




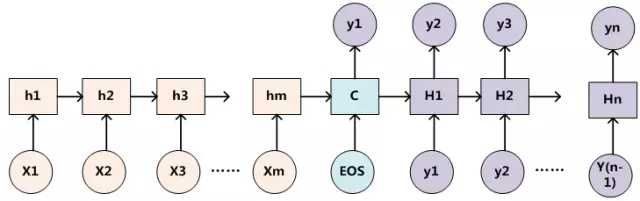
1. 標籤文本預處理
使用 <PAD> 做標籤對齊補齊,使用<GO>和<EOS>對標籤做起始和結束標誌,用於告訴decoder文本起始與結束,對於某些低頻詞彙和不關心詞彙使用<UNK>標籤替代.
2.seq2seq api
- encoder部分
通常使用 lstm 或 gru 進行編碼,在其前可以添加cnn做特徵抽取
- decoder部分
主要函數是TrainingHelper, GreedyEmbeddingHelper, BasicDecoder, dynamic_decode
TrainingHelper 用於訓練時
class TrainingHelper(Helper):
"""A helper for use during training. Only reads inputs.
Returned sample_ids are the argmax of the RNN output logits.
"""
def __init__(self, inputs, sequence_length, time_major=False, name=None):
"""Initializer.
Args:
inputs: A (structure of) input tensors.
sequence_length: An int32 vector tensor.
time_major: Python bool. Whether the tensors in `inputs` are time major.
If `False` (default), they are assumed to be batch major.
name: Name scope for any created operations.
Raises:
ValueError: if `sequence_length` is not a 1D tensor.
"""
input : 上一個時刻的 
sequence_length : decoder 目標的長度
GreedyEmbeddingHelper 用於預測時
class GreedyEmbeddingHelper(Helper):
"""A helper for use during inference.
Uses the argmax of the output (treated as logits) and passes the
result through an embedding layer to get the next input.
"""
def __init__(self, embedding, start_tokens, end_token):
"""Initializer.
Args:
embedding: A callable that takes a vector tensor of `ids` (argmax ids),
or the `params` argument for `embedding_lookup`. The returned tensor
will be passed to the decoder input.
start_tokens: `int32` vector shaped `[batch_size]`, the start tokens.
end_token: `int32` scalar, the token that marks end of decoding.
Raises:
ValueError: if `start_tokens` is not a 1D tensor or `end_token` is not a
scalar.
"""
input : 是embedding後的詞向量庫, callable, 每個上一時刻的預測值均會經過這個 embedding 轉化爲詞向量
start_tokens : 開始的下標向量, 即 <GO> 在字典中的下標 index 的常量向量
end_token : 結束標誌的下標值
BasicDecoder 解碼函數
class BasicDecoder(decoder.Decoder):
"""Basic sampling decoder."""
def __init__(self, cell, helper, initial_state, output_layer=None):
"""Initialize BasicDecoder.
Args:
cell: An `RNNCell` instance.
helper: A `Helper` instance.
initial_state: A (possibly nested tuple of...) tensors and TensorArrays.
The initial state of the RNNCell.
output_layer: (Optional) An instance of `tf.layers.Layer`, i.e.,
`tf.layers.Dense`. Optional layer to apply to the RNN output prior
to storing the result or sampling.
Raises:
TypeError: if `cell`, `helper` or `output_layer` have an incorrect type.
"""
cell : rnn單元, 如果有attention機制, 就是經過attention warpper後的cell
helper : 前面兩個helper中的一個
initial_state : 初始狀態, 如果沒有 attention 機制, 就是 encoder 的輸出狀態; 如果有 attention 機制, 就是 dec_cell.zero_state(batch_size, dtype=tf.float32), dec_cell就是attention warpper後的cell
output_layer : 通常是dense層
tf.contrib.seq2seq.dynamic_decode 動態的解碼器, 可以解碼不同長度的輸入,但每個batch的解碼長度必須相同
def dynamic_decode(decoder,
output_time_major=False,
impute_finished=False,
maximum_iterations=None,
parallel_iterations=32,
swap_memory=False,
scope=None):
"""Perform dynamic decoding with `decoder`.
Calls initialize() once and step() repeatedly on the Decoder object.
Args:
decoder: A `Decoder` instance.
output_time_major: Python boolean. Default: `False` (batch major). If
`True`, outputs are returned as time major tensors (this mode is faster).
Otherwise, outputs are returned as batch major tensors (this adds extra
time to the computation).
impute_finished: Python boolean. If `True`, then states for batch
entries which are marked as finished get copied through and the
corresponding outputs get zeroed out. This causes some slowdown at
each time step, but ensures that the final state and outputs have
the correct values and that backprop ignores time steps that were
marked as finished.
maximum_iterations: `int32` scalar, maximum allowed number of decoding
steps. Default is `None` (decode until the decoder is fully done).
parallel_iterations: Argument passed to `tf.while_loop`.
swap_memory: Argument passed to `tf.while_loop`.
scope: Optional variable scope to use.
Returns:
`(final_outputs, final_state, final_sequence_lengths)`.
Raises:
TypeError: if `decoder` is not an instance of `Decoder`.
ValueError: if `maximum_iterations` is provided but is not a scalar.
"""
- attention 部分
主要對象是BahdanauAttention, LuongAttention , AttentionWrapper
BahdanauAttention attention機制類型
class BahdanauAttention(_BaseAttentionMechanism):
def __init__(self,
num_units,
memory,
memory_sequence_length=None,
normalize=False,
probability_fn=None,
score_mask_value=None,
dtype=None,
name="BahdanauAttention"):
"""Construct the Attention mechanism.
Args:
num_units: The depth of the query mechanism.
memory: The memory to query; usually the output of an RNN encoder. This
tensor should be shaped `[batch_size, max_time, ...]`.
memory_sequence_length (optional): Sequence lengths for the batch entries
in memory. If provided, the memory tensor rows are masked with zeros
for values past the respective sequence lengths.
normalize: Python boolean. Whether to normalize the energy term.
probability_fn: (optional) A `callable`. Converts the score to
probabilities. The default is `tf.nn.softmax`. Other options include
`tf.contrib.seq2seq.hardmax` and `tf.contrib.sparsemax.sparsemax`.
Its signature should be: `probabilities = probability_fn(score)`.
score_mask_value: (optional): The mask value for score before passing into
`probability_fn`. The default is -inf. Only used if
`memory_sequence_length` is not None.
dtype: The data type for the query and memory layers of the attention
mechanism.
name: Name to use when creating ops.
"""
num_units : attention 機制的 dense 單元數量
memory : encoder 的 輸出
memory_sequence_length : target的長度, 用於計算mask
AttentionWrapper 給 decoder 的cell 應用定義的 attention 機制
class AttentionWrapper(rnn_cell_impl.RNNCell):
"""Wraps another `RNNCell` with attention.
"""
def __init__(self,
cell,
attention_mechanism,
attention_layer_size=None,
alignment_history=False,
cell_input_fn=None,
output_attention=True,
initial_cell_state=None,
name=None,
attention_layer=None):
"""Construct the `AttentionWrapper`.
**NOTE** If you are using the `BeamSearchDecoder` with a cell wrapped in
`AttentionWrapper`, then you must ensure that:
- The encoder output has been tiled to `beam_width` via
`tf.contrib.seq2seq.tile_batch` (NOT `tf.tile`).
- The `batch_size` argument passed to the `zero_state` method of this
wrapper is equal to `true_batch_size * beam_width`.
- The initial state created with `zero_state` above contains a
`cell_state` value containing properly tiled final state from the
encoder.
An example:
```
tiled_encoder_outputs = tf.contrib.seq2seq.tile_batch(
encoder_outputs, multiplier=beam_width)
tiled_encoder_final_state = tf.conrib.seq2seq.tile_batch(
encoder_final_state, multiplier=beam_width)
tiled_sequence_length = tf.contrib.seq2seq.tile_batch(
sequence_length, multiplier=beam_width)
attention_mechanism = MyFavoriteAttentionMechanism(
num_units=attention_depth,
memory=tiled_inputs,
memory_sequence_length=tiled_sequence_length)
attention_cell = AttentionWrapper(cell, attention_mechanism, ...)
decoder_initial_state = attention_cell.zero_state(
dtype, batch_size=true_batch_size * beam_width)
decoder_initial_state = decoder_initial_state.clone(
cell_state=tiled_encoder_final_state)
```
cell : decoder 的 rnn 單元
attention_mechanism : 定義的 attention 對象
示例
encoder
def get_encoder_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
'''
構造Encoder層
參數說明:
- input_data: 輸入tensor
- rnn_size: rnn隱層結點數量
- num_layers: 堆疊的rnn cell數量
- source_sequence_length: 源數據的序列長度
- source_vocab_size: 源數據的詞典大小
- encoding_embedding_size: embedding的大小
'''
# Encoder embedding
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell, encoder_embed_input,
sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
decoder
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size,
target_sequence_length, max_target_sequence_length, encoder_output, encoder_state, decoder_input):
'''
構造Decoder層
參數:
- target_letter_to_int: target數據的映射表
- decoding_embedding_size: embed向量大小
- num_layers: 堆疊的RNN單元數量
- rnn_size: RNN單元的隱層結點數量
- target_sequence_length: target數據序列長度
- max_target_sequence_length: target數據序列最大長度
- encoder_state: encoder端編碼的狀態向量
- decoder_input: decoder端輸入
'''
# 1. Embedding
target_vocab_size = len(target_letter_to_int)
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
# 2. 構造Decoder中的RNN單元
def get_decoder_cell(rnn_size):
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
# 定義 attention 機制
attn_mech = tf.contrib.seq2seq.BahdanauAttention(rnn_size, encoder_output, target_sequence_length, normalize=False,
name='BahdanauAttention')
# 應用 attention 機制
dec_cell = tf.contrib.seq2seq.AttentionWrapper(cell=cell, attention_mechanism=attn_mech)
# 3. Output全連接層
output_layer = Dense(target_vocab_size,
kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
# 4. Training decoder
with tf.variable_scope("decode"):
# 得到help對象
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input,
sequence_length=target_sequence_length,
time_major=False)
# 構造decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
training_helper,
dec_cell.zero_state(batch_size, dtype=tf.float32)
.clone(cell_state=encoder_state),
output_layer)
training_decoder_output, _, _ = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
# 5. Predicting decoder
# 與training共享參數
with tf.variable_scope("decode", reuse=True):
# 創建一個常量tensor並複製爲batch_size的大小
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size],
name='start_tokens')
predicting_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
predicting_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
predicting_helper,
dec_cell.zero_state(batch_size, dtype=tf.float32)
.clone(cell_state=encoder_state),
output_layer)
predicting_decoder_output, _, _ = tf.contrib.seq2seq.dynamic_decode(predicting_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
return training_decoder_output, predicting_decoder_output