




SPL是一種面向結構化數據計算的程序設計語言,集算器是SPL語言的java實現,採用網格式編程形式提供了編碼和調試的IDE環境,語法比Java和SQL更爲簡單易懂,開發效率更高。本文將從集算器的實現原理出發列舉一些可以提升計算性能的小技巧。
1數據類型
1.1 數值
SPL裏的數值類型有Integer、Long、Double、BigDecimal。其中BigDecimal雖然能夠表示任意精度的數據,但計算速度比其它數類型慢很多,佔用的內存也大很多,因此在其它數字類型能夠滿足精度要求時,使用其它數類型代替BigDecimal能夠顯著提升計算效率。
實際案例中,在使用JDBC讀取數據庫數據時,有些數據庫的JDBC對於低精度數值也返回BigDecimal,這樣,在做性能優化時就可以檢查一下是否可以轉爲其它類型,從而提升性能。
1.2 字符串
Java的字符串對象String佔用空間較大,一個長度爲0的字符串佔用40多個字節,而Integer、Long只佔用16個字節。同時字符串的比較運算、哈希運算也比Integer、Long慢。
另外,數據從硬盤讀入生成java對象,其佔用的內存大小往往是其佔用的硬盤大小的數倍甚至十倍以上(如果硬盤存儲使用了壓縮技術差距會更大)。這種情況可能直接導致不太大的數據文件在讀成java對象時發生內存溢出,這時如果不能減少內存佔用量就只能使用外存計算了。而通常外存計算的複雜度遠大於內存計算,同時也導致性能會下降很多。
那麼,有沒有什麼方法能夠減少內存佔用同時又能提高計算效率呢?
一個常用的方法就是枚舉串序號化,比如下面一個事實表的數據:
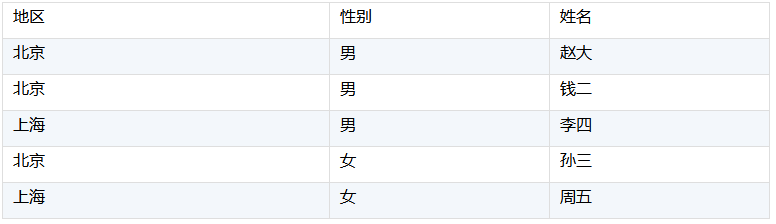
性別、地區這類枚舉型的字段,可以建立一個對應表把性別、地區值轉換爲序號1、2、…,這樣事實表中性別字段就可以只保存對應的序號,地區也是一樣。轉換後數據如下:


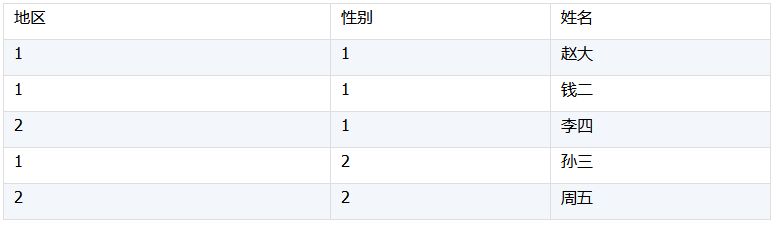
這樣一來,我們就可以做到減少內存佔用,並且提高計算效率,因爲數字的比較、分組等操作比字符串的要快很多。在輸出結果時,可以根據需要再把序號轉化爲串,也就是使用序號直接按位置到代碼表中找到相應的記錄進行替換。
2序表結構
2.1 行追加
序表類似數據庫中的表,但是卻是有順序的。序表數據在內存中用一個連續的數組保存。一般情況下,爲序表分配內存時會多預留一些空間來應付可能的增長,以免每次追加數據時都重新分配內存,不過也不可能預留太多空間而浪費內存。
基於這個原來,爲序表頻繁地追加記錄,會導致這個數組長度不斷地變長,原先爲這個數組分配的空間也要擴大。而擴大內存分配不是一件很簡單的事情,需要分配一塊更大的空間,然後將原空間內的數據複製過來。尋找空間和複製數據都要佔用 CPU 時間,而且常常比運算本身的消耗都大。
因此,如果事先知道行數,一次性把序表創建出來,那只需要在一開始分配一次內存就行了。即便序表中的字段值需要一些步驟才能計算出來,那也應該先new出序表後再去修改記錄的字段值,而不要計算一行插入一行。而對於修改記錄字段值的方法SPL提供了很多途徑。
假設我們想生成一個20行 2列的斐波那契數列序表,第一列key爲行號,即 1,2,3,…;第二列 value 爲值。斐波那契數列數列的規則是:第 1、第 2 行取值爲 1,從第 3 行起,取值爲前兩行之和。這個運算需要一步步實現,動態追加數據就是很自然的想法了:

不過,序表一次性產生性能更好,即使計算本身仍然需要一步步實現:

2.2 列追加
擴充序表,除了一行行追加數據,還有可能會改變數據的結構,增加每行數據中的字段,也就是所謂的列追加。列追加比行追加要更爲複雜,序表本身是一個大數組,其中的每一行是一條記錄,物理實現上也是一個數組。因爲數據結構很少改變,創建序表時不會在生成每行的數組時預留空間,否則內存浪費就太多了(因爲每一行都要預留)。基於這種實現原理,如果出現列追加,就會發生前面說的重新分配空間的情況,而且要針對每一行記錄進行,再將原記錄數據抄過來,可以想見,這個動作的時間成本有多大,甚至經常會遠遠超過追加那個列後要做的計算。
SPL爲序表提供了追加列的功能,這會帶來方便性,但在關注性能時卻要慎用。不得不用時,也應該如上所述,一次性把需要追加的列都加上,不要一遍遍地追加。對於當時無法計算出字段值的列可以先填成空值,以後再用其它函數去修改字段值。
最常見的情況,從數據庫取出的序表後,如果事先知道要再derive出新的一列xxx,那麼可以在寫SQL時多寫一個null as xxx,這樣在query時就直接把所需的字段都產生了,不用再做一次derive了。
例如,要從數據表sales中取出字段ORDERDATE,AMOUNT並按ORDERDATE排序,然後追加一列計算AMOUNT的累計值。一般先讀出再追加列的自然寫法:

而用 SQL 語句先把列生成好的寫法:

2.3 引用記錄
針對前面兩種調整序表結構的優化思路,出發點都是減少new、derive函數中抄字段值的動作。除此之外,SPL還支持對象引用,字段取值可以是另一條記錄。這樣,在SPL中,大多數情況沒必要像SQL那樣在新結果集中把字段抄一遍,爲了保持原有整條記錄一起參與運算,只要用引用方式來寫就可以了。這樣不僅性能更好而且空間佔用也少。
上面用derive追加AMOUNT累計值的要求可以用new函數實現,new創建一個新序表,SRC字段引用原紀錄,CUMULATE字段存儲累計值,寫法如下:

3循環函數
3.1 用循環函數代替循環語句
SPL的網格程序提供了循環語句for和分支語句if來實現複雜的運算邏輯。運行時,由於網格的執行次序是動態解釋的,因此大量使用循環,會導致執行的網格過多,在網格的動態解釋上就要花費大量的時間。
除了循環語句,SPL還提供了循環函數,可以對付大多數需要使用for語句的場景。對於計算步驟不太複雜,對性能要求高的運算應該儘量使用循環函數來完成。類似地,能用if 函數的場景也儘量不要用if語句。
1.2節中列舉的計算斐波那契數列的例子可以改寫爲如下:

其中#表示當前循環到哪條記錄,第一條記錄對應的#是1,依次遞增。value[-1]表示上一條記錄的value值,value[-2]表示上前數第二條記錄的value值。
eval函數每次執行都要把參數指定的表達式字符串解析成表達式,然後再執行,如果eval函數在循環裏執行,過多地把表達式字符串解析成表達式會花費大量的時間,如果表達式字符串不是變的則可以使用宏替換代替eval。
3.2 常量放在循環外
把循環裏常量的產生放到循環外,也可以對性能優化提供幫助。例如選出北京, 上海, 深圳地區的銷售記錄,比較“自然”的寫法是:

因爲SPL的序列是可以被修改的,所以表達式["北京","上海","深圳"]每計算一次都會產生一個新序列。如果像上面這樣把["北京","上海","深圳"]放在循環函數select裏,那麼在執行時將會產生A2長度個序列。如果循環次數多,這些不必要的運算將消耗大量時間。因此,注重性能的寫法應該如下:

3.3 警惕循環套循環
警惕循環函數中再有循環函數,這些代碼看起來很簡單,但幾層循環下來,實際計算量會以幾何級數放大。這雖然是個常識,但有時也會被忽略,因此能在循環外做的事不要放到循環內。特別地,尤其要警惕在循環內讀文件和訪問數據庫這種超級耗時的動作。
4代碼習慣
4.1 釋放內存
Java在內存不足時性能會急劇下降。所以要及時釋放內存,SPL沒有刪除變量釋放內存的語句,只需把變量或單元格的值設爲空即可,也可以用clear語句清除一片格子。例子如下:
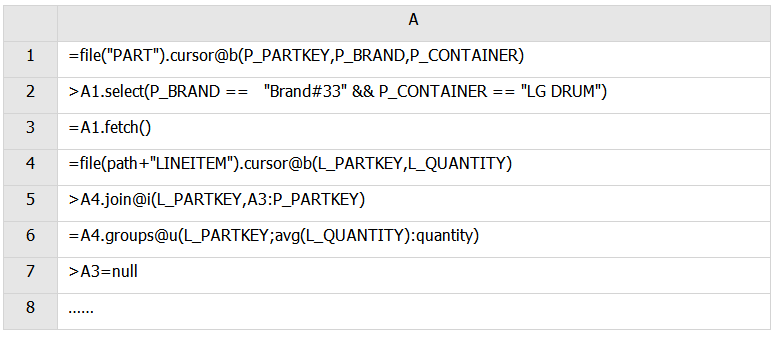
以=開頭單元格是計算格,表達式的返回值會保存在單元格上,以>開頭的單元格是執行格,表達式的返回值不會保存。cs.select和cs.join是給遊標附加運算,不會產生新的遊標所以返回值可以不用保存,A7格爲釋放讀出的PART數據,也可以用clear語句把A1到A5之間的單元格值都清空,只需要把A7格代碼替換如下:

4.2 代碼緊湊
for 和if的代碼塊,可以直接寫到同一行上,沒有必要像Java那樣換一行再寫。SPL的網絡已經能夠清晰地拆分出這些語句了。解釋器掃描空白格也需要時間,因此對於含有循環語句的程序,如果循環次數特別多,應該讓代碼緊湊一些,刪除空白的行和列以減少格子數量,從而提高解釋器的效率。
下面以獲取每天第一條銷售記錄爲例,介紹一下SPL的代碼塊規則,sales是銷售記錄遊標參數,按ORDERDATE有序。

單元格的代碼塊爲單元格所在行及其正下和左下單元格都爲空白格的行,上面例子中A2格for的代碼塊爲[B2:F5]。B2格if的代碼塊爲[C2 : F2],if代碼塊的下一行和if所在格同列的單元格B3爲else,並且B3左面的格子都是空白格,則B3格爲B2格的else分支,B3格的代碼塊爲[C3 : F5]。else也可以和對應的if同行,寫在if右面的單元格上。