




一.ZooKeeper典型應用場景實踐
ZooKeeper是一個高可用的分佈式數據管理與系統協調框架。基於對Paxos算法的實現,使該框架保證了分佈式環境中數據的強一致性,也正是基於這樣的特性,使得ZooKeeper解決很多分佈式問題。網上對ZK的應用場景也有不少介紹,本文將介紹比較常用的項目例子,系統地對ZK的應用場景進行一個分門歸類的介紹。
值得注意的是,ZK並非天生就是爲這些應用場景設計的,都是後來衆多開發者根據其框架的特性,利用其提供的一系列API接口(或者稱爲原語集),摸索出來的典型使用方法。因此,也非常歡迎讀者分享你在ZK使用上的奇技淫巧。
1 Zookeeper數據模型
Zookeeper 會維護一個具有層次關係的數據結構,它非常類似於一個標準的文件系統,如圖所示:
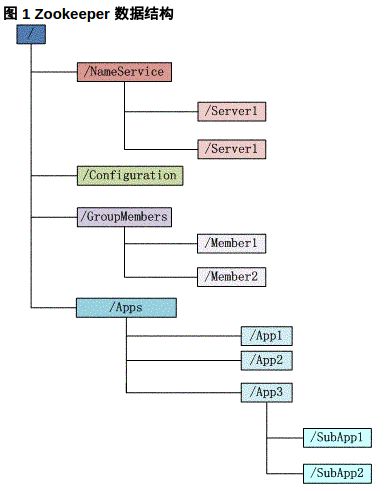
圖中的每個節點稱爲一個znode. 每個znode由3部分組成:
-
stat. 此爲狀態信息, 描述該
znode的版本, 權限等信息; -
data. 與該znode
關聯的數據; -
children. 該znode下的
子節點;
Zookeeper 這種數據結構有如下這些特點:
-
每個子目錄項如 NameService 都被稱作爲 znode,這個 znode 是被它所在的路徑唯一標識,如 Server1 這個 znode 的標識爲 /NameService/Server1;
-
znode 可以有子節點目錄,並且每個 znode 可以存儲數據,注意
EPHEMERAL 類型的目錄節點不能有子節點目錄; -
znode 是有版本的,每個 znode 中存儲的數據可以有多個版本,
也就是一個訪問路徑中可以存儲多份數據; -
znode 可以是臨時節點,
一旦創建這個 znode 的客戶端與服務器失去聯繫,這個 znode 也將自動刪除,Zookeeper 的客戶端和服務器通信採用長連接方式,每個客戶端和服務器通過心跳來保持連接,這個連接狀態稱爲 session,如果 znode 是臨時節點,這個 session 失效,znode 也就刪除了; -
znode 的
目錄名可以自動編號,如 App1 已經存在,再創建的話,將會自動命名爲 App2; -
znode
可以被監控,包括這個目錄節點中存儲的數據的修改,子節點目錄的變化等,一旦變化可以通知設置監控的客戶端,這個是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基於這個特性實現的,後面在典型的應用場景中會有實例介紹;
znode節點的狀態信息:
使用get命令獲取指定節點的數據時, 同時也將返回該節點的狀態信息, 稱爲Stat. 其包含如下字段:
czxid. 節點創建時的zxid; mzxid. 節點最新一次更新發生時的zxid; ctime. 節點創建時的時間戳; mtime. 節點最新一次更新發生時的時間戳; dataVersion. 節點數據的更新次數; cversion. 其子節點的更新次數; aclVersion. 節點ACL(授權信息)的更新次數; ephemeralOwner. 如果該節點爲ephemeral節點, ephemeralOwner值表示與該節點綁定的session id. 如果該節點不是 ephemeral節點, ephemeralOwner值爲0. 至於什麼是ephemeral節點; dataLength. 節點數據的字節數; numChildren. 子節點個數;
zxid:
znode節點的狀態信息中包含czxid和mzxid, 那麼什麼是zxid呢?
ZooKeeper狀態的每一次改變, 都對應着一個遞增的Transaction id, 該id稱爲zxid. 由於zxid的遞增性質, 如果zxid1小於zxid2, 那麼zxid1肯定先於zxid2發生. 創建任意節點, 或者更新任意節點的數據, 或者刪除任意節點, 都會導致Zookeeper狀態發生改變, 從而導致zxid的值增加.
session:
在client和server通信之前, 首先需要建立連接, 該連接稱爲session. 連接建立後, 如果發生連接超時, 授權失敗, 或者顯式關閉連接, 連接便處於CLOSED狀態, 此時session結束.
節點類型:
講述節點狀態的ephemeralOwner字段時, 提到過有的節點是ephemeral節點, 而有的並不是. 那麼節點都具有哪些類型呢? 每種類型的節點又具有哪些特點呢?
persistent. persistent節點不和特定的session綁定, 不會隨着創建該節點的session的結束而消失, 而是一直存在, 除非該節點被顯式刪除.
ephemeral. ephemeral(臨時)節點是臨時性的, 如果創建該節點的session結束了, 該節點就會被自動刪除. ephemeral節點不能擁有子節點. 雖然ephemeral節點與創建它的session綁定, 但只要該節點沒有被刪除, 其他session就可以讀寫該節點中關聯的數據. 使用-e參數指定創建ephemeral節點.
create -e /xing/ei world
sequence. 嚴格的說, sequence(順序)並非節點類型中的一種. sequence節點既可以是ephemeral的, 也可以是persistent的. 創建sequence節點時, ZooKeeper server會在指定的節點名稱後加上一個數字序列, 該數字序列是遞增的. 因此可以多次創建相同的sequence節點, 而得到不同的節點. 使用-s參數指定創建sequence節點.
[zk: localhost:4180(CONNECTED) 0] create -s /xing/item world Created /xing/item0000000001 [zk: localhost:4180(CONNECTED) 1] create -s /xing/item world Created /xing/item0000000002 [zk: localhost:4180(CONNECTED) 2] create -s /xing/item world Created /xing/item0000000003 [zk: localhost:4180(CONNECTED) 3] create -s /xing/item world Created /xing/item0000000004
watch:
watch的意思是監聽感興趣的事件. 在命令行中, 以下幾個命令可以指定是否監聽相應的事件.
ls命令. ls命令的第一個參數指定znode, 第二個參數如果爲true, 則說明監聽該znode的子節點的增減, 以及該znode本身的刪除事件.
[zk: localhost:4180(CONNECTED) 21] ls /xing true [] [zk: localhost:4180(CONNECTED) 22] create /xing/item item000 WATCHER:: WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/xing Created /xing/item
get命令. get命令的第一個參數指定znode, 第二個參數如果爲true, 則說明監聽該znode的更新和刪除事件.
[zk: localhost:4180(CONNECTED) 39] get /xing true world cZxid = 0x100000066 ctime = Fri May 17 22:30:01 CST 2013 mZxid = 0x100000066 mtime = Fri May 17 22:30:01 CST 2013 pZxid = 0x100000066 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 0 [zk: localhost:4180(CONNECTED) 40] create /xing/item item000 Created /xing/item [zk: localhost:4180(CONNECTED) 41] rmr /xing WATCHER:: WatchedEvent state:SyncConnected type:NodeDeleted path:/xing
2 如何使用Zookeeper
Zookeeper 作爲一個分佈式的服務框架,主要用來解決分佈式集羣中應用系統的一致性問題,它能提供基於類似於文件系統的目錄節點樹方式的數據存儲,但是 Zookeeper 並不是用來專門存儲數據的,它的作用主要是用來維護和監控你存儲的數據的狀態變化。通過監控這些數據狀態的變化,從而可以達到基於數據的集羣管理,後面將會詳細介紹 Zookeeper 能夠解決的一些典型問題,這裏先介紹一下,Zookeeper 的操作接口和簡單使用示例。
2.1 常用接口操作
客戶端要連接 Zookeeper 服務器可以通過創建 org.apache.zookeeper.ZooKeeper 的一個實例對象,然後調用這個類提供的接口來和服務器交互。
前面說了 ZooKeeper 主要是用來維護和監控一個目錄節點樹中存儲的數據的狀態,所有我們能夠操作 ZooKeeper 的也和操作目錄節點樹大體一樣,如創建一個目錄節點,給某個目錄節點設置數據,獲取某個目錄節點的所有子目錄節點,給某個目錄節點設置權限和監控這個目錄節點的狀態變化。
ZooKeeper 基本的操作示例:
public class ZkDemo {
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
// 創建一個與服務器的連接
ZooKeeper zk = new ZooKeeper("127.0.0.1:2180", 60000, new Watcher() {
// 監控所有被觸發的事件
// 當對目錄節點監控狀態打開時,一旦目錄節點的狀態發生變化,Watcher 對象的 process 方法就會被調用。
public void process(WatchedEvent event) {
System.out.println("EVENT:" + event.getType());
}
});
// 查看根節點
// 獲取指定 path 下的所有子目錄節點,同樣 getChildren方法也有一個重載方法可以設置特定的 watcher 監控子節點的狀態
System.out.println("ls / => " + zk.getChildren("/", true));
// 判斷某個 path 是否存在,並設置是否監控這個目錄節點,這裏的 watcher 是在創建 ZooKeeper 實例時指定的 watcher;
// exists方法還有一個重載方法,可以指定特定的 watcher
if (zk.exists("/node", true) == null) {
// 創建一個給定的目錄節點 path, 並給它設置數據;
// CreateMode 標識有四種形式的目錄節點,分別是:
// PERSISTENT:持久化目錄節點,這個目錄節點存儲的數據不會丟失;
// PERSISTENT_SEQUENTIAL:順序自動編號的目錄節點,這種目錄節點會根據當前已近存在的節點數自動加 1,然後返回給客戶端已經成功創建的目錄節點名;
// EPHEMERAL:臨時目錄節點,一旦創建這個節點的客戶端與服務器端口也就是 session 超時,這種節點會被自動刪除;
// EPHEMERAL_SEQUENTIAL:臨時自動編號節點
zk.create("/node", "conan".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node conan");
// 查看/node節點數據
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
// 查看根節點
System.out.println("ls / => " + zk.getChildren("/", true));
}
// 創建一個子目錄節點
if (zk.exists("/node/sub1", true) == null) {
zk.create("/node/sub1", "sub1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node/sub1 sub1");
// 查看node節點
System.out.println("ls /node => " + zk.getChildren("/node", true));
}
// 修改節點數據
if (zk.exists("/node", true) != null) {
// 給 path 設置數據,可以指定這個數據的版本號,如果 version 爲 -1 怎可以匹配任何版本
zk.setData("/node", "changed".getBytes(), -1);
// 查看/node節點數據
// 獲取這個 path 對應的目錄節點存儲的數據,數據的版本等信息可以通過 stat 來指定,同時還可以設置是否監控這個目錄節點數據的狀態
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
}
// 刪除節點
if (zk.exists("/node/sub1", true) != null) {
// 刪除 path 對應的目錄節點,version 爲 -1 可以匹配任何版本,也就刪除了這個目錄節點所有數據
zk.delete("/node/sub1", -1);
zk.delete("/node", -1);
// 查看根節點
System.out.println("ls / => " + zk.getChildren("/", true));
}
// 關閉連接
zk.close();
}
}
3 ZooKeeper 典型的應用場景
Zookeeper 從設計模式角度來看,是一個基於觀察者模式設計的分佈式服務管理框架,它負責存儲和管理大家都關心的數據,然後接受觀察者的註冊,一旦這些數據的狀態發生變化,Zookeeper 就將負責通知已經在 Zookeeper 上註冊的那些觀察者做出相應的反應,從而實現集羣中類似 Master/Slave 管理模式,關於 Zookeeper 的詳細架構等內部細節可以閱讀 Zookeeper 的源碼。
下面詳細介紹這些典型的應用場景,也就是 Zookeeper 到底能幫我們解決那些問題?下面將給出答案。
3.1 統一命名服務(Name Service)
分佈式應用中,通常需要有一套完整的命名規則,既能夠產生唯一的名稱又便於人識別和記住,通常情況下用樹形的名稱結構是一個理想的選擇,樹形的名稱結構是一個有層次的目錄結構,既對人友好又不會重複。說到這裏你可能想到了 JNDI,沒錯 Zookeeper 的 Name Service 與 JNDI 能夠完成的功能是差不多的,它們都是將有層次的目錄結構關聯到一定資源上,但是 Zookeeper 的 Name Service 更加是廣泛意義上的關聯,也許你並不需要將名稱關聯到特定資源上,你可能只需要一個不會重複名稱,就像數據庫中產生一個唯一的數字主鍵一樣。
Name Service 已經是 Zookeeper 內置的功能,你只要調用 Zookeeper 的 API 就能實現。如調用 create 接口就可以很容易創建一個目錄節點。
命名服務也是分佈式系統中比較常見的一類場景。在分佈式系統中,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源或服務的地址,提供者等信息。被命名的實體通常可以是集羣中的機器,提供的服務地址,遠程對象等等——這些我們都可以統稱他們爲名字(Name)`。其中較爲常見的就是一些分佈式服務框架中的服務地址列表。通過調用ZK提供的創建節點的API,能夠很容易創建一個全局唯一的path,這個path就可以作爲一個名稱。
命名服務實例:
阿里巴巴集團開源的分佈式服務框架Dubbo中使用ZooKeeper來作爲其命名服務,維護全局的服務地址列表,在Dubbo實現中:
服務提供者在啓動的時候,向ZK上的指定節點/dubbo/${serviceName}/providers目錄下寫入自己的URL地址,這個操作就完成了服務的發佈。
服務消費者啓動的時候,訂閱/dubbo/${serviceName}/providers目錄下的提供者URL地址, 並向/dubbo/${serviceName} /consumers目錄下寫入自己的URL地址。
注意,所有向ZK上註冊的地址都是臨時節點,這樣就能夠保證服務提供者和消費者能夠自動感應資源的變化。 另外,Dubbo還有針對服務粒度的監控,方法是訂閱/dubbo/${serviceName}目錄下所有提供者和消費者的信息。
3.2 配置管理(Configuration Management)
配置的管理在分佈式應用環境中很常見,例如同一個應用系統需要多臺 PC Server 運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那麼就必須同時修改每臺運行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。
像這樣的配置信息完全可以交給 Zookeeper 來管理,將配置信息保存在 Zookeeper 的某個目錄節點中,然後將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每臺應用機器就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置信息應用到系統中。
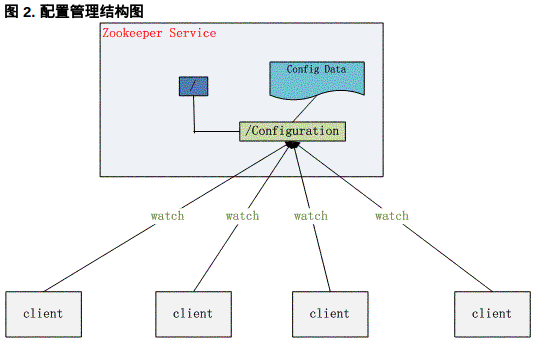
發佈與訂閱模型,即所謂的配置中心,顧名思義就是發佈者將數據發佈到ZK節點上,供訂閱者動態獲取數據,實現配置信息的集中式管理和動態更新。例如全局的配置信息,服務式服務框架的服務地址列表等就非常適合使用。
配置管理實例:
-
應用中用到的一些配置信息放到ZK上進行集中管理。這類場景通常是這樣:應用在啓動的時候會主動來獲取一次配置,同時,在節點上註冊一個Watcher,這樣一來,以後每次配置有更新的時候,都會實時通知到訂閱的客戶端,從而達到獲取最新配置信息的目的。 -
分佈式搜索服務中,索引的元信息和服務器集羣機器的節點狀態存放在ZK的一些指定節點,供各個客戶端訂閱使用。 -
分佈式日誌收集系統。這個系統的核心工作是收集分佈在不同機器的日誌。收集器通常是按照應用來分配收集任務單元,因此需要在ZK上創建一個以應用名作爲path的節點P,並將這個應用的所有機器ip,以子節點的形式註冊到節點P上,這樣一來就能夠實現機器變動的時候,能夠實時通知到收集器調整任務分配。 -
系統中有些信息需要動態獲取,並且還會存在人工手動去修改這個信息的發問。通常是暴露出接口,例如JMX接口,來獲取一些運行時的信息。引入ZK之後,就不用自己實現一套方案了,只要將這些信息存放到指定的ZK節點上即可。
注意:在上面提到的應用場景中,有個默認前提是:數據量很小,但是數據更新可能會比較快的場景。
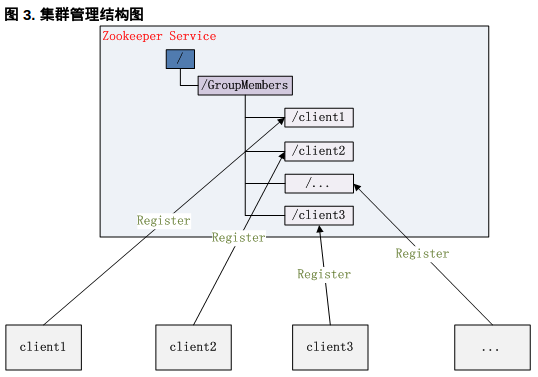
3.3 集羣管理(Group Membership)
Zookeeper 能夠很容易的實現集羣管理的功能,如有多臺 Server 組成一個服務集羣,那麼必須要一個“總管”知道當前集羣中每臺機器的服務狀態,一旦有機器不能提供服務,集羣中其它集羣必須知道,從而做出調整重新分配服務策略。同樣當增加集羣的服務能力時,就會增加一臺或多臺 Server,同樣也必須讓“總管”知道。
Zookeeper 不僅能夠幫你維護當前的集羣中機器的服務狀態,而且能夠幫你選出一個“總管”,讓這個總管來管理集羣,這就是 Zookeeper 的另一個功能 Leader Election。
它們的實現方式都是在 Zookeeper 上創建一個 EPHEMERAL 類型的目錄節點,然後每個 Server 在它們創建目錄節點的父目錄節點上調用 getChildren(String path, boolean watch) 方法並設置 watch 爲 true`,由於是 EPHEMERAL 目錄節點,當創建它的 Server 死去,這個目錄節點也隨之被刪除,所以 Children 將會變化,這時 getChildren上的 Watch 將會被調用,所以其它 Server 就知道已經有某臺 Server 死去了。新增 Server 也是同樣的原理。
Zookeeper 如何實現 Leader Election,也就是選出一個 Master Server。和前面的一樣每臺 Server 創建一個 EPHEMERAL 目錄節點,不同的是它還是一個 SEQUENTIAL 目錄節點,所以它是個 EPHEMERAL_SEQUENTIAL 目錄節點。之所以它是 EPHEMERAL_SEQUENTIAL 目錄節點,是因爲我們可以給每臺 Server 編號,我們可以選擇當前是最小編號的 Server 爲 Master,假如這個最小編號的 Server 死去,由於是 EPHEMERAL 節點,死去的 Server 對應的節點也被刪除,所以當前的節點列表中又出現一個最小編號的節點,我們就選擇這個節點爲當前 Master。這樣就實現了動態選擇 Master,避免了傳統意義上單 Master 容易出現單點故障的問題。
1. 集羣機器監控
這通常用於那種對集羣中機器狀態,機器在線率有較高要求的場景,能夠快速對集羣中機器變化作出響應。這樣的場景中,往往有一個監控系統,實時檢測集羣機器是否存活。過去的做法通常是:監控系統通過某種手段(比如ping)定時檢測每個機器,或者每個機器自己定時向監控系統彙報“我還活着”。 這種做法可行,但是存在兩個比較明顯的問題:
-
集羣中機器有變動的時候,牽連修改的東西比較多。
-
有一定的延時。
利用ZooKeeper有兩個特性,就可以實現另一種集羣機器存活性監控系統:
-
客戶端在節點 x 上註冊一個Watcher,那麼如果 x 的子節點變化了,會通知該客戶端。 -
創建EPHEMERAL類型的節點,一旦客戶端和服務器的會話結束或過期,那麼該節點就會消失。
例如:監控系統在 /clusterServers 節點上註冊一個Watcher,以後每動態加機器,那麼就往 /clusterServers 下創建一個 EPHEMERAL類型的節點:/clusterServers/{hostname}. 這樣,監控系統就能夠實時知道機器的增減情況,至於後續處理就是監控系統的業務了。
2. Master選舉則是zookeeper中最爲經典的應用場景了
在分佈式環境中,相同的業務應用分佈在不同的機器上,有些業務邏輯(例如一些耗時的計算,網絡I/O處理),往往只需要讓整個集羣中的某一臺機器進行執行,其餘機器可以共享這個結果,這樣可以大大減少重複勞動,提高性能,於是這個master選舉便是這種場景下的碰到的主要問題。
利用ZooKeeper的強一致性,能夠保證在分佈式高併發情況下節點創建的全局唯一性,即:同時有多個客戶端請求創建 /currentMaster 節點,最終一定只有一個客戶端請求能夠創建成功。利用這個特性,就能很輕易的在分佈式環境中進行集羣選取了。
另外,這種場景演化一下,就是動態Master選舉。這就要用到EPHEMERAL_SEQUENTIAL類型節點的特性了。
上文中提到,所有客戶端創建請求,最終只有一個能夠創建成功。在這裏稍微變化下,就是允許所有請求都能夠創建成功,但是得有個創建順序,於是所有的請求最終在ZK上創建結果的一種可能情況是這樣: /currentMaster/{sessionId}-1 ,/currentMaster/{sessionId}-2,/currentMaster/{sessionId}-3 ….. 每次選取序列號最小的那個機器作爲Master,如果這個機器掛了,由於他創建的節點會馬上消失,那麼之後最小的那個機器就是Master了。
3. 在搜索系統中,如果集羣中每個機器都生成一份全量索引,不僅耗時,而且不能保證彼此之間索引數據一致。因此讓集羣中的Master來進行全量索引的生成,然後同步到集羣中其它機器。另外,Master選舉的容災措施是,可以隨時進行手動指定master,就是說應用在zk在無法獲取master信息時,可以通過比如http方式,向一個地方獲取master。
4. 在Hbase中,也是使用ZooKeeper來實現動態HMaster的選舉。在Hbase實現中,會在ZK上存儲一些ROOT表的地址和HMaster的地址,HRegionServer也會把自己以臨時節點(Ephemeral)的方式註冊到Zookeeper中,使得HMaster可以隨時感知到各個HRegionServer的存活狀態,同時,一旦HMaster出現問題,會重新選舉出一個HMaster來運行,從而避免了HMaster的單點問題。
3.4 共享鎖(Locks)
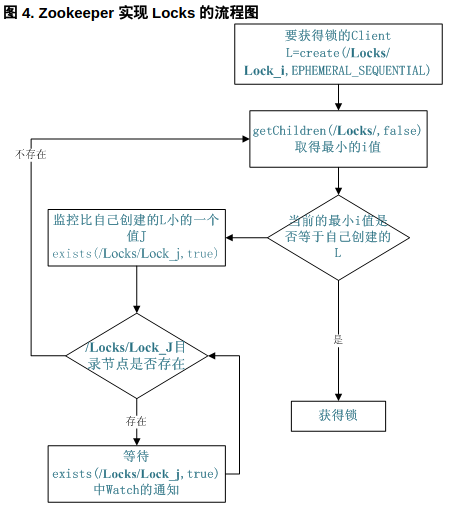
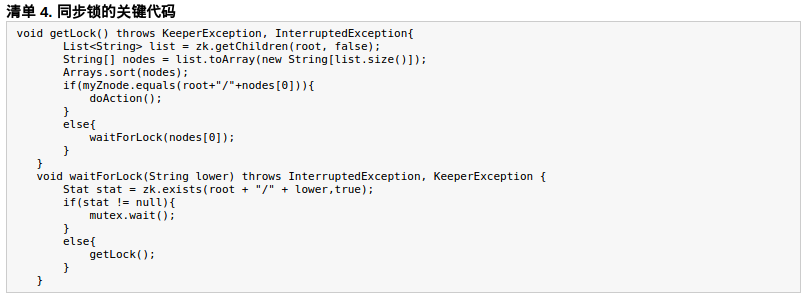
共享鎖在同一個進程中很容易實現,但是在跨進程或者在不同 Server 之間就不好實現了。Zookeeper 卻很容易實現這個功能,實現方式也是需要獲得鎖的 Server 創建一個 EPHEMERAL_SEQUENTIAL 目錄節點,然後調用 getChildren方法獲取當前的目錄節點列表中最小的目錄節點是不是就是自己創建的目錄節點,如果正是自己創建的,那麼它就獲得了這個鎖,如果不是那麼它就調用 exists(String path, boolean watch) 方法並監控 Zookeeper 上目錄節點列表的變化,一直到自己創建的節點是列表中最小編號的目錄節點,從而獲得鎖,釋放鎖很簡單,只要刪除前面它自己所創建的目錄節點就行了。
分佈式鎖,這個主要得益於ZooKeeper爲我們保證了數據的強一致性。鎖服務可以分爲兩類,一個是保持獨佔,另一個是控制時序。
-
所謂保持獨佔,就是所有試圖來獲取這個鎖的客戶端,最終只有一個可以成功獲得這把鎖。通常的做法是把zk上的一個znode看作是一把鎖,通過create znode的方式來實現。
所有客戶端都去創建 /distribute_lock 節點,最終成功創建的那個客戶端也即擁有了這把鎖。 -
控制時序,就是所有視圖來獲取這個鎖的客戶端,最終都是會被安排執行,只是有個全局時序了。做法和上面基本類似,只是這裏 /distribute_lock 已經預先存在,客戶端在它下面創建臨時有序節點(這個可以通過節點的屬性控制:CreateMode.EPHEMERAL_SEQUENTIAL來指定)。Zk的父節點(/distribute_lock)維持一份sequence,保證子節點創建的時序性,從而也形成了每個客戶端的全局時序。
3.5 隊列管理
Zookeeper 可以處理兩種類型的隊列:
-
當一個隊列的成員都聚齊時,這個隊列纔可用,否則一直等待所有成員到達,這種是同步隊列。 -
隊列按照 FIFO 方式進行入隊和出隊操作,例如實現生產者和消費者模型。
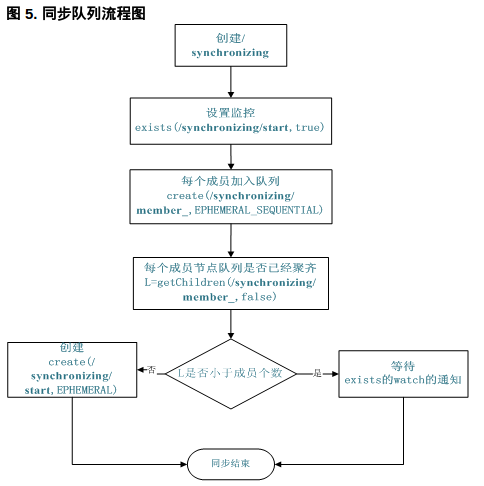
同步隊列用 Zookeeper 實現的實現思路如下:
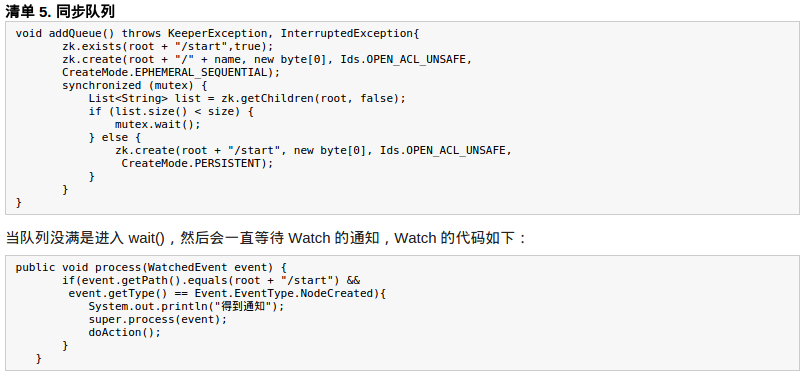
創建一個父目錄 /synchronizing,每個成員都監控標誌(Set Watch)位目錄 /synchronizing/start 是否存在,然後每個成員都加入這個隊列,加入隊列的方式就是創建 /synchronizing/member_i 的臨時目錄節點,然後每個成員獲取 / synchronizing 目錄的所有目錄節點,也就是 member_i。判斷 i 的值是否已經是成員的個數,如果小於成員個數等待 /synchronizing/start 的出現,如果已經相等就創建 /synchronizing/start。
FIFO 隊列用 Zookeeper 實現思路如下:
實現的思路也非常簡單,就是在特定的目錄下創建 SEQUENTIAL 類型的子目錄 /queue_i,這樣就能保證所有成員加入隊列時都是有編號的`,出隊列時通過 getChildren( ) 方法可以返回當前所有的隊列中的元素,然後消費其中最小的一個,這樣就能保證 FIFO。
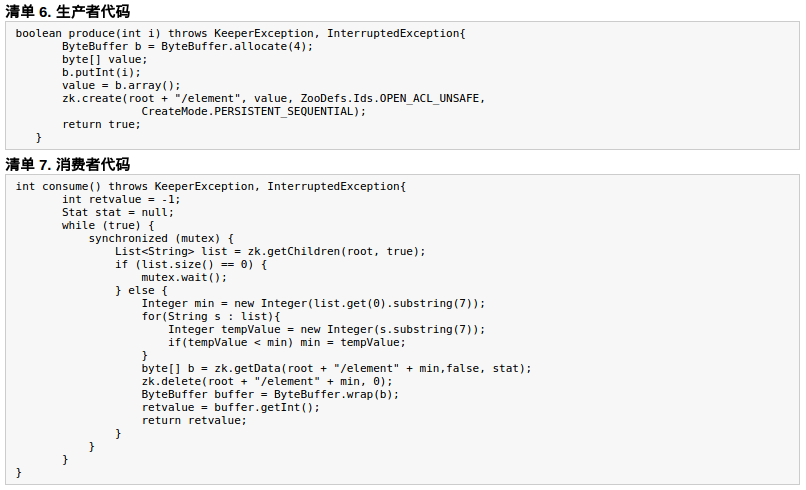
3.6 負載均衡
這裏說的負載均衡是指軟負載均衡。在分佈式環境中,爲了保證高可用性,通常同一個應用或同一個服務的提供方都會部署多份,達到對等服務。而消費者就須要在這些對等的服務器中選擇一個來執行相關的業務邏輯,其中比較典型的是消息中間件中的生產者,消費者負載均衡。
消息中間件中發佈者和訂閱者的負載均衡,linkedin開源的KafkaMQ和阿里開源的metaq都是通過zookeeper來做到生產者、消費者的負載均衡`。這裏以metaq爲例如講下:
生產者負載均衡:metaq發送消息的時候,生產者在發送消息的時候必須選擇一臺broker上的一個分區來發送消息,因此metaq在運行過程中,會把所有broker和對應的分區信息全部註冊到ZK指定節點上,默認的策略是一個依次輪詢的過程,生產者在通過ZK獲取分區列表之後,會按照brokerId和partition的順序排列組織成一個有序的分區列表,發送的時候按照從頭到尾循環往復的方式選擇一個分區來發送消息。
消費負載均衡: 在消費過程中,一個消費者會消費一個或多個分區中的消息,但是一個分區只會由一個消費者來消費。MetaQ的消費策略是:
-
每個分區針對同一個group只掛載一個消費者。
-
如果同一個group的消費者數目大於分區數目,則多出來的消費者將不參與消費。
-
如果同一個group的消費者數目小於分區數目,則有部分消費者需要額外承擔消費任務。
在某個消費者故障或者重啓等情況下,其他消費者會感知到這一變化(通過 zookeeper watch消費者列表),然後重新進行負載均衡,保證所有的分區都有消費者進行消費。
3.7 分佈式通知/協調
ZooKeeper中特有watcher註冊與異步通知機制,能夠很好的實現分佈式環境下不同系統之間的通知與協調,實現對數據變更的實時處理。使用方法通常是不同系統都對ZK上同一個znode進行註冊,監聽znode的變化(包括znode本身內容及子節點的),其中一個系統update了znode,那麼另一個系統能夠收到通知,並作出相應處理。
-
另一種心跳檢測機制:檢測系統和被檢測系統之間並不直接關聯起來,而是通過zk上某個節點關聯,大大減少系統耦合。 -
另一種系統調度模式:某系統有控制檯和推送系統兩部分組成,控制檯的職責是控制推送系統進行相應的推送工作。管理人員在控制檯作的一些操作,實際上是修改了ZK上某些節點的狀態,而ZK就把這些變化通知給他們註冊Watcher的客戶端,即推送系統,於是,作出相應的推送任務。 -
另一種工作彙報模式:一些類似於任務分發系統,子任務啓動後,到zk來註冊一個臨時節點,並且定時將自己的進度進行彙報(將進度寫回這個臨時節點),這樣任務管理者就能夠實時知道任務進度。
總之,使用zookeeper來進行分佈式通知和協調能夠大大降低系統之間的耦合。
二:典型場景描述總結
數據發佈與訂閱(配置管理)
發佈與訂閱即所謂的配置管理,顧名思義就是將數據發佈到zk節點上,供訂閱者動態獲取數據,實現配置信息的集中式管理和動態更新。
例如全局的配置信息,地址列表等就非常適合使用。
發佈/訂閱系統一般有兩種設計模式,分別是推(Push)模式和拉(Pull)模式。
推模式
服務端主動將數據更新發送給所有訂閱的客戶端。
拉模式
客戶端通過採用定時輪詢拉取。
ZooKeeper採用的是推拉相結合的方式:客戶端向服務端註冊自己需要關注的節點,一旦該節點的數據發生變更,那麼服務端就會向相應的客戶端發送Watcher事件通知,客戶端接收到這個消息通知之後,需要主動到服務端獲取最新的數據。
負載均衡
負載均衡(Load Balance)是一種相當常見的計算機網絡技術,用來對多個計算機(計算機集羣)、網絡連接、CPU、硬盤驅動器或其他資源進行分配負載,以達到優化資源使用、最大化吞吐率、最小化響應時間和避免過載的目的。通常,負載均衡可以分爲硬件和軟件負載均衡兩類
分佈通知/協調
分佈式協調/通知是將不同的分佈式組件有機結合起來的關鍵所在。對於一個在多臺機器上部署運行的應用而言,通常需要一個協調者(Coordinator)來控制整個系統的運行流程,例如分佈式事務的處理、機器間的相互協調等。同時,引入這樣一個協調者,便於將分佈式協調的職責從應用中分離出來,從而大大減少系統之間的耦合性,而且能夠顯著提高系統的可擴展性。
ZooKeeper 中特有watcher註冊與異步通知機制,能夠很好的實現分佈式環境下不同系統之間的通知與協調,實現對數據變更的實時處理。
使用方法通常是不同系統都對 ZK上同一個znode進行註冊,監聽znode的變化(包括znode本身內容及子節點的),其中一個系統update了znode,那麼另一個系統能 夠收到通知,並作出相應處理。
\1. 另一種心跳檢測機制:檢測系統和被檢測系統之間並不直接關聯起來,而是通過zk上某個節點關聯,大大減少系統耦合。
\2. 另一種系統調度模式:某系統有控制檯和推送系統兩部分組成,控制檯的職責是控制推送系統進行相應的推送工作。管理人員在控制檯作的一些操作,實際上是修改 了ZK上某些節點的狀態,而zk就把這些變化通知給他們註冊Watcher的客戶端,即推送系統,於是,作出相應的推送任務。
\3. 另一種工作彙報模式:一些類似於任務分發系統,子任務啓動後,到zk來註冊一個臨時節點,並且定時將自己的進度進行彙報(將進度寫回這個臨時節點),這樣任務管理者就能夠實時知道任務進度。總之,使用zookeeper來進行分佈式通知和協調能夠大大降低系統之間的耦合。
命名服務
在分佈式系統中,被命名的實體通常是集羣中的機器、提供的服務地址或遠程對象等--這些我們都可以統稱他們爲名字,其中比較常見的就是一些分佈式服務框架(RPC、RMI)中的服務地址列表,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源的實體、服務地址和提供者信息等。
ZooKeeper提供的命名服務功能與JNDI技術有類似的地方,都能夠幫助應用系統通過一個資源引用的方式來實現對資源的定位與使用。另外,廣義上命名服務的資源定位都不是真正意義的實體資源--在分佈式環境中,上層應用僅僅需要一個全局唯一的名字,類似於數據庫的唯一主鍵。,通過調用zk的create node api,能夠很容易創建一個全局唯一的path,這個path就可以作爲一個名稱。所謂ID,就是一個能唯一標識某個對象的標識符。
分佈式鎖
分佈式鎖,這個主要得益於ZooKeeper爲我們保證了數據的強一致性,即用戶只要完全相信每時每刻,zk集羣中任意節點(一個zk server)上的相同znode的數據是一定是相同的。鎖服務可以分爲兩類,一個是保持獨佔,另一個是控制時序。
保持獨佔:就是所有試圖來獲取這個鎖的客戶端,最終只有一個可以成功獲得這把鎖。通常的做法是把zk上的一個znode看作是一把鎖,通過create znode的方式來實現。所有客戶端都去創建 /distribute_lock 節點,最終成功創建的那個客戶端也即擁有了這把鎖。
控制時序:就是所有視圖來獲取這個鎖的客戶端,最終都是會被安排執行,只是有個全局時序了。
做法和上面基本類似,只是這裏 /distribute_lock 已經預先存在,客戶端在它下面創建臨時有序節點
(這個可以通過節點的屬性控制:CreateMode.EPHEMERAL_SEQUENTIAL來指定)。Zk的父節點(/distribute_lock)維持一份sequence,保證子節點創建的時序性,從而也形成了每個客戶端的全局時序。
原理:(藉助Zookeeper 可以實現這種分佈式鎖:需要獲得鎖的 Server 創建一個 EPHEMERAL_SEQUENTIAL 目錄節點,然後調用 getChildren()方法獲取列表中最小的目錄節點,如果最小節點就是自己創建的目錄節點,那麼它就獲得了這個鎖,如果不是那麼它就調用 exists() 方法並監控前一節點的變化,一直到自己創建的節點成爲列表中最小編號的目錄節點,從而獲得鎖。釋放鎖很簡單,只要刪除它自己所創建的目錄節點就行了。)
集羣管理
\1. 集羣機器監控:這通常用於那種對集羣中機器狀態,機器在線率有較高要求的場景,能夠快速對集羣中機器變化作出響應。這樣的場景中,往往有一個監控系統,實時檢測集羣機器是否存活。過去的做法通常是:監控系統通過某種手段(比如ping)定時檢測每個機器,或者每個機器自己定時向監控系統彙報“我還活着”。 這種做法可行,但是存在兩個比較明顯的問題:
\1. 集羣中機器有變動的時候,牽連修改的東西比較多。
\2. 有一定的延時。利用ZooKeeper有兩個特性,就可以實時另一種集羣機器存活性監控系統:
a. 客戶端在節點 x 上註冊一個Watcher,那麼如果 x 的子節點變化了,會通知該客戶端。
b. 創建EPHEMERAL類型的節點,一旦客戶端和服務器的會話結束或過期,那麼該節點就會消失。
應用:
Master選舉
則是zookeeper中最爲經典的使用場景了。
在分佈式環境中,相同的業務應用分佈在不同的機器上,有些業務邏輯(例如一些耗時的計算,網絡I/O處理),往往只需要讓整個集羣中的某一臺機器進行執行, 其餘機器可以共享這個結果,這樣可以大大減少重複勞動,提高性能,於是這個master選舉便是這種場景下的碰到的主要問題。
利用ZooKeeper的強一致性,能夠保證在分佈式高併發情況下節點創建的全局唯一性,即:同時有多個客戶端請求創建 /currentMaster 節點,最終一定只有一個客戶端請求能夠創建成功。
分佈式隊列
兩種類型的隊列:
1、 同步隊列,當一個隊列的成員都聚齊時,這個隊列纔可用,否則一直等待所有成員到達。
2、隊列按照 FIFO 方式進行入隊和出隊操作。
第一類,在約定目錄下創建臨時目錄節點,監聽節點數目是否是我們要求的數目。
第二類,和分佈式鎖服務中的控制時序場景基本原理一致,入列有編號,出列按編號。
同步隊列。一個job由多個task組成,只有所有任務完成後,job才運行完成。可爲job創建一個/job目錄,然後在該目錄下,爲每個完成的task創建一個臨時znode,一旦臨時節點數目達到task總數,則job運行完成。