




緩存的重要性:
什麼是緩存:
cache,電腦中爲[高速緩衝存儲器],是位於[CPU]和[主存儲器]DRAM(Dynamic Random Access Memory)之間,規模較小,但速度很高的存儲器,通常由[SRAM](Static Random Access Memory 靜態存儲器)組成。它是位於CPU與內存間的一種容量較小但速度很高的存儲器。CPU的速度遠高於內存,當CPU直接從內存中存取數據時要等待一定時間週期,而Cache則可以保存CPU剛用過或循環使用的一部分數據,如果CPU需要再次使用該部分數據時可從Cache中直接調用,這樣就避免了重複存取數據,減少了CPU的等待時間,因而提高了系統的效率。
說白了就是把經常使用的數據放進緩存,由於緩存在CPU中比內存還快,當下次使用時直接從緩存提取即可,這樣就減少了等待時間所以就很快,那麼web的集羣我們經常訪問的一些靜態頁面或者說一些不經常變化的動靜態數據都可以進行緩存,由於緩存系統特殊的管理機制,訪問效率會較於之前高出很多,這樣就可以有效的提高訪問效率,減少後端web集羣的訪問壓力
爲什麼要用緩存:
當訪問量與web集羣自身可以服務的數量,二者形成較大差距時就需要引入緩存來緩解後端壓力,當然也不是所有數據都可以引入緩存,因爲緩存意味着短時間內被緩存數據將不會被髮生變化,如果被緩存數據仍然極高頻度的發生變化那麼緩存只會徒勞增加網絡IO,那麼合適的場景下引用緩存將提升網站響應速度,減少後端web集羣的訪問壓力能夠有效的提升併發能力
引用緩存前的模樣:
用戶 --> nginx --> php --> mysql
這裏沒有緩存每一次都會進行一次完整的訪問引用緩存後的模樣:
用戶 --> cache --> nginx --> php --> mysql
引入緩存後,用戶請求的數據如果cache中有將不會進行訪問nginx,立即返回給用戶web集羣中如何用緩存:
web緩存方案一般常見的就是varnish和squid,當然nginx也算不過不是專業的緩存,畢竟要依賴第三方模塊,而前者則是比較成熟的專業的方案選擇,但是現在比較推崇的是varnish不過也是有原因的,以挪威一家報社的經驗,3臺varnish可以抵12臺squid的性能...
Varnish是一款高性能的開源HTTP加速器(其實就是帶緩存的反向代理服務),可以把http響應內容緩存到內存或文件中,從而提高web服務器響應速度。與傳統的 squid 相比,varnish 具有性能更高、速度更快、管理更加方便等諸多優點,很多大型的網站都開始嘗試使用 varnish 來替換 squid,這些都促進 varnish 迅速發展起來。
既然varnish可以理解反向代理那麼一些反向代理的功能他同樣是具備的:除了自身的緩存管理以外,同樣支持多後端主機的調度,cookie會話保持,讀寫分離和健康狀態監測等等
varnish的組成結構:

Varnish是一款高性能的開源HTTP加速器(其實就是帶緩存的反向代理服務),可以把http響應內容緩存到內存或文件中,從而提高web服務器響應速度。與傳統的 squid 相比,varnish 具有性能更高、速度更快、管理更加方便等諸多優點,很多大型的網站都開始嘗試使用 varnish 來替換 squid,這些都促進 varnish 迅速發展起來。[挪威]最大的在線報紙 Verdens Gang 使用3臺Varnish代替了原來的12臺Squid,性能比以前更好。
-
主要由核心守護進程varnishd組成
-
Manager Process ## 管理進程,相當於nginx的主控進程,不處理用戶請求,提供用戶CLI接口用於管理
-
Cacher Process ## 緩存進程
- 線程Storage:完成緩存存儲管理
- 線程Log/Stats:日誌記錄----->存入共享內存Shared Memory Log中
- 線程Worker threads:真正處理用戶請求,通過線程池來定義,最大併發(線程池*線程池最大併發)
-
shared memory log
- varnishlog:讀取日誌文件,保存在磁盤中
- varnishstat:讀取統計數據,計數器
-
VCL配置接口:varnish配置語言,連接Manager Process
- varnishadm:讓varnish加載新配置文件
-
VCC Process:varnish的c編譯器
整體流程:
用戶通過varnishadm工具連接Manager Process的CLI接口來配置管理,完成後由VCC Process進行C-ompiler編譯成Shared Object(共享對象)提供給Worker threads(工作線程)來使用,再後來就是一些常規日誌處理(環形處理)
Varnish的請求處理流程:
varnish工作在集羣的最前端,對於用戶的請求大概要經過這麼一個流程進行判斷,所有以橢圓標註爲varnish的引擎,這裏很關鍵,因爲後續的策略就是要在指定的引擎中配置
原理圖:
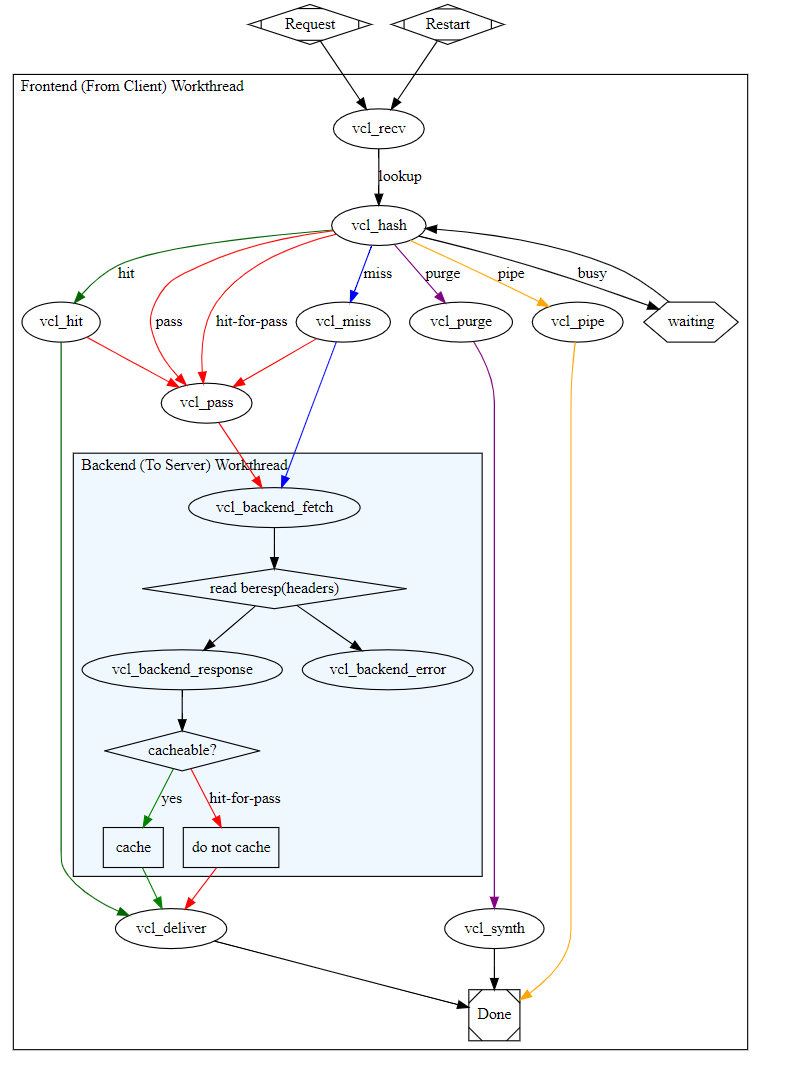
請求到達vcl_recv進行vcl_hash判斷若可以命中到緩存vcl_hit則直接交付vcl_deliver,否則進入vcl_miss未命中狀態,進入後端獲取vcl_backend_fetch,進行read beresp(header)讀請求頭判斷,正常則進行vcl_backend_response響應(此時會去後端訪問數據),響應後判斷是否進行緩存,若緩存則cache,否則do not cache進入vcl_deliver(交付),完成請求。
-
vcl_recv收到請求,查找vcl_hash
-
若命中(傳遞值hit),交由vcl_hit
-
hit命中,直接從緩存中響應,交由vcl_deliver投遞給客戶端
-
未命中(傳遞值miss),交由vcl_miss
-
交由vcl_backend_fetch請求後端服務器 vcl_hash -(miss)-> vcl_miss --> vcl_backend_fetch --> vcl_backend_response --> vcl_deliver(中間判斷是否對數據進行緩存)
- vcl_hit和vcl_miss也能交由給pass
-
-
若要刪除緩存項(傳遞值purge),交由vcl_purge - 交由vcl_synh管理緩存,刪除對應緩存 - vcl_hash -(purge)-> vcl_purge --> vcl_synth
-
若不能理解請求(傳遞值pipe),交由vcl_pipe,請求被直接送至後端服務器 - vcl_hash -(pipe)-> vcl_pipe
-
兩個特殊引擎:
- vcl_init:在處理任何請求之前要執行的vcl代碼:主要用於初始化vMODS
- vcl_fini:所有的請求都已經結束,在vcl配置被丟棄時調用,主要用於清理vMODS
如果還不明白則可以參照大表哥的漢化手繪版本,不過沒有官方的詳細
參考鏈接:<https://blog.51cto.com/ximenfeibing/1672204>

varnish的三種緩存存儲機制( Storage Types):
· malloc[,size]
內存存儲,[,size]用於定義空間大小;重啓後所有緩存項失效;
· file[,path[,size[,granularity]]]
磁盤文件存儲,黑盒;重啓後所有緩存項失效;
· persistent,path,size
文件存儲,黑盒;重啓後所有緩存項有效;實驗;varnish安裝基本使用
安裝包已由epel源提供,目前Centos7上提供爲4.0版本
[root@localhost ~]# yes|yum install varnish
...
軟件包 varnish-4.0.5-1.el7.x86_64 已安裝並且是最新版本無須任何處理
官方網址:http://varnish-cache.org/
4.0手冊:http://book.varnish-software.com/4.0/
varnish的主配置文件:
[root@localhost ~]# ls /etc/varnish/
default.vcl ##配置varnish緩存策略配置文件
secret ##證書文件,在CLI配置時需要指定該文件驗證
varnish.params ##關於varnish程序自身的管理,比如端口...
varnish類似於iptables,對用戶的請求層層過濾,每一層都要進行策略匹配,CLI配置工具varnishadm
配置方式一(交互式):
[root@localhost ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082
配置方式二(指令式):
[root@localhost ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082 vcl.load t4 /etc/varnish/default.vcl
varnishadm介紹:
程序選項:/etc/varnish/varnish.params文件
-a address[:port][,address[:port][...],默認爲6081端口;
-T address[:port],默認爲6082端口;
-s [name=]type[,options],定義緩存存儲機制;
-u user
-g group
-f config:VCL配置文件;
-F:運行於前臺;
...
運行時參數:/etc/varnish/varnish.params文件, DEAMON_OPTS
DAEMON_OPTS="-p thread_pool_min=5 -p thread_pool_max=500 -p thread_pool_timeout=300"
-p param=value:設定運行參數及其值; 可重複使用多次;
-r param[,param...]: 設定指定的參數爲只讀狀態;
重載vcl配置文件:
~ ]# varnish_reload_vcl ##也可以在交互式中load-->use幫助信息:
[root@localhost ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082
varnish> help ##獲取幫助
help [<command>]
ping [<timestamp>]
auth <response>
quit
banner
status
start
stop
vcl.load <configname> <filename> ##從default.vcl中加載配置並定義版本標籤,不同版本標籤在不重啓服務可切換使用
vcl.inline <configname> <quoted_VCLstring>
vcl.use <configname> ##切換當前使用vcl文件,必須先load
vcl.discard <configname> ##刪除某個版本配置文件標籤
vcl.list ##查看當前可切換的配置文件標籤
param.show [-l] [<param>] ##查看varnish程序的當前運行參數
param.set <param> <value> ##不停止服務修改程序運行參數,重啓服務後失效
panic.show
panic.clear
storage.list ##查看當前存儲狀態信息
vcl.show [-v] <configname> ##查看當前vcl配置信息,加參數v顯示缺省配置
backend.list [<backend_expression>] ##查看後端主機列表及健康狀態信息
backend.set_health <backend_expression> <state> ##設置後端主機健康狀態信息(Sick|Healthy)
ban <field> <operator> <arg> [&& <field> <oper> <arg>]... ##緩存清理工具,不過還有其他方法
ban.list
varnish> help vcl.load ##獲取vcl.load幫助
varnish> vcl.<tab> ##自動補全提示
vcl.discard vcl.inline vcl.list vcl.load vcl.show vcl.use
VCL中的內置變量
內建變量:
req.*:request,表示由客戶端發來的請求報文相關;
req.http.*
req.http.User-Agent, req.http.Referer, ...
bereq.*:由varnish發往BE(backend)主機的httpd請求相關;
bereq.http.*
beresp.*:由BE主機響應給varnish的響應報文相關;
beresp.http.*
resp.*:由varnish響應給client相關;
obj.*:存儲在緩存空間中的緩存對象的屬性;只讀;
常用變量:
req.*:
req.http.HEADERS
req.request:請求方法;
req.url:請求的url;
req.proto:請求的協議版本;
req.backend:指明要調用的後端主機;
req.http.Cookie:客戶端的請求報文中Cookie首部的值;
req.http.User-Agent ~ "chrome"
bereq.* :
bereq.http.HEADERS
bereq.request:請求方法;
bereq.url:請求的url;
bereq.proto:請求的協議版本;
bereq.backend:指明要調用的後端主機;
resp.*:
resp.http.HEADERS
resp.status:響應的狀態碼;
resp.proto:協議版本;
resp.backend.name:主機的主機名;
resp.ttl:主機響應的內容的餘下的可緩存時長;
beresp.* :
beresp.http.HEADERS
beresp.status:響應的狀態碼;
reresp.proto:協議版本;
beresp.backend.name:BE主機的主機名;
beresp.ttl:BE主機響應的內容的餘下的可緩存時長;
obj.*
obj.hits:此對象從緩存中命中的次數;
obj.ttl:對象的ttl值
server.*
server.ip:varnish主機的IP;
server.hostname:varnish主機的Hostname;
client.*
client.ip:發請求至varnish主機的客戶端IP;
注:同樣可以自定義變量
set 自定義變量
unset 取消設置操作符:
==, !=, ~, >, >=, <, <=
邏輯操作符:&&, ||, !
變量賦值:=varnish常見配置場景:
添加報頭在響應信息中判斷是否命中:
舉例:obj.hits是內建變量,用於保存某緩存項的從緩存中命中的次數;我們添加在響應報文中用來判斷是否從命中緩存
if (obj.hits>0) {
set resp.http.X-Cache = "HIT via" + " " + server.ip + obj.hits; ##HIT表示未命中,提供cache服務器地址,命中次數
} else {
set resp.http.X-Cache = "MISS from " + server.ip + obj.hits;
}
這裏等於添加了一個自定義報頭信息(X-Cache可自定義),來判斷是否命中以及命中服務器並且顯示次數示例1:強制對某類資源的請求不檢查緩存,定義在vcl_recv中;:
vcl_recv {
if (req.url ~ "(?i)^/(login|admin)") {
return(pass);
}
}
示例2:對於特定類型的資源,例如公開的圖片等,取消其私有標識,並強行設定其可以由varnish緩存的時長; 定義在vcl_backend_response中;
if (beresp.http.cache-control !~ "s-maxage") {
if (bereq.url ~ "(?i)\.(jpg|jpeg|png|gif|css|js)$") {
unset beresp.http.Set-Cookie;
set beresp.ttl = 3600s;
}
}
示例3:定義在vcl_recv中;
if (req.restarts == 0) {
if (req.http.X-Forwarded-For) {
set req.http.X-Forwarded-For = req.http.X-Forwarded-For + "," + client.ip;
} else {
set req.http.X-Forwarded-For = client.ip;
}
} varnish關於緩存裁剪:
緩存裁剪的四種方法:
方法一:PURGE
在vcl中默認有一個狀態引擎purge,需要在req.recv中添加判斷,對請求的信息url如果是PURGE這種請求則直接進行緩存清理,此訪問的url請求強制緩存失效並清理
sub vcl_purge {
return (synth(200, "Purged"));
}
配置方法:##由於緩存清理安全性,限定來源IP來控制緩存清理這個敏感操作
vcl 4.0;
acl purgers { ##定義可操作的ip或段
"127.0.0.1";
"192.168.2.0"/24;
}
sub vcl_recv {
if (req.method == "PURGE") {
if (!client.ip ~ purgers) {
return (synth(405, "Purging not allowed for " + client.ip));
}
return (purge);
}
}
注:curl -X 指定請求類型
curl -I 只打印方法二:BAN
banning是一種非常靈活的緩存清理方法,可以在console中使用,也可以定義在配置文件中像PURGE一樣
ban req.url ~ ^/news
ban req.url ~ ^/news && req.http.host "ilinux.io"
ban req.url ~ .js$ && req.http.host "ilinux.io"
ban req.url == /
寫入配置文件中
sub vcl_recv {
if (req.method == "BAN") {
if (!client.ip ~ purgers) {
ban("req.http.host == " + req.http.host + " && req.url == " + req.url);
# Throw a synthetic page so the request won't go to the backend.
}
return(synth(200, "Ban added"));
}
}
注:其實就是類似於ban req.http.host == 192.168.2.128 && req.url == /javascripts方法三:判斷強制不訪問緩存
vcl_recv {
if (req.url ~ "(?i)^/(login|admin)") {
return(pass);
}
}Varnish的後端主機管理:
添加多臺後臺主機:
添加多臺主機需要藉助directors模塊,這裏添加的步驟爲
導入調度模塊並定義主機-->實例化主機組對象算法-->實例化對象添加主機-->vcl_recv調用主機組
實例化及各種定義過程應在vcl_recv與語法聲明之間完成
vcl 4.0; ##語法聲明
import directors; ##倒入調度器模塊
probe www { #定義健康狀態
.url="/"; ##檢測時要請求的URL,默認爲”/";
.timeout=1s; ##超時時間
.interval=1s; ##重新健康狀態檢測間隔
.window=8; ##基於最近的多少次檢查來判斷其健康狀態;
.threshold=5; ##最近.window中定義的這麼次檢查中至有.threshhold定義的次數是成功的;
}
backend one {
.host = "192.168.2.129";
.port = "8080";
.probe = www; ##調用健康檢查策略,主機不同可調用不同的健康判斷策略
}
backend two {
.host = "192.168.2.130";
.port = "8080";
.probe = www;
}
backend three {
.host = "192.168.2.131";
.port = "8080";
.probe = www;
}
backend default {
.host = "192.168.2.129";
.port = "8080";
}
sub vcl_init {
new websrv = directors.round_robin(); ##實例化主機組對象算法(輪詢,但不支持權重)
websrv.add_backend(one); ##添加主機
websrv.add_backend(two);
websrv.add_backend(three);
new appsrv = directors.random(); ##實例化主機組對象算法(隨機)
appsrv.add_backend(one,10);
appsrv.add_backend(two,5);
}
sub vcl_recv {
set req.backend_hint = appsrv.backend(); ##在請求開始的最前端聲明主機組,或動靜分離的聲明
...
}動靜分離配置
配置動靜分離的前提是架構已經將靜態頁面和動態頁面拆分開來,這裏我們在配置中定義兩個主機羣組
vcl 4.0; ##語法聲明
import directors; ##倒入調度器模塊
probe www { #定義健康狀態
.url="/"; ##檢測時要請求的URL,默認爲”/";
.timeout=1s; ##超時時間
.interval=1s; ##重新健康狀態檢測間隔
.window=8; ##基於最近的多少次檢查來判斷其健康狀態;
.threshold=5; ##最近.window中定義的這麼次檢查中至有.threshhold定義的次數是成功的;
}
backend sta_1 {
.host = "192.168.2.129";
.port = "8080";
.probe = www; ##調用健康檢查策略,主機不同可調用不同的健康判斷策略
}
backend php_1 {
.host = "192.168.2.130";
.port = "8080";
.probe = www;
}
backend php_2 {
.host = "192.168.2.131";
.port = "8080";
.probe = www;
}
backend default {
.host = "192.168.2.129";
.port = "8080";
}
sub vcl_init {
new stasrvs = directors.round_robin(); ##實例化主機組對象算法
stasrvs.add_backend(sta_1); ##添加主機
new phpsrvs = directors.hash(); ##實例化主機組對象算法(對)
phpsrvs.add_backend(php_1,1); ##主機,權重
phpsrvs.add_backend(php_2,1);
}
sub vcl_recv {
if (req.url ~ "(?i)\.(css|js|jpg|jpeg|png|gif)$" { ##如果爲列表中結尾則發送到stasrvs後端查詢數據
set req.backend_hint = stasrvs.backend();
} else { ##不滿足上一個條件判定爲動態內容,根據cookie進行查詢動態主機並進行服務
set req.backend_hint = phpsrvs.backend(req.http.cookie);
}
}健康狀態檢查
backend BE_NAME {
.host =
.port =
.probe = {
.url=
.timeout=
.interval=
.window=
.threshold=
}
}
.probe:定義健康狀態檢測方法;
.url:檢測時要請求的URL,默認爲”/";
.request:發出的具體請求;
.request =
"GET /.healthtest.html HTTP/1.1"
"Host: www.magedu.com"
"Connection: close"
.window:基於最近的多少次檢查來判斷其健康狀態;
.threshold:最近.window中定義的這麼次檢查中至有.threshhold定義的次數是成功的;
.interval:檢測頻度;
.timeout:超時時長;
.expected_response:期望的響應碼,默認爲200;
健康狀態檢測的配置方式:
(1) probe PB_NAME { } ##建議採用該方法,比較清晰
backend NAME {
.probe = PB_NAME;
...
}
(2) backend NAME {
.probe = {
...
}
}varnish的併發配置:
關於併發這塊的配置,其實和web服務器差不多,只不過每個產品的名稱不一樣罷了,這裏簡單介紹一下併發設置線程池的一些配置:
聲明:屬於varnish.params的一些參數,所以配置方式有兩種:
修改配置文件(需要重啓服務,永久有效)
在varnish.params中的DAEMON_OPTS後追加
DAEMON_OPTS="-p thread_pool_min=5 -p thread_pool_max=500 -p thread_pool_timeout=300"
在CLI接口中配置(服務重啓失效)
線程池相關:
線程相關的參數:使用線程池epoll機制管理線程;在線程池內部,其每一個請求由一個線程來處理; 其worker線程的最大數決定了varnish的併發響應能力;
官方資料:<http://book.varnish-software.com/4.0/chapters/Tuning.html#the-parent-process-the-manager>
最大併發連接數 = thread_pools * thread_pool_max
thread_pools:工作線程池數量,最好小於或等於CPU核心數量;
thread_pool_max:每線程池的最大線程數;
thread_pool_min:額外意義爲“最大空閒線程數”;
thread_pool_timeout:線程空閒閾值。當線程處於空閒並且大於thread_pool_min值時多久進行清理,缺省300s;
thread_pool_add_delay:創建線程猶豫時間,缺省0s;
thread_pool_destroy_delay:在沒有請求時清理空閒線程的猶豫時間,在猶豫期間內防止突然併發上升,畢竟線程創建一下子成本也很高,缺省1s;計時器相關:
** send_timeout:發送客戶端連接超時。如果在這麼多秒內沒有傳輸HTTP響應,則會話關閉。當反代客戶端多久不響應varnish服務端,服務端關閉本次會話。缺省600s;
*** timeout_idle:客戶端連接的空閒超時,這裏指的是keep-alive會話保持,缺省5s;建議設置時間可以加大,這樣可以提高套接字複用,減少三次握手提升性能
timeout_req: 接收客戶端請求報文首部的最長時間。缺省2s;
cli_timeout:使用varnishadm連接CLI的會話超時時間。varnish日誌相關:
varnish的日誌在內存中環形記錄,是實時顯示的,默認是不進行落地記錄的,如果需要記錄則需要額外配置,或者epel進行yum安裝的需要啓動另外的systemd服務纔會進行記錄。這一塊不做仔細說明,因爲varnish一般承載的都是大的流量訪問,如果一旦開啓日誌記錄,磁盤io會很快成爲瓶頸,需要配置可以參考寫的非常詳細:<http://blog.chinaunix.net/uid-30212356-id-5711492.html>
[root@localhost ~]# rpm -ql varnish|grep service
/usr/lib/systemd/system/varnish.service ##服務主程序
/usr/lib/systemd/system/varnishlog.service ##varnishlog 用於記錄varnish 自身定義的日誌格式
/usr/lib/systemd/system/varnishncsa.service ##varnishncsa 用於記錄作類似apache/ncsa定義的日誌格式實時日誌的查看:
varnishstat
varnishstat實用程序顯示正在運行的varnishd(1)實例的統計信息。
參考:<http://varnish-cache.org/docs/trunk/reference/varnishstat.html#varnishstat-1>
1、varnishstat - Varnish Cache statistics
-1 ##因爲是享top一樣實時顯示,-1表示打印成靜態進行顯示輸出
-1 -f FILED_NAME ##varnishstat統計信息較多,但是可以分類,比如MAIN.*和MEMPOOL.*等等
-l:可用於-f選項指定的字段名稱進行列表顯示;
MAIN.cache_hit ##查看命中次數
MAIN.cache_miss ##查看未命中次數
# varnishstat -1 -f MAIN.cache_hit -f MAIN.cache_miss
顯示指定參數的當前統計數據;
# varnishstat -l -f MAIN -f MEMPOOL
列出指定配置段的每個參數的意義;
varnishtop
varnishtop實用程序讀取varnishd共享內存日誌,並顯示最常出現的日誌條目的持續更新列表。與使用合適的濾波-I,-i,-X 和-x的選擇,它可以被用來顯示要求的文件,客戶端,用戶代理,或被記錄在日誌中的任何其他信息的等級。
2、varnishtop - Varnish log entry ranking
-1 Instead of a continously updated display, print the statistics once and exit.
-i taglist,可以同時使用多個-i選項,也可以一個選項跟上多個標籤;
-I <[taglist:]regex>:對指定的標籤的值基於regex進行過濾;
-x taglist:排除列表
-X <[taglist:]regex>:對指定的標籤的值基於regex進行過濾,符合條件的予以排除;
varnishlog和varnishncsa
兩種日誌格式也沒的說,一般開啓varnishncsa
varnishlog參考鏈接:<http://varnish-cache.org/docs/trunk/reference/varnishlog.html#varnishlog-1>
varnishncsa參考鏈接:<http://varnish-cache.org/docs/trunk/reference/varnishncsa.html#varnishncsa-1>