置一個適當的拉取註冊表以及發送心跳的頻率,可以保證大規模系統裏對Eureka Server的請求壓力不會太大。現在關鍵的問題來了,Eureka Server是如何保證輕鬆抗住這每秒數百次請求,每天千萬級請求的呢?要搞清楚這個,首先得清楚Eureka Server到底是用什麼來存儲註冊表的?三個字,看源碼!接下來咱們就一起進入Eureka源碼裏一探究竟: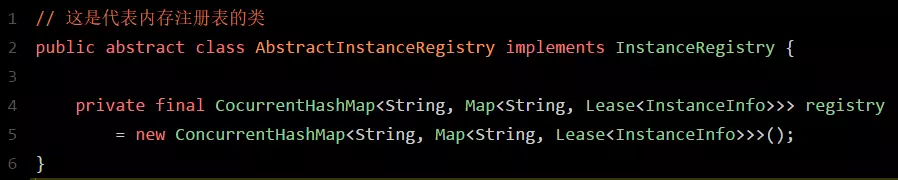
如上圖所示,圖中這個名字叫做registry的CocurrentHashMap,就是註冊表的核心結構。看完之後忍不住先讚歎一下,精妙的設計!從代碼中可以看到,Eureka Server的註冊表直接基於純內存,即在內存裏維護了一個數據結構。各個服務的註冊、服務下線、服務故障,全部會在內存裏維護和更新這個註冊表。各個服務每隔30秒拉取註冊表的時候,Eureka Server就是直接提供內存裏存儲的有變化的註冊表數據給他們就可以了。同樣,每隔30秒發起心跳時,也是在這個純內存的Map數據結構裏更新心跳時間。一句話概括:維護註冊表、拉取註冊表、更新心跳時間,全部發生在內存裏!這是Eureka Server非常核心的一個點。搞清楚了這個,咱們再來分析一下registry這個東西的數據結構,大家千萬別被它複雜的外表唬住了,沉下心來,一層層的分析!首先,這個ConcurrentHashMap的key就是服務名稱,比如“inventory-service”,就是一個服務名稱。value則代表了一個服務的多個服務實例。舉例:比如“inventory-service”是可以有3個服務實例的,每個服務實例部署在一臺機器上。再來看看作爲value的這個Map:Map<String, Lease<InstanceInfo>>這個Map的key就是服務實例的idvalue是一個叫做Lease的類,它的泛型是一個叫做InstanceInfo的東東,你可能會問,這倆又是什麼鬼?首先說下InstanceInfo,其實啊,我們見名知義,這個InstanceInfo就代表了服務實例的具體信息,比如機器的ip地址、hostname以及端口號。而這個Lease,裏面則會維護每個服務最近一次發送心跳的時間三、Eureka Server端優秀的多級緩存機制假設Eureka Server部署在4核8G的普通機器上,那麼基於內存來承載各個服務的請求,每秒鐘最多可以處理多少請求呢?根據之前的測試,單臺4核8G的機器,處理純內存操作,哪怕加上一些網絡的開銷,每秒處理幾百請求也是輕鬆加愉快的。而且Eureka Server爲了避免同時讀寫內存數據結構造成的併發衝突問題,還採用了多級緩存機制來進一步提升服務請求的響應速度。在拉取註冊表的時候:首先從ReadOnlyCacheMap裏查緩存的註冊表。若沒有,就找ReadWriteCacheMap裏緩存的註冊表。如果還沒有,就從內存中獲取實際的註冊表數據。在註冊表發生變更的時候:會在內存中更新變更的註冊表數據,同時過期掉ReadWriteCacheMap。此過程不會影響ReadOnlyCacheMap提供人家查詢註冊表。一段時間內(默認30秒),各服務拉取註冊表會直接讀ReadOnlyCacheMap30秒過後,Eureka Server的後臺線程發現ReadWriteCacheMap已經清空了,也會清空ReadOnlyCacheMap中的緩存下次有服務拉取註冊表,又會從內存中獲取最新的數據了,同時填充各個緩存。多級緩存機制的優點是什麼?儘可能保證了內存註冊表數據不會出現頻繁的讀寫衝突問題。並且進一步保證對Eureka Server的大量請求,都是快速從純內存走,性能極高。爲方便大家更好的理解,同樣來一張圖,大家跟着圖再來回顧一下這整個過程:
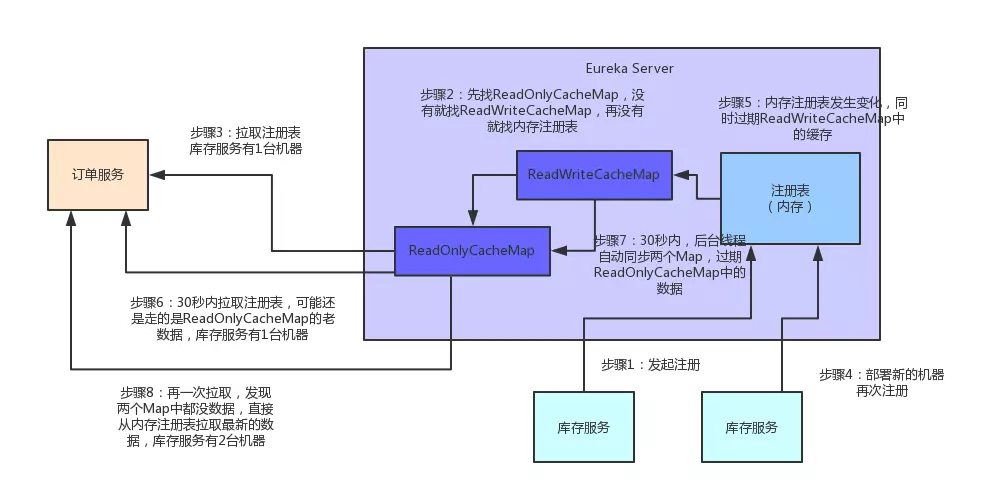
四、總結
通過上面的分析可以看到,Eureka通過設置適當的請求頻率(拉取註冊表30秒間隔,發送心跳30秒間隔),可以保證一個大規模的系統每秒請求Eureka Server的次數在幾百次。同時通過純內存的註冊表,保證了所有的請求都可以在內存處理,確保了極高的性能另外,多級緩存機制,確保了不會針對內存數據結構發生頻繁的讀寫併發衝突操作,進一步提升性能。上述就是Spring Cloud架構中,Eureka作爲微服務註冊中心可以承載大規模系統每天千萬級訪問量的原理。
感興趣的可以自己來我的Java架構羣,可以獲取免費的學習資料,羣號:855801563對Java技術,架構技術感興趣的同學,歡迎加羣,一起學習,相互討論。