




原文 關於深度學習中的注意力機制,這篇文章從實例到原理都幫你參透了 不能轉載.
attention機制源於人類快速處理視覺信息的大腦機制.通過重點關注目標區域,抑制無關區域,從而從大量信息中快速篩選出有價值的信息
Encoder-Decoder 框架
目前attention機制主要依賴於encoder-decoder框架
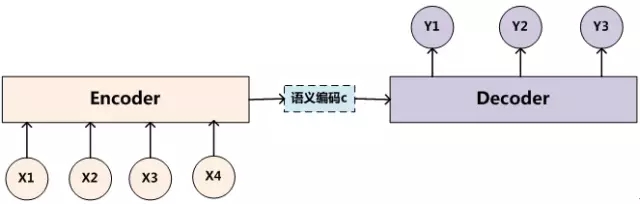
上圖爲Encoder-Decoder框架的抽象表示.
Encoder-Decoder框架可以看成一個由句子(段落,圖片)生成另一個句子(段落、圖片、字符串)的通用模型.
以在文本處理領域中機器翻譯應用爲例,對於句子對<source,target>,由source生成target。source爲語言A,source爲語言B,source爲單詞序列{X1,X2,X3,X4},target爲單詞序列{Y1,Y2,Y3}。
Encoder用於對source進行編碼,通過非線性變換得到中間矩陣C

Decoder用於解碼生成target,其任務是根據句子X的中間語義表示C和之前已經生成的歷史信息y1,y2….yi-1來生成i時刻要生成的單詞yi

每個yi都依次這麼產生,那麼看起來就是整個系統根據輸入句子X生成了目標句子Y。

原始的Encoder-Decoder在生成每個 
因此引入attention機制,使得source中的每個單詞對輸出的不同單詞具有不同權重的影響。
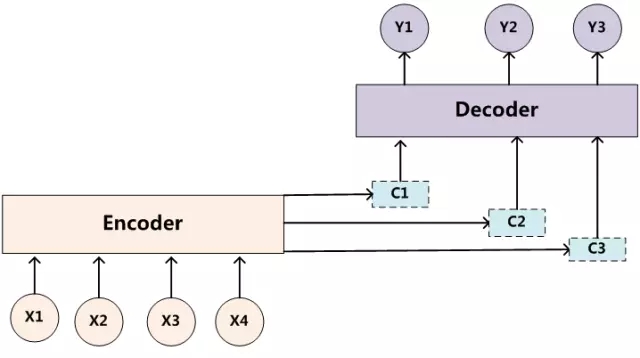
在翻譯“傑瑞”的時候,體現出英文單詞對於翻譯當前中文單詞不同的影響程度,比如給出類似下面一個概率分佈值:
(Tom,0.2)(Chase,0.1) (Jerry,0.5)
即生成目標句子單詞的過程成了下面的形式:

而每個Ci可能對應着不同的源語句子單詞的注意力分配概率分佈,比如對於上面的英漢翻譯來說,其對應的信息可能如下:

其中,f2函數代表Encoder對輸入英文單詞的某種變換函數,比如如果Encoder是用的RNN模型的話,這個f2函數的結果往往是某個時刻輸入 

假設Ci中那個i就是上面的“湯姆”,那麼Tx就是3,代表輸入句子的長度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),對應的注意力模型權值分別是0.6,0.2,0.2,所以g函數就是個加權求和函數。如果形象表示的話,翻譯中文單詞“湯姆”的時候,數學公式對應的中間語義表示Ci的形成過程類似下圖:

這裏還有一個問題:生成目標句子某個單詞,比如“湯姆”的時候,如何知道Attention模型所需要的輸入句子單詞注意力分配概率分佈值呢?就是說“湯姆”對應的輸入句子Source中各個單詞的概率分佈:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
爲了便於說明,我們假設對圖2的非Attention模型的Encoder-Decoder框架進行細化,Encoder採用RNN模型,Decoder也採用RNN模型,這是比較常見的一種模型配置,則圖2的框架轉換爲圖5。
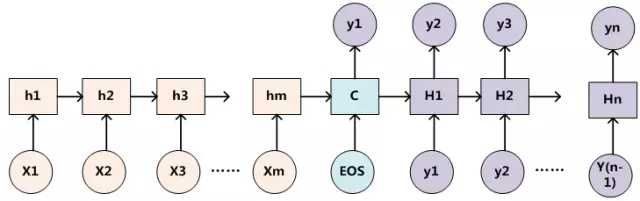

對於採用RNN的Decoder來說,在時刻 





常用的 F 函數包括 dot、general、concat和MLP。
Attention機制的本質
把Attention機制從上文講述例子中的Encoder-Decoder框架中剝離,並進一步做抽象,可以更容易看懂Attention機制的本質思想。
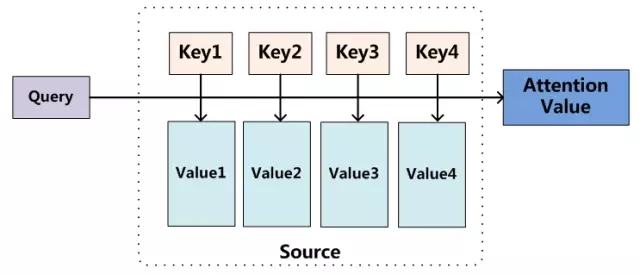
我們可以這樣來看待Attention機制(參考圖9):將Source中的構成元素想象成是由一系列的<Key,Value>數據對構成,此時給定Target中的某個元素Query,通過計算Query和各個Key的相似性或者相關性,得到每個Key對應Value的權重係數,然後對Value進行加權求和,即得到了最終的Attention數值。所以本質上Attention機制是對Source中元素的Value值進行加權求和,而Query和Key用來計算對應Value的權重係數。即可以將其本質思想改寫爲如下公式:

當然,從概念上理解,把Attention仍然理解爲從大量信息中有選擇地篩選出少量重要信息並聚焦到這些重要信息上,忽略大多不重要的信息,這種思路仍然成立。聚焦的過程體現在權重係數的計算上,權重越大越聚焦於其對應的Value值上,即權重代表了信息的重要性,而Value是其對應的信息。
至於Attention機制的具體計算過程,如果對目前大多數方法進行抽象的話,可以將其歸納爲兩個過程:第一個過程是根據Query和Key計算權重係數,第二個過程根據權重係數對Value進行加權求和。而第一個過程又可以細分爲兩個階段:第一個階段根據Query和Key計算兩者的相似性或者相關性;第二個階段對第一階段的原始分值進行歸一化處理;這樣,可以將Attention的計算過程抽象爲如圖10展示的三個階段。
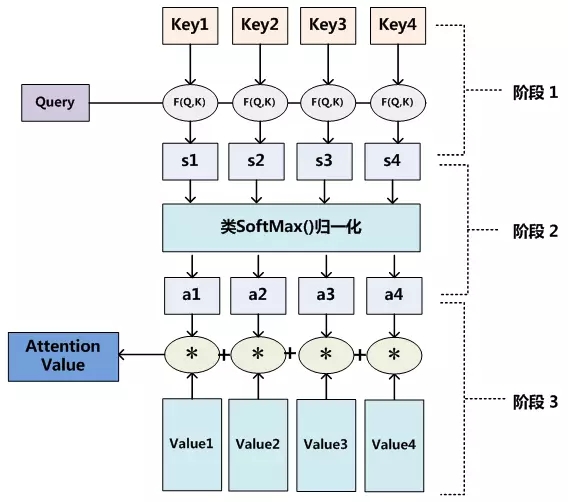
圖10 三階段計算Attention過程
在第一個階段,可以引入不同的函數和計算機制,根據Query和某個keyi,計算兩者的相似性或者相關性,最常見的方法包括:求兩者的向量點積、求兩者的向量Cosine相似性或者通過再引入額外的神經網絡來求值,即如下方式:

第一階段產生的分值根據具體產生的方法不同其數值取值範圍也不一樣,第二階段引入類似SoftMax的計算方式對第一階段的得分進行數值轉換,一方面可以進行歸一化,將原始計算分值整理成所有元素權重之和爲1的概率分佈;另一方面也可以通過SoftMax的內在機制更加突出重要元素的權重。即一般採用如下公式計算:

通過如上三個階段的計算,即可求出針對Query的Attention數值,目前絕大多數具體的注意力機制計算方法都符合上述的三階段抽象計算過程。