




原文鏈接:https://www.fkomm.cn/article/2018/8/1/26.html
這次介紹一個及其強大的爬蟲框架---Scrapy,Scrapy由 Python 編寫,是一個快速、高層次的屏幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的數據。Scrapy用途廣泛,可以用於數據挖掘、監測和自動化測試。
Srapy框架的安裝:
無論是在windows還是mac以及linux下,都可以是用pip工具進行快速安裝:
$ pip install scrapy
這裏推薦一個非常好用的Python調試shell:ipython。
ipython是一個python的交互式shell,比默認的python shell好用得多,支持變量自動補全,自動縮進,支持bash shell命令,內置了許多很有用的功能和函數。學習ipython將會讓我們以一種更高的效率來使用python。同時它也是利用Python進行科學計算和交互可視化的一個最佳的平臺。
我們依舊用pip工具進行安裝:
$ pip install ipython
Scrapy框架的基本介紹:
首先,我們得明白一點,Scrapy不是一個功能函數庫,而是是用純Python實現一個爲了爬取網站數據、提取結構性數據而編寫的應用框架。簡單的說,他是一個半成品,可以幫助用戶簡單快速的部署一個專業的網絡爬蟲。如果說前面我們寫的定製bs4爬蟲是“手動擋”,那Scrapy就相當於“半自動檔”的車。
其次,Scrapy 使用了 Twisted(其主要對手是Tornado)異步網絡框架來處理網絡通訊,可以加快我們的下載速度,不用自己去實現異步框架,並且包含了各種中間件接口,可以靈活的完成各種需求。
框架的力量,用戶只需要定製開發幾個模塊就可以輕鬆的實現一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便。
Scrapy框架結構:
首先來一張框架整體的圖:
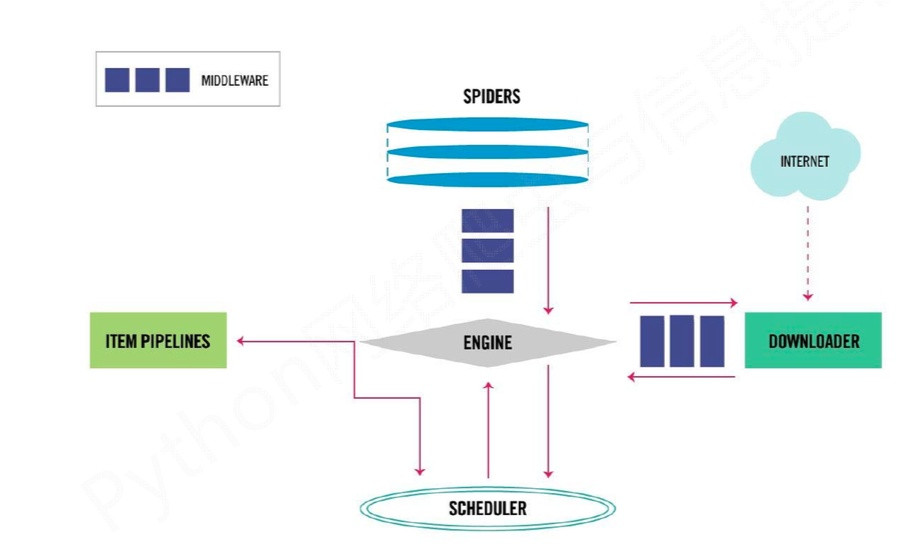
從圖中我們可以清楚的看到,整個框架一共分爲五個部分:
- SPIDERS
- ITEM PIPELINES
- DOWNLOADER
- SCHEDULER
- ENGIINE
這五個部分互相協作,共同完成了整個爬蟲項目的工作。下面我們來一個一個介紹。
SPIDERS:
Spiders這個模塊就是整個爬蟲項目中需要我們手動實現的核心部分,就是類似我們之前寫的get_content函數部分,最主要的功能是 解析網頁內容、產生爬取項、產生額外的爬去請求。
ITEM PIPELINES:
這個模塊也是需要我們手動實現的,他的主要功能是將我們爬取篩選完畢的數據寫入文本,數據庫等等。總之就是一個“本地化”的過程。
DOWNLOADER:
這個模塊,是Scrapy幫我們做好的,不需要我們自己編寫,直接拿來用就行,其主要功能就是從網上獲取網頁內容,類似於我們寫的get_html函數,當然,比我們自己寫的這個簡單的函數要強大很多
SCHEDULER:
這個模塊對所有的爬取請求,進行調度管理,同樣也是不需要我們寫的模塊。通過簡單的配置就能達到更加多線程,併發處理等等強大功能。
ENGIINE
這個模塊相當於整個框架的控制中心,他控制着所有模塊的數據流交換,並根據不同的條件出發相對應的事件,同樣,這個模塊也是不需要我們編寫的。
Scrapy框架的數據流動:
先上一張圖:
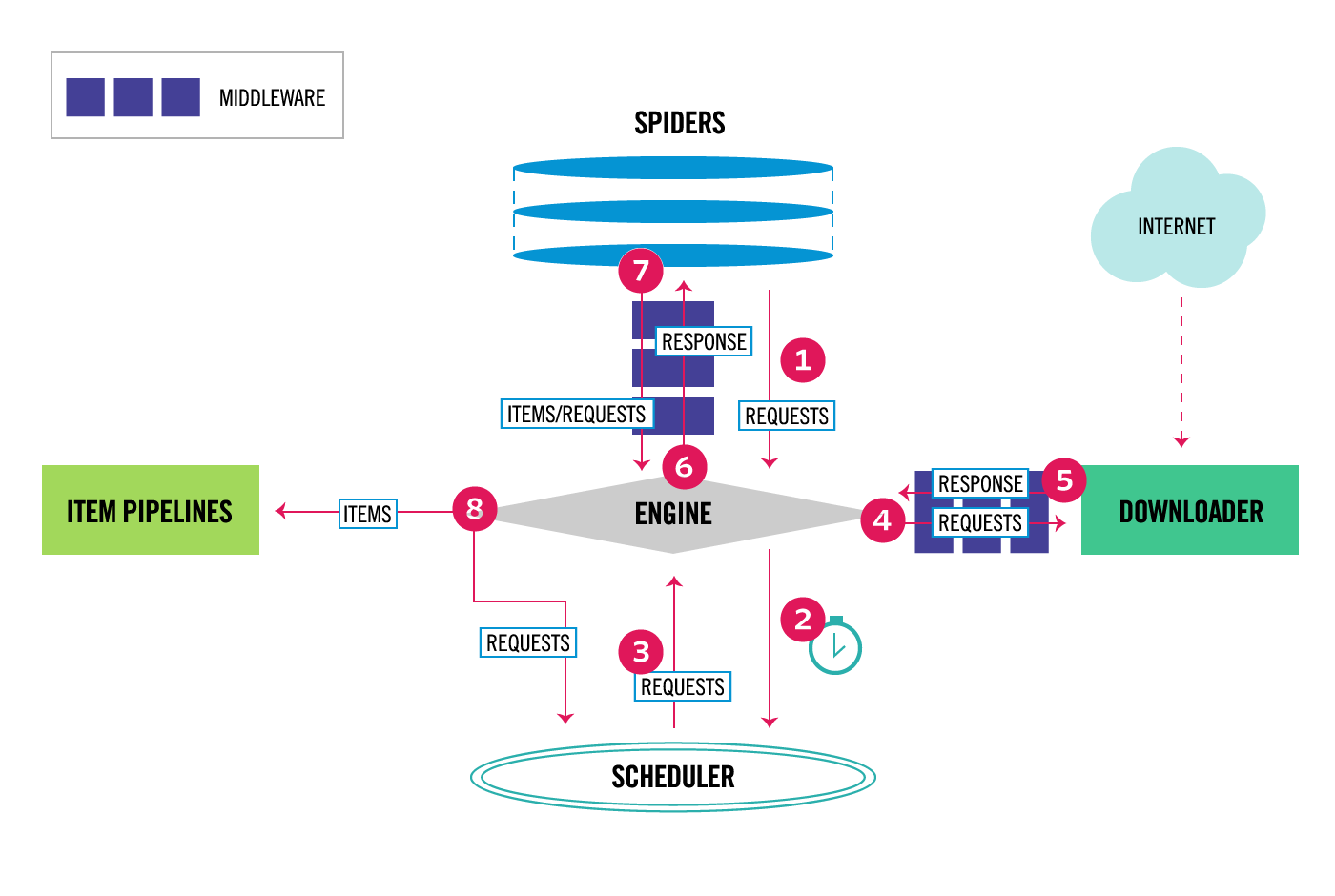
說了各個模塊的作用,那麼整個項目跑起來的時候,數據到底是怎麼運作的呢? 上圖的數字代表數據的流向,解釋如下:
- Engine從Spider處獲得爬取請求(request)
- Engine將爬取請求轉發給Scheduler,調度指揮進行下一步
- Engine從Scheduler出獲得下一個要爬取的請求
- Engine將爬取請求通過中間件發給Downloader
- 爬取網頁後後,downloader返回一個Response給engine
- Engine將受到的Response返回給spider處理
- Spider處理響應後,產生爬取項和新的請求給engine
- Engine將爬取項發送給ITEM PIPELINE(寫出數據)
- Engine將會爬取請求再次發給Scheduler進行調度(下一個週期的爬取)
系統化入門
Scrapy是一個很強大的爬蟲框架,用起來很方便,但是要定製高級的功能就不是那麼簡單的了。這裏只是簡單的介紹了一下框架的基本原理,但具體如何使用不是一時半會能夠說完的,後面我會在例子中一一展現這個框架的高級功能。
如果你想要更加系統化的學習理解這個框架,可以看看Scrapy的官方文檔:[Scrapy 1.5文檔]
(https://doc.scrapy.org/en/latest/),會讓你受益匪淺的!!!!