




寫介紹kafka的幾個重要概念(可以參考之前的博文Kafka的簡單介紹):
Broker:消息中間件處理結點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka集羣;
Topic:一類消息,例如page view日誌、click日誌等都可以以topic的形式存在,Kafka集羣能夠同時負責多個topic的分發;
Partition:topic物理上的分組,一個topic可以分爲多個partition,每個partition是一個有序的隊;
Segment:每個partition又由多個segment file組成;
offset:每個partition都由一系列有序的、不可變的消息組成,這些消息被連續的追加到partition中。partition中的每個消息都有一個連續的序列號叫做offset,用於partition唯一標識一條消息;
message:這個算是kafka文件中最小的存儲單位,即是 a commit log。
topic:創建topic名稱
partition:分區編號
offset:表示該partition已經消費了多少message
logsize:表示該paritition生產了多少的message
lag:表示有多少條message未被消費
owner:表示消費者
create:表示該partition創建時間
last seen:表示消費狀態刷新最新時間
參考鏈接:
能查看到kafka中生產了,消費了,還剩下多少message中我們用的是kafkaoffsetmonitor這個監控插件Kafka監控工具KafkaOffsetMonitor配置及使用:https://www.cnblogs.com/dadonggg/p/8242682.html
topics是什麼?partition是什麼?topics是kafka中數據存儲的基本單位
寫數據,要指定寫入哪個topic 讀數據,指定從哪個topic去讀
我們可以這樣簡單的理解
topic就類似於數據庫中的一張表,可以創建任意多個topic 每一個topic的名字是唯一的
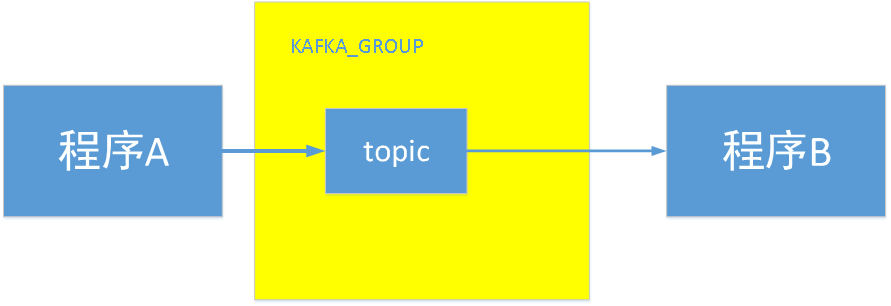
例如:
程序A產生了一類消息,然後把這類消息放在kafka group中 ,這由程序A產生的這個消息就叫一個topic
程序B需要 訂閱這個消息,才能成爲這個topic的消費者
每個topic的內部都會有一個或多個partitions(分區)
你寫入的數據,他其實是寫入每一個topic裏的其中一個partition,並且當前的數據是有序的寫入到paritition中的。
每一個partition內都會維護一個不斷增加的ID,每當你寫入一個新的數據的時候,這個ID就會增長,這個id就會被稱爲這個paritition的offset,每個寫入partition中的message都會對應一個offset。
不同的partition都會對應他們自己的offset 我們可以利用offset來判斷,當前paritition內部的順序,但是我們不能比較來自不同的兩個partition的順序,這是沒有意義的
partition中的數據是有序的,不同partition間的數據丟失了數據的順序。如果topic有多個partition,消費數據時就不能保證數據的順序。在需要嚴格保證消息的消費順序的場景下,需要將partition數目設爲1。
//
每個topic將被分成多個partition(區)

每個topic將被分成多個partition(區),此外kafka還可以配置partitions需要備份的個數(replicas)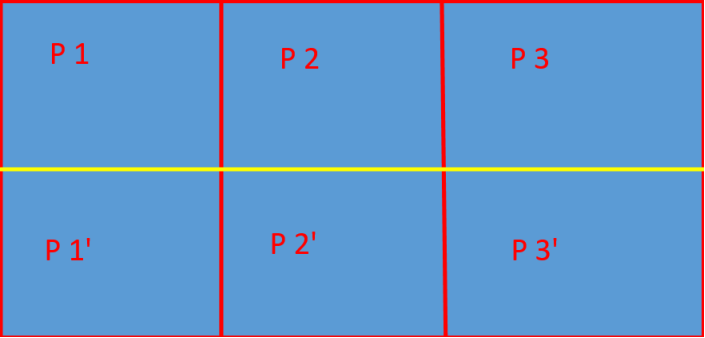
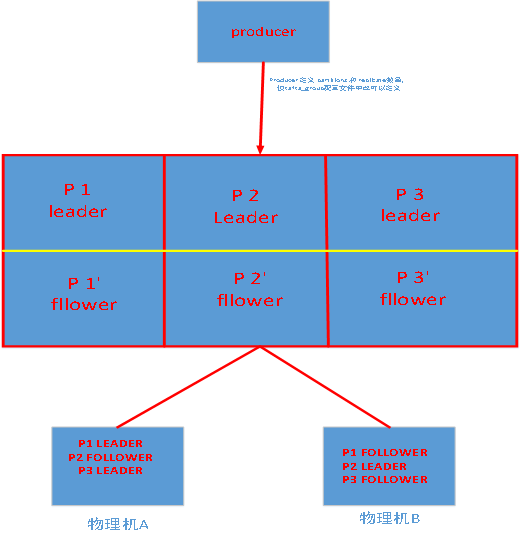
基於replicated方案,那麼就意味着需要對多個備份進行調度;每個partition都有一個server爲"leader";leader負責所有的讀寫操作,如果leader失效,那麼將會有其他follower來接管(成爲新的leader);follower只是單調的和leader跟進,同步消息即可..由此可見作爲leader的server承載了全部的請求壓力,因此從集羣的整體考慮,有多少個partitions就意味着有多少個"leader",kafka會將"leader"均衡的分散在每個實例上,來確保整體的性能穩定.
其中partition leader的位置(host:port)註冊在zookeeper中
當你講數據寫入kafka中,改數據默認情況下會在kafka中保存2個星期。當然,我們可以去配置的。如果是默認的2個星期,超過2個星期的話,kafka裏面的數據就會被無效化。這個時候,該數據對應的offset就沒有其他的意義了。
從kafka讀取數據後 數據會自動刪除嗎
不會,kafka中數據的刪除跟有沒有消費者消費完全無關。數據的刪除,只跟kafka broker上面上面的這兩個配置有關:
log.retention.hours=48 #數據最多保存48小時
log.retention.bytes=1073741824 #數據最多1G
提示:寫入到kafka中的數據,是不可以被改變的。他有一個熟悉就是immutability。也就是說,你沒有辦法去更改已經寫入到kafka中的數據。
如果你想更新一個數據memssage,那你只能重新寫入memssage到kafka中,並且這個新的message會有一個新的offset,以區別於之前寫入的message。
對於每一個寫入kafka中的數據,他們會隨機的寫入到當前topic中的某一個partition內,有一個例外,你提供一個key給當前的數據,這個時候,你就可以用當前的key去控制當前數據應該傳入到哪個partition中。
每一個topic中都可以由多個parititions 這是由你來決定的