




摘要: 以“數字金融新原力(The New Force of Digital Finance)”爲主題,螞蟻金服ATEC城市峯會於2019年1月4日上海如期舉辦。財富管理專場上,螞蟻金服財富事業羣資深技術專家康宇麟做了主題爲《人工智能在財富領域的應用與探索》的精彩分享。
演講中,康宇麟分別從如何智能感知用戶的需求,生產豐富的內容,動態的服務分發和提供更好的財富管理服務等四個方面爲大家介紹了螞蟻金服在人工智能方面的一些探索與嘗試。在這四個方向上,螞蟻金服希望能夠與金融機構深度合作,通過螞蟻財富將金融機構的優質內容,優質服務和優質市場觀點接入到螞蟻系統,一起爲用戶提供更好的服務。
以下內容根據演講嘉賓視頻分享以及PPT整理而成。
https://tech.antfin.com/activities/111/review/627
本次的分享主要圍繞以下兩大方面:
一、金融智能的核心能力
二、螞蟻金服AI中臺
-
感知用戶的需求
-
生產豐富的內容
-
動態的服務分發
- 更好的財富管理服務
一、金融智能的核心能力
人工智能技術這幾年非常火熱,螞蟻金服也在AI領域做了很多的探索,同時取得了一定的結果,沉澱了一定的能力。下圖中可以看到人工智能技術基本已深入到了螞蟻金服各個業務中。
智能營銷項目 。螞蟻金服經常會做一些營銷活動,給用戶發放權益紅包。以前的做法是發放固定價值的權益紅包。但有了智能營銷之後,可以根據用戶的特徵,動態的決定給用戶發放紅包的價值。智能營銷大大的降低了螞蟻金服營銷活動的成本。
保險智能理賠 。使用人工智能技術可以幫助螞蟻金服決定給客戶理賠的金額,這大大提升了運營的效率。
網商風控大腦。人工智能幫助螞蟻金服根據借貸者的信用狀況,動態的決定給借貸者的借貸份額,在控制風險的前提下最大化利潤。
智能理財顧問。螞蟻金服正在開發一套系統,以人機交互對話形式爲用戶提供一對一的個性化的理財顧問服務。
推薦陪伴服務。根據用戶的歷史的行爲軌跡猜測出用戶的喜好。根據用戶的喜好動態的推薦適合用戶的服務,產品以及內容。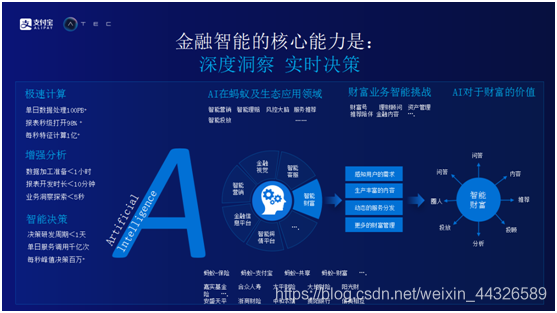
總體上,螞蟻金服主要在做以下兩件事,一是深度的洞察,二是實時決策。深度洞察是指多維度洞察,包括對投資者的洞察,對市場的洞察,對行業的洞察以及對產品的洞察等。瞭解了投資者和產品之後,在這個基礎上做實時決策。深度洞察和實時決策之間具有很強的依賴,通過高速的計算能力和智能決策平臺方便螞蟻金服測試新的規則和策略。
二、螞蟻金服AI中臺
螞蟻金服在人工智能領域的探索過程當中沉澱了強大的螞蟻金服中臺。聚焦到螞蟻財富在人工智能方面的探索,主要做了如下四件事情。感知用戶的需求,生產豐富的內容,動態的服務分發以及更好的財富管理服務。
1.感知用戶的需求
智能問答系統。探索感知用戶的需求有兩種方式。第一種是隱性方式,通過學習用戶的歷史行爲軌跡,猜測用戶的需求。另外一種是顯性方式,用戶可以通過人機對話方式直接提問,問一些簡單的問題或者概念性的問題,比如說,什麼是基金?什麼是股票?或者更進一步,用戶也可以問現在有一萬塊錢,應該買什麼理財產品?或者可不可以推薦一個最適合用戶的基金?
下圖爲螞蟻金服智能問答系統架構圖。當用戶提一個問題之後,主要經過五步。
Step1. 預處理。
a. 常用詞過濾。用戶在提問題的時候,會使用一些常用詞,而這些詞對後面分析用戶的意圖沒有任何幫助。用戶可能會說“早上好”,“麻煩問一下”。系統需要將這些常用詞在預處理階段直接過濾掉。
b. 糾錯。糾正用戶的拼寫錯誤。比如用戶經常會把“基金”寫成“機經”。
c. 實體識別。簡單來講,實體識別是對用戶輸入的句子進行分詞,再對每一個詞打上相應的標籤。用戶問“花唄如何開通?”,這句話裏面有三個詞,主語是花唄,問題是如何是操作,動詞是開通。對用戶的問題做實體識別會對後面具體識別用戶的意圖有很大的幫助。
Step2. 模型層。將用戶的問題轉化成事先定義好的意圖。比如說,用戶想查詢市場行情或者想購買基金,事先定義好這些意圖。如何把用戶問的問題轉化成意圖?分別通過規則和算法。規則方式一般使用FST模型和Fuzzy match(模糊匹配)來提高覆蓋率。規則模型最大的好處是一旦與用戶的意圖匹配上了,準確率會非常高,但劣勢是覆蓋率會很低。如果只是依賴規則模型,很難理解用戶所有的問題。在規則模型基礎之上,螞蟻金服開發了基於算法的模型,如XG B, Fast Text,及RNN,和CNN等深度學習模型。算法類模型的好處是覆蓋率比規則類模型高。所以通過將規則類和算法類模型結合在一起,便可以得到滿意的覆蓋率和準確率。
Step3. 要素提取。用戶想在平臺上購買一支基金,這是一個意圖,意圖中有三個要素。第一個是想買什麼基金,第二個是想什麼時候買,第三個是想購買的份額。用戶輸入了一個問題之後,系統如果判斷得出這個問題是一個購買基金的意圖,就會嘗試抓取抽取以上三個要素,如抽取到了三個要素,便可以直接幫助用戶下單。有時用戶可能只告訴系統一個或兩個要素,其中有一些要素缺失,系統會反問用戶,直到用戶把所有要素信息提供給系統,系統再幫助用戶下單。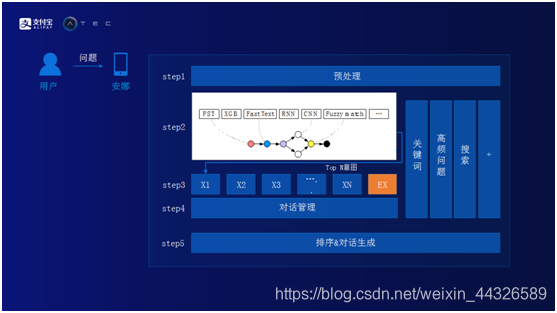
Step4. 對話管理。對話管理主要做了兩件事情,意圖的切換以及將當前意圖中的要素進行存儲。假設用戶在之前的意圖中缺失要素,系統反問用戶收取要素信息,用戶沒有回答這個問題,而問了另外的問題,即轉到了另外的意圖。這種情況下,系統會把當前意圖要素先進行存儲,等下一個意圖完成之後,用戶如果回到前一個意圖,系統再把之前的要素讀取出來,避免讓用戶進行重新輸入。
Step5. 排序和對話生成。Step3中提到的每個模型都會生成期望答案,在Step5中將它們的答案進行精排再做最後的決定。如下圖,用戶問基金分析,系統中匹配到基金分析的意圖。從“基金分析”這個意圖中需要知道“基金名字”這個要素,由於用戶沒有告訴系統基金名字,所以反問“你想知看看哪個基金呢?”,用戶告訴系統是“中證白酒”,系統就可以提取“中證白酒”基金的相關信息並返回給用戶。之後用戶問了一句“有什麼新聞”,實際上這是另外一個意圖,但是因爲在前一個意圖中用戶已經明確的告訴系統對“中證白酒”基金感興趣,所以系統返回的新聞也是關於“中證白酒”的新聞。
2. 生產豐富的內容
單純瞭解用戶意圖還遠遠不夠,智能問答系統中需要有豐富的內容。對於內容的部分,螞蟻金服通過社區得到了優質的內容,以及通過爬蟲從網上抓取了更多信息,再對信息進行了處理加工。螞蟻金服本身並不是一家專業的內容生產公司,所以在內容方面更多的依賴於合作伙伴和機構。希望通過螞蟻財富,將機構的優秀內容接入到螞蟻系統中,再通過智能問答系統傳遞給用戶。網絡上有海量的信息,最大的問題海量信息都是以碎片化的方式很無序的散落在各個角落。這給用戶帶來了兩個問題,首先,他們不知道到從×××到這些信息。其次,因爲這些信息太過於零散,不知道如何發掘它們之間的關係,幫助用戶做更好的投資決策。螞蟻財富一直在嘗試克服海量信息帶來的困難,從下圖可以看到螞蟻財富主要做的兩件事情。一是將無序的信息變得有序,二是在有序信息基礎之上,讓內容產生更多價值並服務於用戶。首先,散亂無序的內容片斷進入系統,系統通過各種各樣的嘗試將信息變成有序的事件體系。對內容進行聚類和挖掘分析,最後提取出更有價值的信息提供給客戶。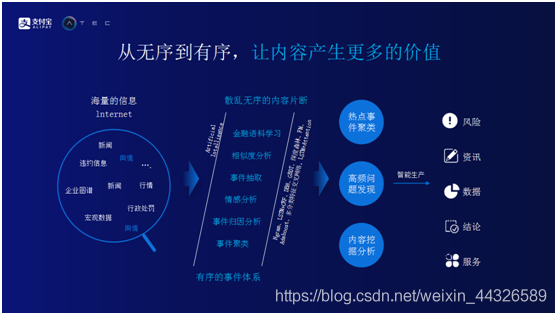
事件抽取。理解一個新聞或者一個事件有兩種範式,標準化事件通路和開放式事件通路。標準化事件通路,可以簡單的理解爲類似的事情以前已經發生過或者見過,而且已經被系統梳理過,對這類事件和事件的要素進行定義。比如“上市公司高管離職”的事件中有三個要素,公司名字,高管姓名以及離職時間。如果事件已經遇到過,可以通過模板定義事件,即使用深度學習的方法,將事件映射到一個標準的模板,從模版中抽取要素。如果能夠抽取到事件要素,可以認爲這個事件匹配成功,即事件變成了結構化的信息,而且系統知識圖譜庫對這個事件有一定了解。但有時會發生突發事件,如中美貿易戰就從未發生過,標準庫中並沒有這類事件的定義,可以通過開放式的事件通路來實現這類事件的抓取。開放式通路是將事件中的主謂賓抽取出來,把這些信息存到知識圖譜庫中。假設“國民生產總值明年會上升”事件以前沒有遇到,從這句話中把相關要素提取出來。主語是“國民生產總值”,謂語是“上升”。如果後面發現類似事件出現的頻率很高,可以將開放式事件轉化成標準式事件。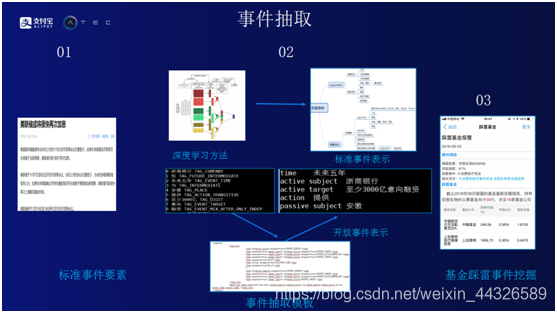
事件推理
基於因果事件的定性影響推理。在事件抽取的基礎上做事件推理。一則新聞中提到“新能源車補貼有望十月出臺,鋰電池需求激增可期”。首先,從這句話中提取因果事件的單元對,瞭解到新能源車補貼出臺會導致鋰電池的需求劇增。然後在知識圖譜庫裏查詢,發現鋰電池需求激增對鋰電池行業有利好。再從知識圖譜庫中找到鋰電池行業龍頭股,即贏合科技和東源電器。從這件事情上可以推理出“新能源車補貼有望十月出臺”是利好贏合科技和東源電器的。
基於統計回測的事件影響推理。有一則新聞說“2018年7月6日,上市公司高管李宏盛被抓”。首先從知識圖譜庫中尋找“李宏盛”,發現“李宏盛”是“登海種業”的高管,而登海種業的股票代碼爲002041。通過規則可以知道這是一個上市公司高管不能履職的事件。根據這類事件進行回測,查看這類事件歷史發生次數,發生之後股價在未來一個星期內的變化量,進行統計,推理出002041這支股票在未來一週之內會下降。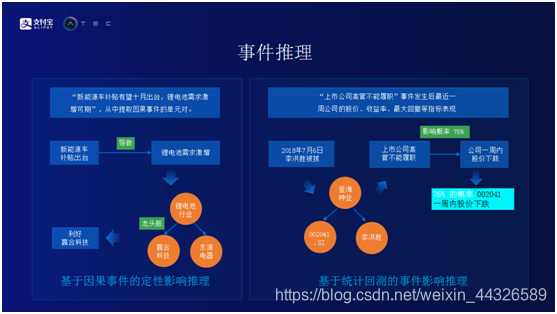
情感分析。情感分析實際上分兩類,篇章級和實體級。篇章級指的是給定一段文本,判斷這段文本情感上是正面還是負面。實體級情感分析是給定一段文本和句子,同時給定一個實體,判斷這段文本和句子對實體的影響是正面還是負面的。
篇章級的情感分析主要有兩條通路。基於情感知識庫通路和基於機器算法通路。基於情感知識庫通路可以理解爲有一堆規則模板,從文章中會抽取出若干個情感單元,計算情感單元計情感分,最後彙集起來得到這篇文章的情感分。基於機器學習通路使用傳統的機器學習方法和深度學習方法,把文章直接映射到它的情感分,最後把兩條通路得到的情感分進行加權,一併輸出,作爲整個篇章級的情感分。
實體級的情感分析也有兩條通路。第一條是直接確定,它依存語法分析,建立語法樹,通過事件要素提取,得到文章對實體是正面還是負面的影響。另外一條是通過概率相關方式,如採用啓發式方法,根據情感信息與對象實體的距離,篇章結構關係等,得到所對應的情感分。用戶查詢基金501000,即中國平安,系統瞭解到中國平安最近發生了“平安好醫生申請IPO”事件,這個事件對中國平安是偏利好的事件,所以可以告訴用戶“平安好醫生申請IPO”事件對該基金的影響度是四星。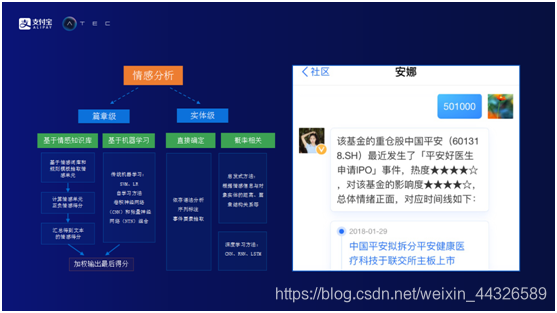
3. 服務分發
瞭解了用戶意圖和有了足夠的內容之後,現在可以反饋用戶,即服務分發。服務分發解決三個問題,給用戶提供什麼樣的服務?怎麼給用戶提供這個服務?在什麼時候給用戶提供這個服務?這部分工作是基於比較成熟的算法,基本上整體過程是召回,干預,召回和再幹預。如下圖,在使用螞蟻財富的APP時,資深投資人都在看系統推薦的內容,這部分內容和服務都是動態的,系統可以根據用戶的個人喜好,推薦的最適合的信息和服務。
4. 智能投顧
資產配置
完成了感知用戶意圖,生成豐富內容和服務分發之後,就和用戶建立了一定的信用關係,其中某些用戶已經購買了一些金融產品。螞蟻財富想更進一步結合金融工程與AI機器學習,完成優質資產組合,爲客戶量身打造資產配置方案。資產配置方案第一步是進行數據彙集。其中有三類數據,一類來自市場上的公開數據,放在資產檔案中。另外一類是機構數據。螞蟻金服作爲一個科技公司,一直信奉的觀點是讓專業人去做專業的事,螞蟻金服相信這些金融機構在金融領域的專業性和權威性。希望通過螞蟻財富號,將金融機構的觀點引入到螞蟻系統中,幫助螞蟻財富更加全面的對市場進行宏觀和微觀分析。最後一類是輿情觀點數據,即在內容生產階段拿到的關於輿情的信息。通過數據彙總,對數據進行特徵提取,包括衍生特徵計算,時序特徵歸納,和機構的觀點量化。假設機構觀點不可量化,在這一步首先要將機構的觀點進行量化。特徵提取以後會得到超高維的特徵集,由於超高維的特徵集並不能夠直接被用來預測市場走勢,所以在下一步採取傳統的分析方法或者人工智能算法,對超高維的特徵集做聚類,相關性分析和迴歸分析,生成相應的因子,相應因子纔是真正可以用來做市場預測。得到相關因子之後,配合常見的模型,如MPT,ML等,生成各種各樣的投資組合,它們適用於不同投資風格投資者。最後通過研究用戶的行爲,採取匹配算法,得到最適合用戶的投資組合。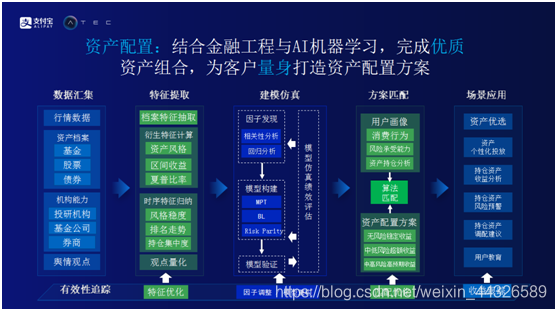
點擊閱讀更多,查看更多詳情