




首先這次學習的是利用寫Python腳本對網頁信息的獲取,並且把他保存到我們的數據庫裏最後形成一個Excel表格
下載第三方模塊和源碼安裝MongoDB
剛開始我們需要做一些準備:
先安裝第三方模塊
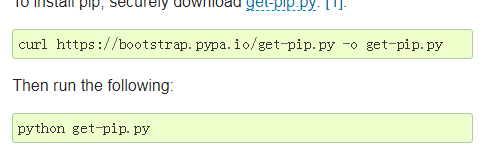
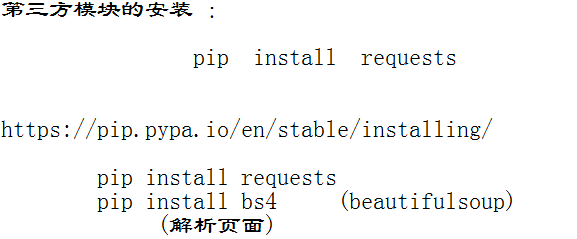
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.5.tgz

思路如下:
1.訪問網站,拿到html網頁
headers獲取: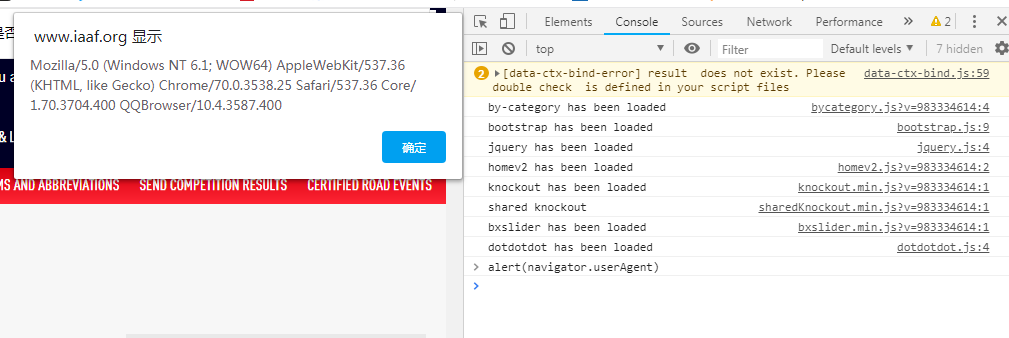
腳本1:
運行前打開mongod :
./mongod & 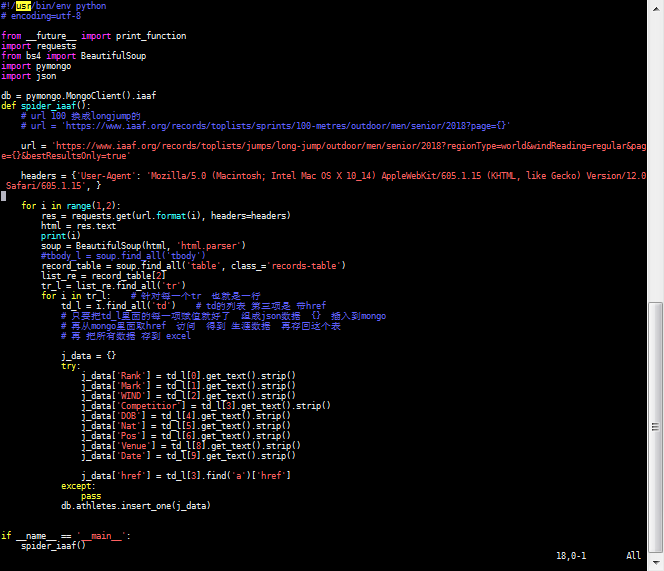
2.提取html裏面我們想要的內容
腳本2: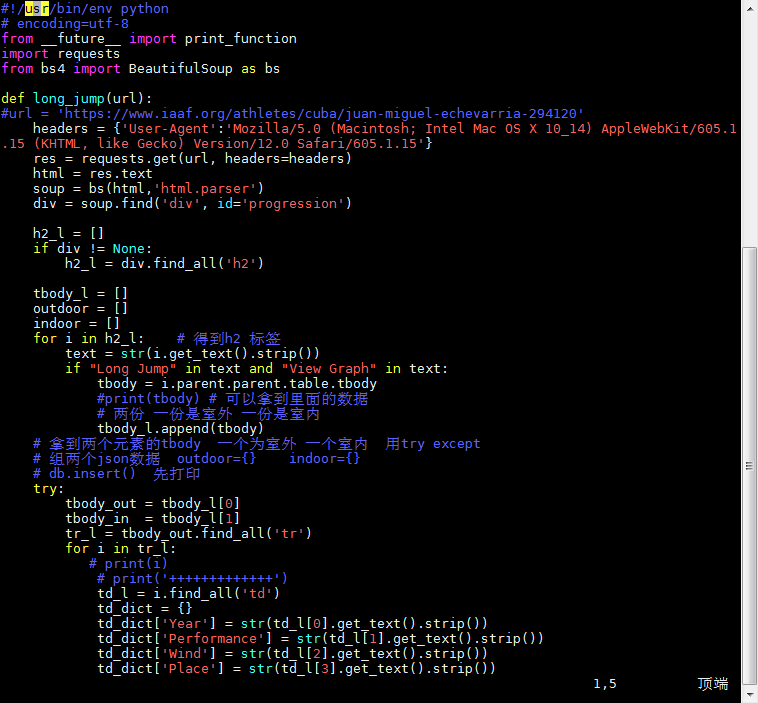
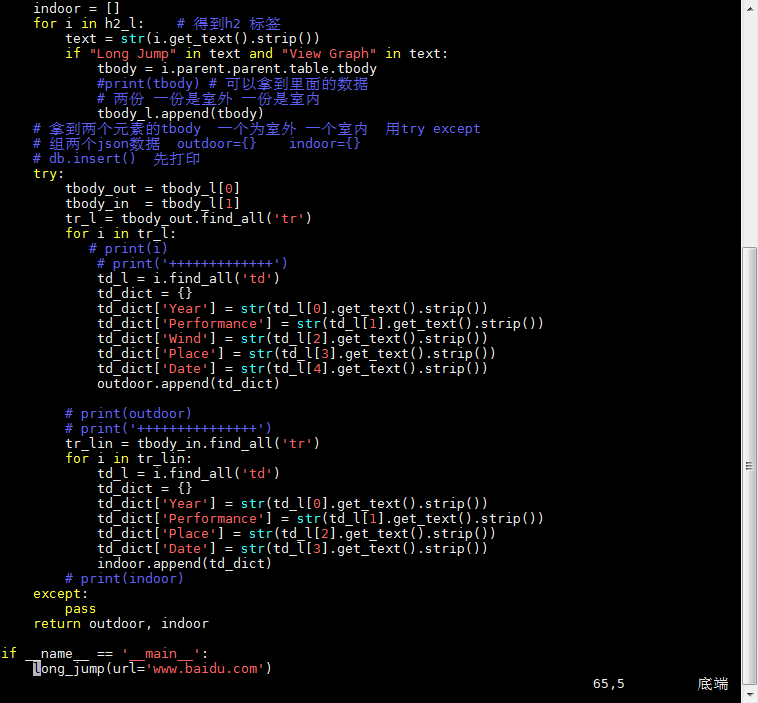
Long Jump 和 View Graph 是根據他們可以定位到我們想獲取的信息的標籤上
這個腳本寫完不需要運行,他的url是由第三個腳本導入的
3.把我們爬到的內容存到數據庫中
腳本3:
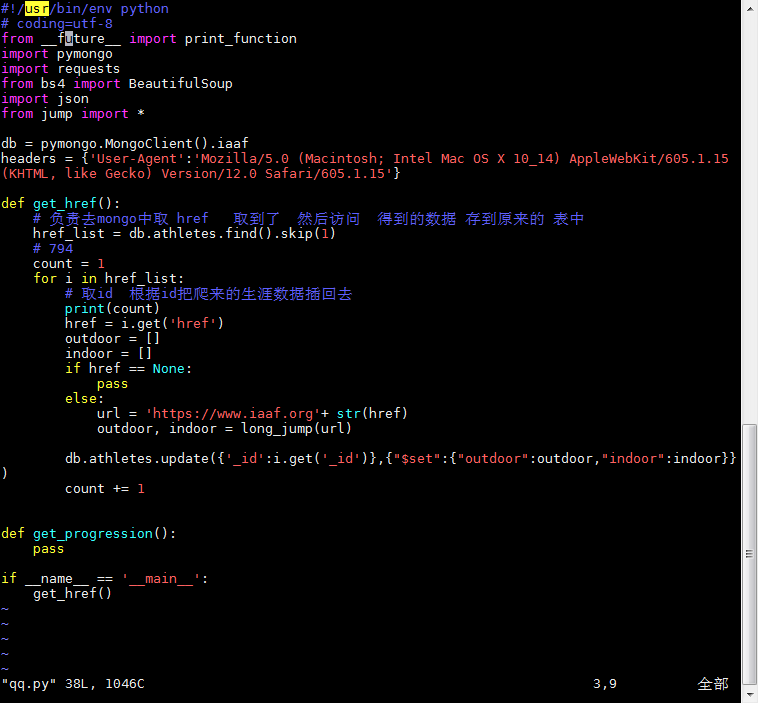
運行前都要檢查MongoD是否運行,運行後可進入數據庫去看我們存入的信息
在MongoDB的bin下
./mongo
use iaaf
db.athletes.find()4.轉成Excel表格
腳本4:

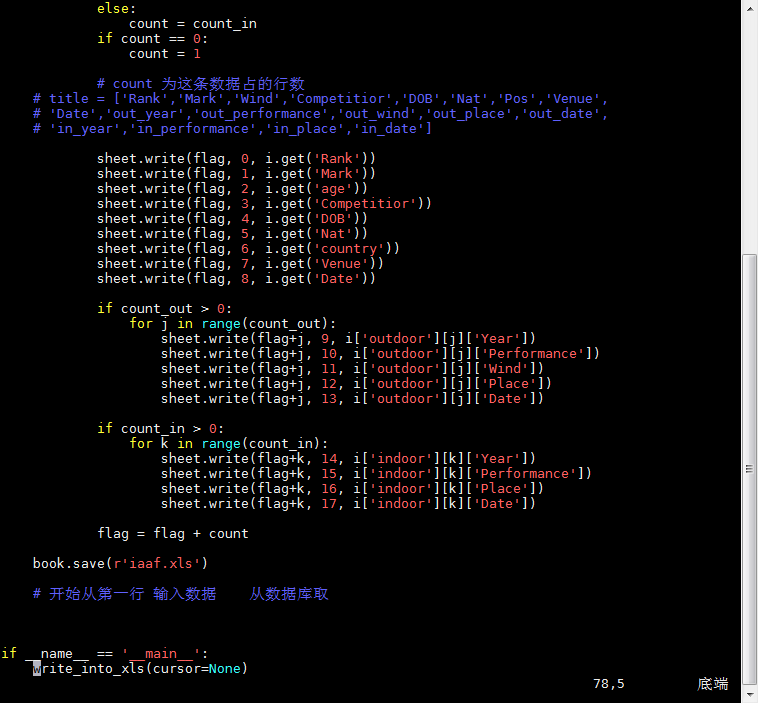
5.requests,pymongo,bs4的用法總結
requests是一個很實用的Python HTTP客戶端庫,編寫爬蟲和測試服務器響應數據時經常會用到。可以說,Requests 完全滿足如今網絡的需求
1.作用:發送請求獲取響應爲什麼使用requesst?
1)requests底層實現的是urllib2)requests在python2和python3中通用,方法完全一樣
3)requests簡單易用(python特性)
4)requests能夠幫助我們解壓響應內容(自動解壓完善請求頭,自動獲取cookie)
- 發送簡單的get請求、獲取響應response = requests.get(url)
pymongo是python操作 mongodb的工具包
bs4概念:
bs4庫是解析、遍歷、維護、"標籤樹"的功能庫
通俗一點說就是:bs4庫把HTML源代碼重新進行了格式化,
從而方便我們對其中的節點、標籤、屬性等進行操作
2.BS4的4中對象
①Tag對象:是html中的一個標籤,用BeautifulSoup就能解析出來Tag的具體內容,具體
的格式爲‘soup.name‘,其中name是html下的標籤。
②BeautifulSoup對象:整個html文本對象,可當作Tag對象
③NavigableString對象:標籤內的文本對象
④Comment對象:是一個特殊的NavigableString對象,如果html標籤內存在註釋,那麼它可以過濾掉註釋符號保留註釋文本
最常用的還是BeautifulSoup對象和Tag對象