




Redis集羣
一、Redis集羣相關概念
1.Redis集羣介紹
Redis 集羣是一個提供在多個Redis間節點間共享數據的程序集。
Redis集羣並不支持處理多個keys的命令,因爲這需要在不同的節點間移動數據,從而達不到像Redis那樣的性能,在高負載的情況下可能會導致不可預料的錯誤.
Redis 集羣通過分區來提供一定程度的可用性,在實際環境中當某個節點宕機或者不可達的情況下繼續處理命令. Redis 集羣的優勢:
1.自動分割數據到不同的節點上。
>2.整個集羣的部分節點失敗或者不可達的情況下能夠繼續處理命令。
2.Redis分片策略
Redis 集羣沒有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集羣有==16384==個哈希槽,每個key通過CRC16校驗後對16384取模來決定放置哪個槽.集羣的每個節點負責一部分hash槽,舉個例子,比如當前集羣有3個節點,那麼:
節點 A 包含 0 到 5500號哈希槽.
節點 B 包含5501 到 11000 號哈希槽.
節點 C 包含11001 到 16384號哈希槽.
這種結構很容易添加或者刪除節點. 比如如果我想新添加個節點D, 我需要從節點 A, B, C中得部分槽到D上. 如果我想移除節點A,需要將A中的槽移到B和C節點上,然後將沒有任何槽的A節點從集羣中移除即可. 由於從一個節點將哈希槽移動到另一個節點並不會停止服務,所以無論添加刪除或者改變某個節點的哈希槽的數量都不會造成集羣不可用的狀態.
3.Redis的主從複製模型
爲了使在部分節點失敗或者大部分節點無法通信的情況下集羣仍然可用,所以集羣使用了主從複製模型,每個節點都會有N-1個複製品.
在我們例子中具有A,B,C三個節點的集羣,在沒有複製模型的情況下,如果節點B失敗了,那麼整個集羣就會以爲缺少5501-11000這個範圍的槽而不可用.
然而如果在集羣創建的時候(或者過一段時間)我們爲每個節點添加一個從節點A1,B1,C1,那麼整個集羣便有三個master節點和三個slave節點組成,這樣在節點B失敗後,集羣便會選舉B1爲新的主節點繼續服務,整個集羣便不會因爲槽找不到而不可用了
不過當B和B1 都失敗後,集羣是不可用的.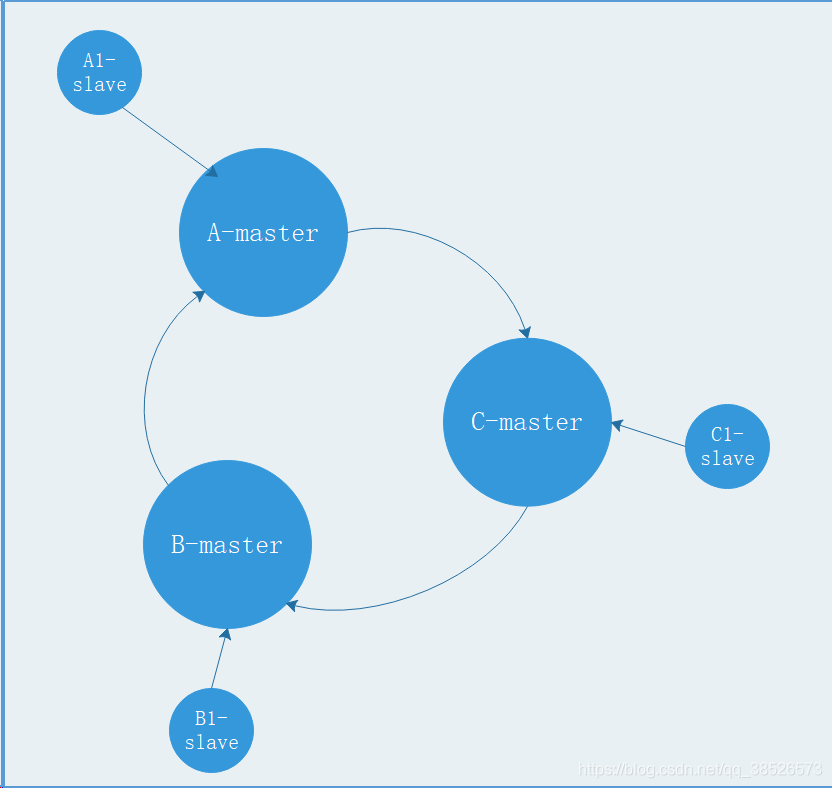
二、Redis集羣搭建
1.集羣的結構
根據官網描述要讓redis集羣環境正常運行我們必須準備至少3個主節點,所以在本文中的集羣環境我們準備3個主節點實例及對應的給每個主節點準備一個從節點實例,一共6個redis實例。正常需要6個虛擬機節點,本文我們在一個虛擬機上模擬。
2.集羣的環境準備
搭建集羣需要使用到官方提供的ruby腳本。
需要安裝ruby的環境。
安裝ruby
yum -y install ruby yum -y install rubygems gem install redis
錯誤處理
[root@hadoop-node01 src]# gem install redisERROR: Error installing redis: redis requires Ruby version >= 2.2.2.
解決方式參考此鏈接:https://blog.csdn.net/qq_38526573/article/details/87220510
解決完成後再次執行gem install redis命令
[root@hadoop-node01 ~]# gem install redisFetching: redis-4.1.0.gem (100%)Successfully installed redis-4.1.0Parsing documentation for redis-4.1.0Installing ri documentation for redis-4.1.0Done installing documentation for redis after 1 seconds1 gem installed
注意ruby對應的redis版本是4.1.0
各版本下載地址
http://download.redis.io/releases/
3.搭建集羣環境
3.1創建實例
在/opt目錄下創建redis-cluster目錄,並在該目錄下創建6個redis實例
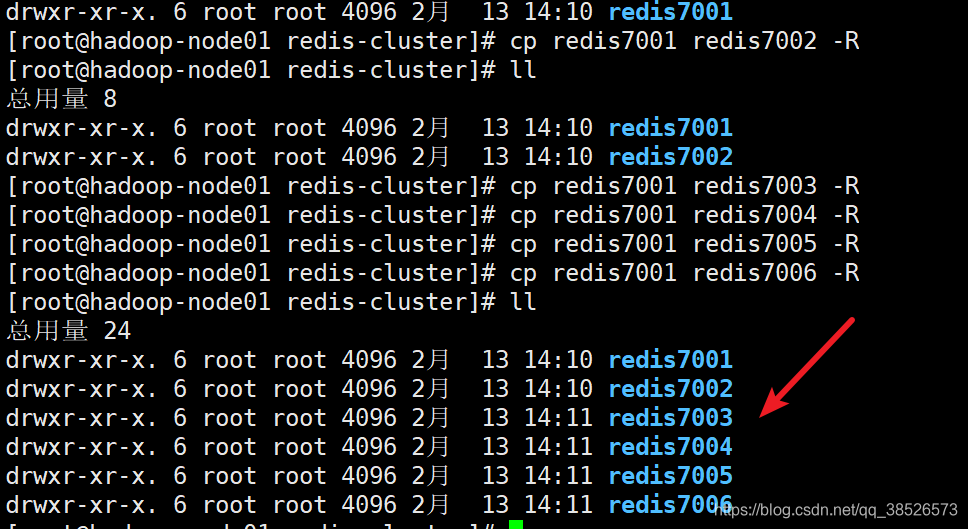
3.2修改配置文件
分別修改6個實例的配置文件
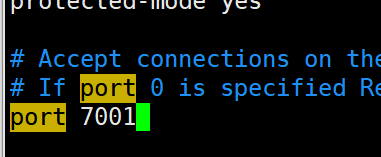
1.修改端口號
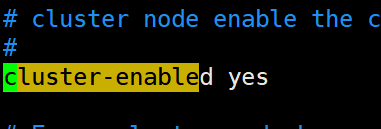
2.打開cluster-enable前面的註釋
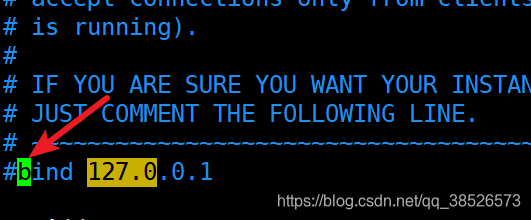
3.註釋掉綁定ip
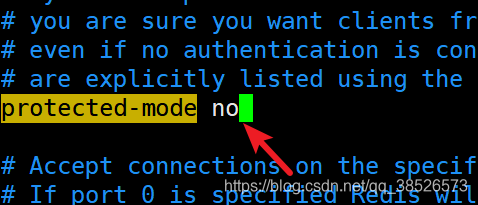
4.保護模式修改爲no
5.設置日誌存儲路徑

注意重複修改6次。
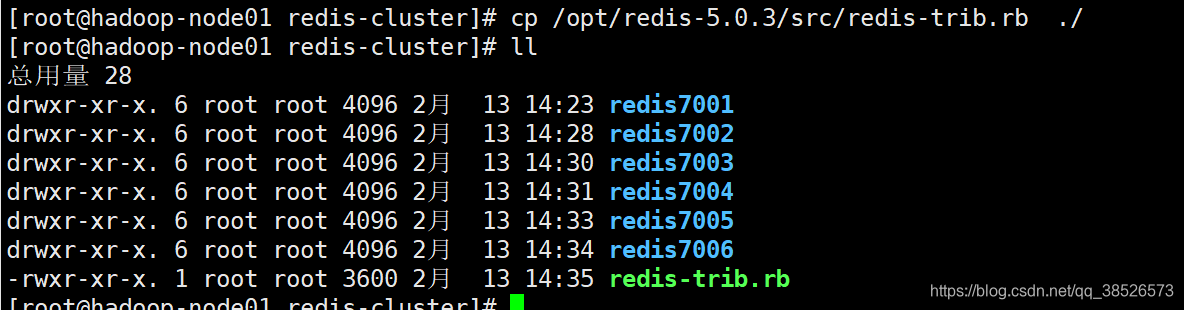
3.3複製ruby腳本
3.4啓動6個實例
啓動實例時可能報錯
Ps: [ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or contains some
解決辦法:
將每個節點下aof、rdb、nodes.conf本地備份文件刪除;
編寫簡單腳本啓動
start-all.sh
cd /opt/redis-cluster/redis7001 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.confcd /opt/redis-cluster/redis7002 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.confcd /opt/redis-cluster/redis7003 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.confcd /opt/redis-cluster/redis7004 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.confcd /opt/redis-cluster/redis7005 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.confcd /opt/redis-cluster/redis7006 rm -rf dump.rdb nodes.conf appendonly.aof src/redis-server redis.conf
改變文件腳本權限模式:
chmod 777 start-all.sh
然後再啓動:
./start-all.sh
3.5創建集羣
現在我們已經有了六個正在運行中的 Redis 實例, 接下來我們需要使用這些實例來創建集羣, 併爲每個節點編寫配置文件。
通過使用 Redis 集羣命令行工具 redis-trib , 編寫節點配置文件的工作可以非常容易地完成: redis-trib 位於 Redis 源碼的 src 文件夾中, 它是一個 Ruby 程序, 這個程序通過向實例發送特殊命令來完成創建新集羣, 檢查集羣, 或者對集羣進行重新分片(reshared)等工作
./redis-trib.rb create --replicas 1 192.168.88.121:7001 192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168.88.121:7006
命令說明
選項–replicas 1 表示我們希望爲集羣中的每個主節點創建一個從節點
之後跟着的其他參數則是這個集羣實例的地址列表,3個master3個slave
redis-trib 會打印出一份預想中的配置給你看, 如果你覺得沒問題的話, 就可以輸入 ==yes==, redis-trib 就會將這份配置應用到集羣當中,讓各個節點開始互相通訊,最後可以得到如下信息:
[root@hadoop-node01 redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.88.121:7001 192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168>>> Creating cluster Invalid IP or Port (given as 192.168) - use IP:Port format [root@hadoop-node01 redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.88.121:7001 192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168.88.121:7006>>> Creating cluster>>> Performing hash slots allocation on 6 nodes... Using 3 masters:192.168.88.121:7001 192.168.88.121:7002 192.168.88.121:7003 Adding replica 192.168.88.121:7005 to 192.168.88.121:7001 Adding replica 192.168.88.121:7006 to 192.168.88.121:7002 Adding replica 192.168.88.121:7004 to 192.168.88.121:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their masterM: f97aa0b15e5a7f51c69f26543e7b785d52479afe 192.168.88.121:7001 slots:0-5460 (5461 slots) masterM: 8e4a66caac1f738e9d951d212a5ba2a00e675acd 192.168.88.121:7002 slots:5461-10922 (5462 slots) masterM: 1528779486cb926b11cb996c5682c6b749d26bc1 192.168.88.121:7003 slots:10923-16383 (5461 slots) masterS: ea08ca738d621c5161a0ecfe838ed8fd89f5c0c5 192.168.88.121:7004 replicates 8e4a66caac1f738e9d951d212a5ba2a00e675acdS: 0ac234a10f28e24173ffc4e686073fa7710dd264 192.168.88.121:7005 replicates 1528779486cb926b11cb996c5682c6b749d26bc1S: d560e0e3da9a715fb4aae5910cf5533cec2f815f 192.168.88.121:7006 replicates f97aa0b15e5a7f51c69f26543e7b785d52479afe Can I set the above configuration? (type 'yes' to accept): yes>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join......>>> Performing Cluster Check (using node 192.168.88.121:7001)M: f97aa0b15e5a7f51c69f26543e7b785d52479afe 192.168.88.121:7001 slots:0-5460 (5461 slots) master 1 additional replica(s)S: d560e0e3da9a715fb4aae5910cf5533cec2f815f 192.168.88.121:7006 slots: (0 slots) slave replicates f97aa0b15e5a7f51c69f26543e7b785d52479afeM: 1528779486cb926b11cb996c5682c6b749d26bc1 192.168.88.121:7003 slots:10923-16383 (5461 slots) master 1 additional replica(s)M: 8e4a66caac1f738e9d951d212a5ba2a00e675acd 192.168.88.121:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s)S: 0ac234a10f28e24173ffc4e686073fa7710dd264 192.168.88.121:7005 slots: (0 slots) slave replicates 1528779486cb926b11cb996c5682c6b749d26bc1S: ea08ca738d621c5161a0ecfe838ed8fd89f5c0c5 192.168.88.121:7004 slots: (0 slots) slave replicates 8e4a66caac1f738e9d951d212a5ba2a00e675acd [OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage... [OK] All 16384 slots covered.
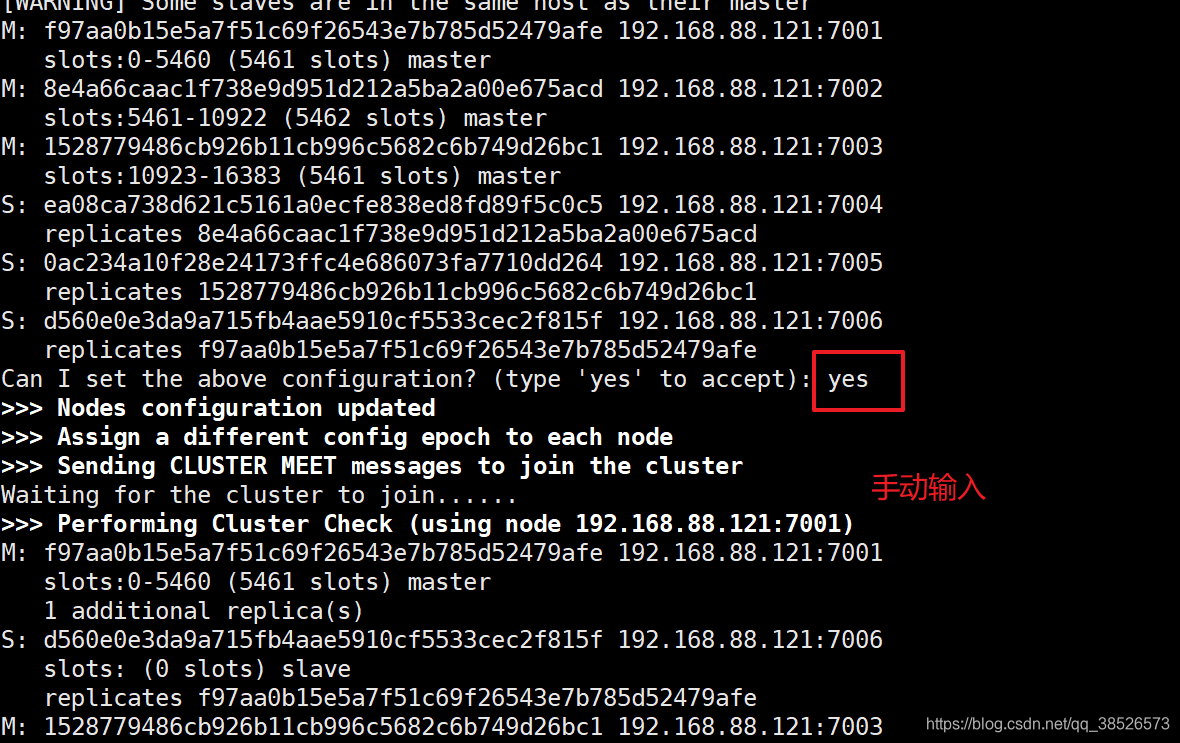
這表示集羣中的 16384 個槽都有至少一個主節點在處理, 集羣運作正常。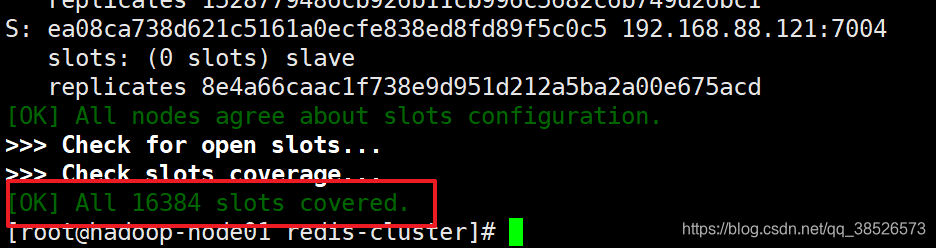
4.測試集羣
登錄命令
redis7001/src/redis-cli -h 192.168.88.121 -p 7001 -c
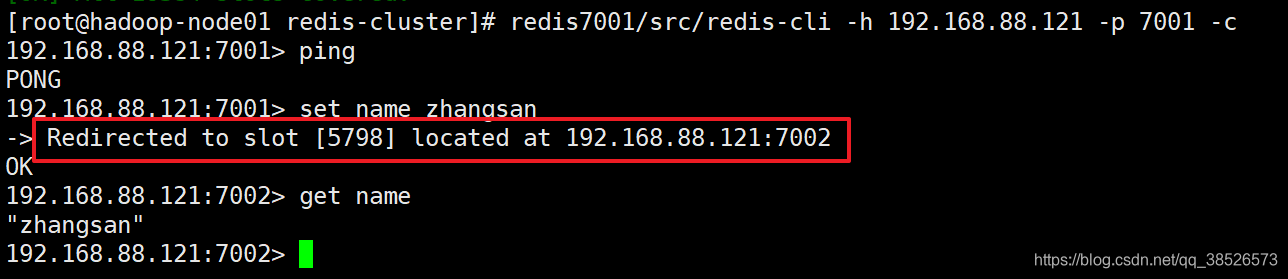 添加一個key被分配到7002節點上,注意連接的端口變爲了7002。
添加一個key被分配到7002節點上,注意連接的端口變爲了7002。
5.查看集羣環境
| 命令 | 說明 |
|---|---|
| cluster info | 打印集羣的信息 |
| cluster nodes | 列出集羣當前已知的所有節點( node),以及這些節點的相關信息。節點 |
| cluster meet <ip> <port> | 將 ip 和 port 所指定的節點添加到集羣當中,讓它成爲集羣的一份子。 |
| cluster forget | 從集羣中移除 node_id 指定的節點。 |
| cluster replicate | 將當前節點設置爲 node_id 指定的節點的從節點。 |
| cluster saveconfig | 將節點的配置文件保存到硬盤裏面。槽(slot) |
| cluster addslots <slot> [slot ...] | 將一個或多個槽( slot)指派( assign)給當前節點。 |
| cluster delslots <slot> [slot ...] | 移除一個或多個槽對當前節點的指派。 |
| cluster flushslots | 移除指派給當前節點的所有槽,讓當前節點變成一個沒有指派任何槽的節點。 |
| cluster setslot <slot> node <node_id> | 將槽 slot 指派給 node_id 指定的節點,如果槽已經指派給另一個節點,那麼先讓另一個節點刪除該槽>,然後再進行指派。 |
| cluster setslot <slot> migrating <node_id> | 將本節點的槽 slot 遷移到 node_id 指定的節點中。 |
| cluster setslot <slot> importing <node_id> | 從 node_id 指定的節點中導入槽 slot 到本節點。 |
| cluster setslot <slot> stable | 取消對槽 slot 的導入( import)或者遷移( migrate)。鍵 |
| cluster keyslot <key> | 計算鍵 key 應該被放置在哪個槽上。 |
| cluster countkeysinslot <slot> | 返回槽 slot 目前包含的鍵值對數量。 |
| cluster getkeysinslot <slot> <count> | 返回 count 個 slot 槽中的鍵 |
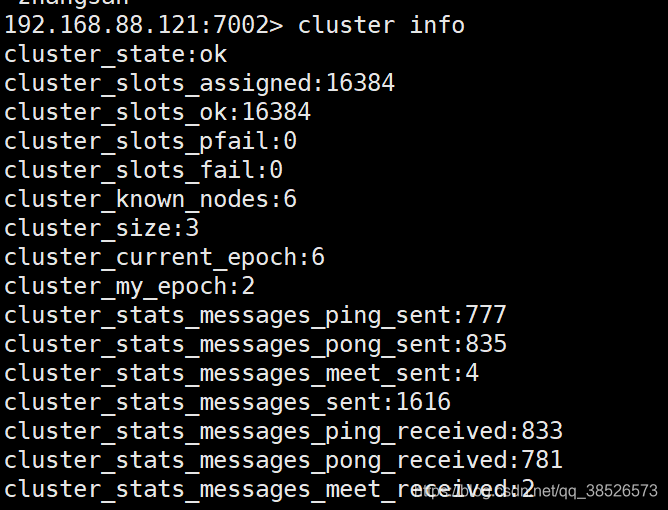
cluster info命令
cluster nodes

6.增加節點
添加新的節點的基本過程就是添加一個空的節點然後移動一些數據給它,有兩種情況,添加一個主節點和添加一個從節點(添加從節點時需要將這個新的節點設置爲集羣中某個節點的複製)
添加一個新的實例
啓動新的7007節點,使用的配置文件和以前的一樣,只要把端口號改一下即可,過程如下:
在終端打開一個新的標籤頁.
進入redis-cluster 目錄.
複製並進入redis7007文件夾.
和其他節點一樣,創建redis.conf文件,需要將端口號改成7007.
最後啓動節點 ../redis-server ./redis.conf
如果正常的話,節點會正確的啓動.
1.添加主節點
./redis-trib.rb add-node 192.168.88.121:7007 192.168.88.121:7001
第一個參數是新節點的地址,第二個參數是任意一個已經存在的節點的IP和端口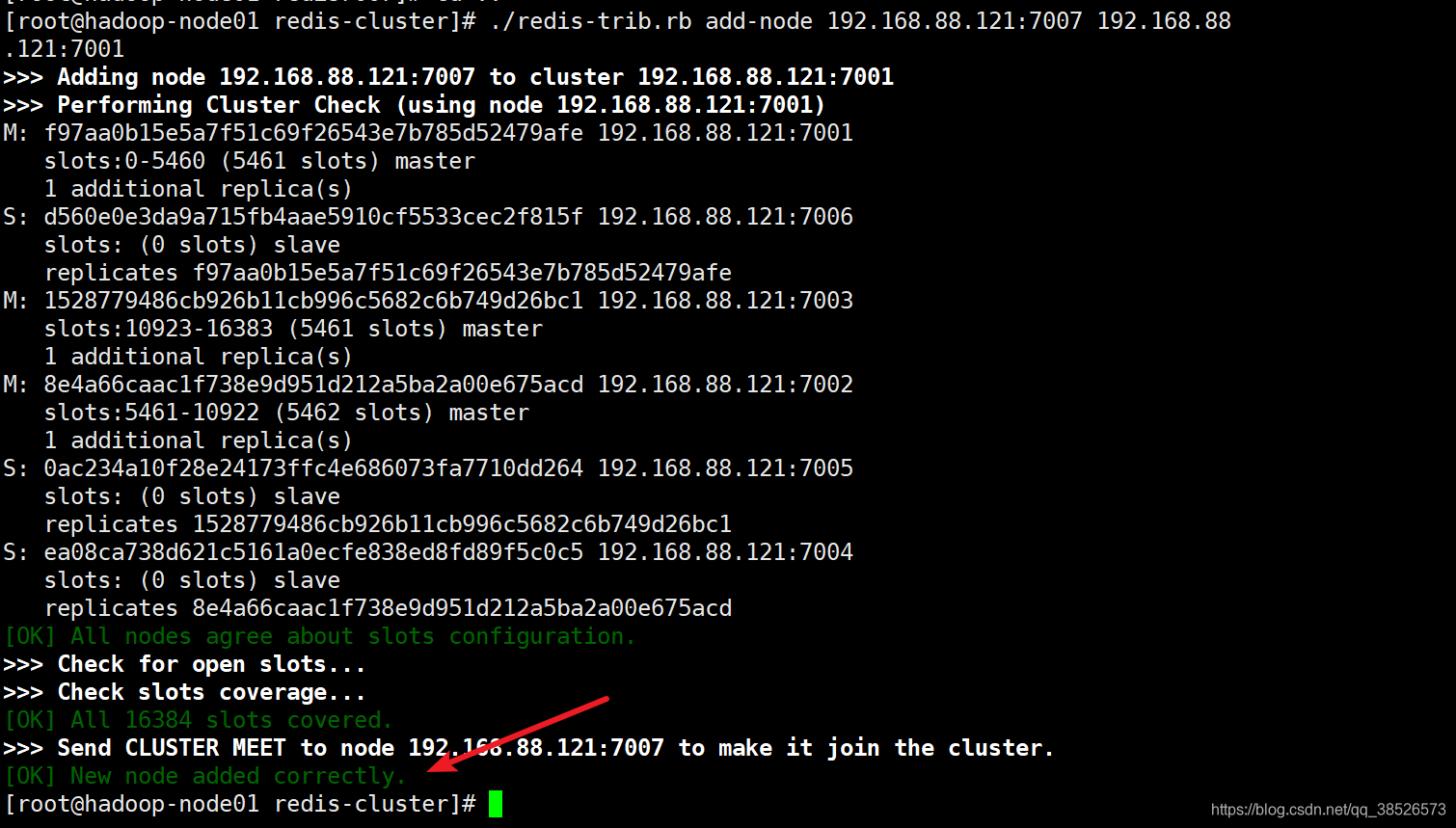

新節點現在已經連接上了集羣, 成爲集羣的一份子, 並且可以對客戶端的命令請求進行轉向了, 但是和其他主節點相比, 新節點還有兩點區別:
新節點沒有包含任何數據, 因爲它沒有包含任何哈希槽.
儘管新節點沒有包含任何哈希槽, 但它仍然是一個主節點, 所以在集羣需要將某個從節點升級爲新的主節點時, 這個新節點不會被選中。
接下來, 只要使用 redis-trib 程序, 將集羣中的某些哈希桶移動到新節點裏面, 新節點就會成爲真正的主節點了。
重新分配slot
./redis-trib.rb reshard 192.168.88.121:7001
只需要指定集羣中其中一個節點的地址, redis-trib 就會自動找到集羣中的其他節點
 7007節點被分類slot,成了真正意義上的主節點
7007節點被分類slot,成了真正意義上的主節點
2.添加從節點
添加的從節點被隨機的配置任意的主節點
./redis-trib.rb add-node --slave 192.168.88.121:7008 192.168.88.121:7001
將從節點添加給指定的主節點
./redis-trib.rb add-node --slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7006 127.0.0.1:7000
7.刪除節點
使用del-node命令移除節點。
./redis-trib.rb del-node 192.168.2.11:7007 <node-id>
第一個參數:任意集羣中現有的地址192.168.88.121:7001
第二個參數:你想移除的節點id ab853f5e95f1e32e0ee40543a9687d60fc3bd941 (該id可以在想要移除的節點nodes.conf文件中找到)
關閉redis
redis7001/redis-cli -p 7001 shutdown
./redis-cli shutdown
pkill -9 redis-server –關閉所有的redis服務
~好了redis的集羣操作就介紹到此,