




基本正則表達式
格式:grep [options] 'PATTERF' file
--color=auto 匹配到的選項帶顏色顯示
-q 靜默模式,不輸出任何信息
-v 匹配反向,顯示不能被匹配到的行
-o 僅顯示匹配到的選項,並不是顯示正行
-i 匹配時忽略大小寫
-E 使用擴展的正則表達式
-A NUM 顯示匹配到行的後NUM行
-B NUM 顯示匹配到行的前NUM行
-C NUM 顯示匹配到行的前後各NUM行
-m # 匹配#次後停止
-n 顯示匹配的行號
-w 匹配整個單詞
-f file 根據模式文件處理
-c 統計匹配的行數
-e 實現多個選項間的邏輯or關係 例如:grep –e ‘cat ’ -e ‘dog’ file
元字符:
. 匹配任意單個字符
[] 匹配範圍內的單個字符
[^] 匹配範圍外的單個字符
[0-9] [:digit:] 數字
[a-z] [:lower:] 小寫字母
[A-Z] [:upper:] 大寫字母
[:alpha:] 大小寫字母
[:alnum:] 大小寫字母及數字
[:space:] 空格
[:punct:] 標點符號
匹配次數:
次數匹配:用來指定匹配其前面的字符的次數
貪婪模式:儘可能的長的去匹配字符:
* 例子:x*y
xxy xy y 都能匹配
.* 匹配任意長度任意字符
\? 匹配其前字符0次或者1次
\+ 匹配其前字符至少1次
\{m\}:匹配m次
\{m,\n}:至少m次,至多n次
\{m,\}:至少m次
\{0,\n}:至多n次
位置錨定:
用於指定字符出現的位置
^:錨定行首 ^Char
$:錨定行尾 grepchar$
^$:空白行
單詞的位置錨定
\<char :錨定詞首,\bchar
char\> : 錨定詞尾,char\b
分組:
\ (\)
\(ab\)*xy
\|:或者,ac\|bc ac或者bc
引用:
\1:後向引用,引用前面的第一個左括號以及與之對應的右括號中的模式匹配到的內容,意思是說前面出現一次,在\1這也要出現一次
練習:
1、顯示/proc/meminfo文件中的以大小寫s的開頭的行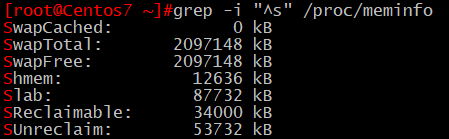
2、取出默認shell爲非bash的用戶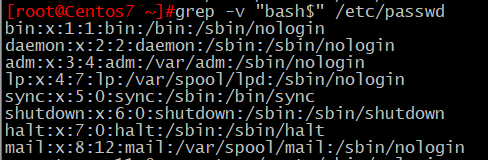
3、取出默認shell爲bash的且其ID號最大的用戶
4、顯示/etc/grub2.cfg文件中,以#開頭,後面跟至少一個空白字符,而後又有至少一個非空白字符的行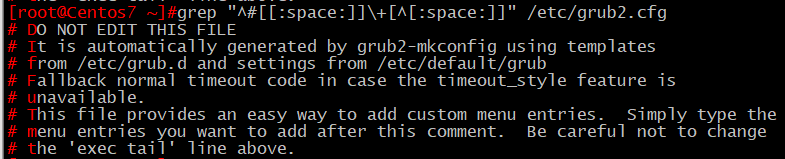
5、顯示/boot/grub/grub.conf中以至少一個空白字符的行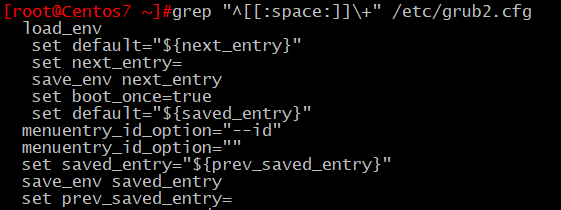
6、查出/etc/passwd中一位數或兩位數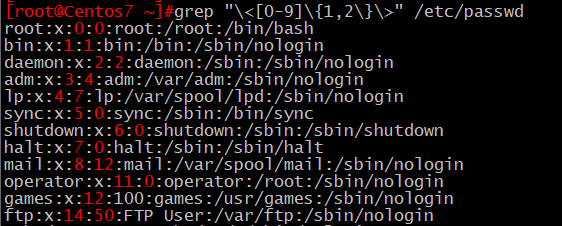
7、找出ifconfig命令結果中的1到255之間的整數
9、添加用戶bash和testbash,而後找出當前系統上於其他用戶名和默認shell相同的用戶


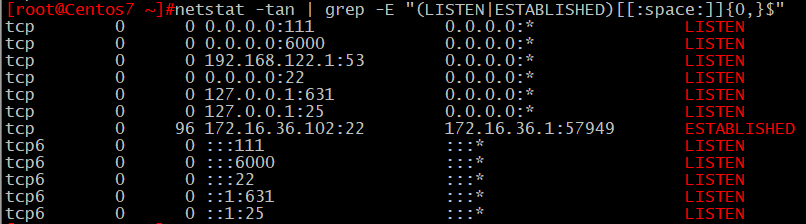
10、找出netstat -tan命令執行的結果中以“LISTEN”或“ESTABLISHEN”結尾的行
11、取出當前系統上所有用戶的shell,要求:每種shell中顯示一次,且升序排序顯示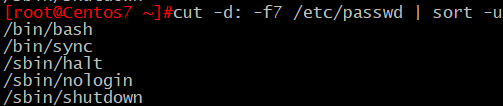
12、掃描172.18.120.0/24⽹段,顯⽰在線的ip地址
[root@Centos7 ~]# nmap -sP 172.18.120.0/24 | grep -B1 'Host is up'| grep for | cut -d" " -f5 172.18.120.7
172.18.120.17
172.18.120.27
172.18.120.254
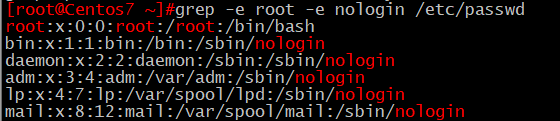
13.顯⽰/root/passwd⽂件中,包含root字串或包含nologin字串的⾏
14.匹配root整個單詞
15.過濾ipconfig命令輸出的所有ip地址
16.找出/etc/rc.d/init.d/functions⽂件中⾏⾸爲某單詞(包括下劃線)後⾯跟⼀個⼩括號的⾏
17.將此字符串:welcome to magedu linux 中的每個字符去重並排序,重複次數多的排到前⾯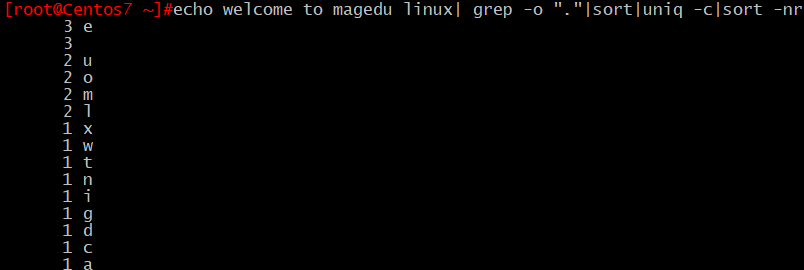
擴展正則表達式
egrep:使用擴展正則表達式來構建模式,相當於 grep -E
元字符:同正則表達式,位置牟定同正則表達式
字符匹配:
.:任意單個字符
[]:指定範圍內的任意單個字符
[^]:指定範圍外的任意單個字符
次數匹配
*:匹配器前面的字符任意次
?:匹配器前面的字符0或1次
+:匹配其前面字符至少一次
{m}:匹配其前面字符m次
{m,n}:至少m次,至多n次
{m,}:至少m次
{0,n}:只讀n次
分組:
():分組
|:或者,ac|bc ac或者bc