




Spark分区详解!DT大数据梦工厂王家林老师亲自讲解!
http://www.tudou.com/home/_79823675/playlist?qq-pf-to=pcqq.group
一、分片和分区的区别?
分片是从数据角度,分区是从计算的角度,其实都是从大的状态,split成小的。
二、spark分区理解
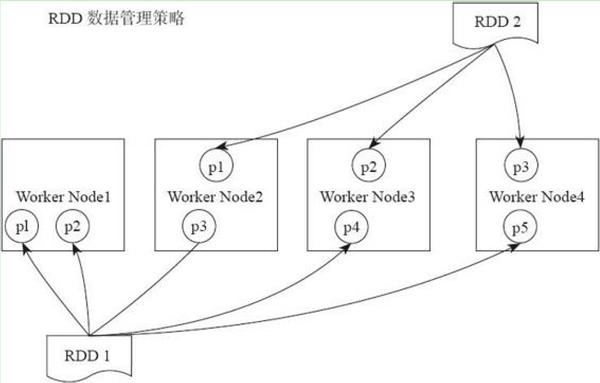
rdd作为一个分布式的数据集,是分布在多个worker节点上的。如下图所示,RDD1有五个分区(partition),他们分布在了四个worker nodes 上面,RDD2有三个分区,分布在了三个worker nodes上面。
三、默认分区
一般情况下,是从hdfs文件存储的block数量作为分区的大小,但有时候一条记录夸block,那么会出现多一个的情况,而且block会略大于或小于128MB。
四、重新分区
想要重新给rdd分区,分两种情况,创建 RDD 时和通过转换操作得到新 RDD 时。
对于前者,在调用 textFile 和 parallelize 方法时候手动指定分区个数即可。例如 sc.parallelize(Array(1, 2, 3, 5, 6), 2) 指定创建得到的 RDD 分区个数为 2。
对于后者,直接调用rdd.repartition方法就可以了,如果想具体控制哪些数据分布在哪些分区上,可以传一个Ordering进去。比如说,我想要数据随机地分布成10个分区,可以:
class MyOrdering[T] extends Ordering[T]{
def compare(x:T,y:T) = math.random compare math.random
}
// 假设数据是Int类型的
rdd.repartition(10)(new MyOrdering[Int])
实际上分区的个数是根据转换操作对应多个 RDD 之间的依赖关系来确定,窄依赖子 RDD 由父 RDD 分区个数决定,例如 map 操作,父 RDD 和子 RDD 分区个数一致;Shuffle 依赖则由分区器(Partitioner)决定,例如 groupByKey(new HashPartitioner(2)) 或者直接 groupByKey(2) 得到的新 RDD 分区个数等于 2。