




4.1 依存句法分析
依存語法 (Dependency Parsing, DP) 通過分析語言單位內成分之間的依存關係揭示其句法結構。 直觀來講,依存句法分析識別句子中的“主謂賓”、“定狀補”這些語法成分,並分析各成分之間的關係。
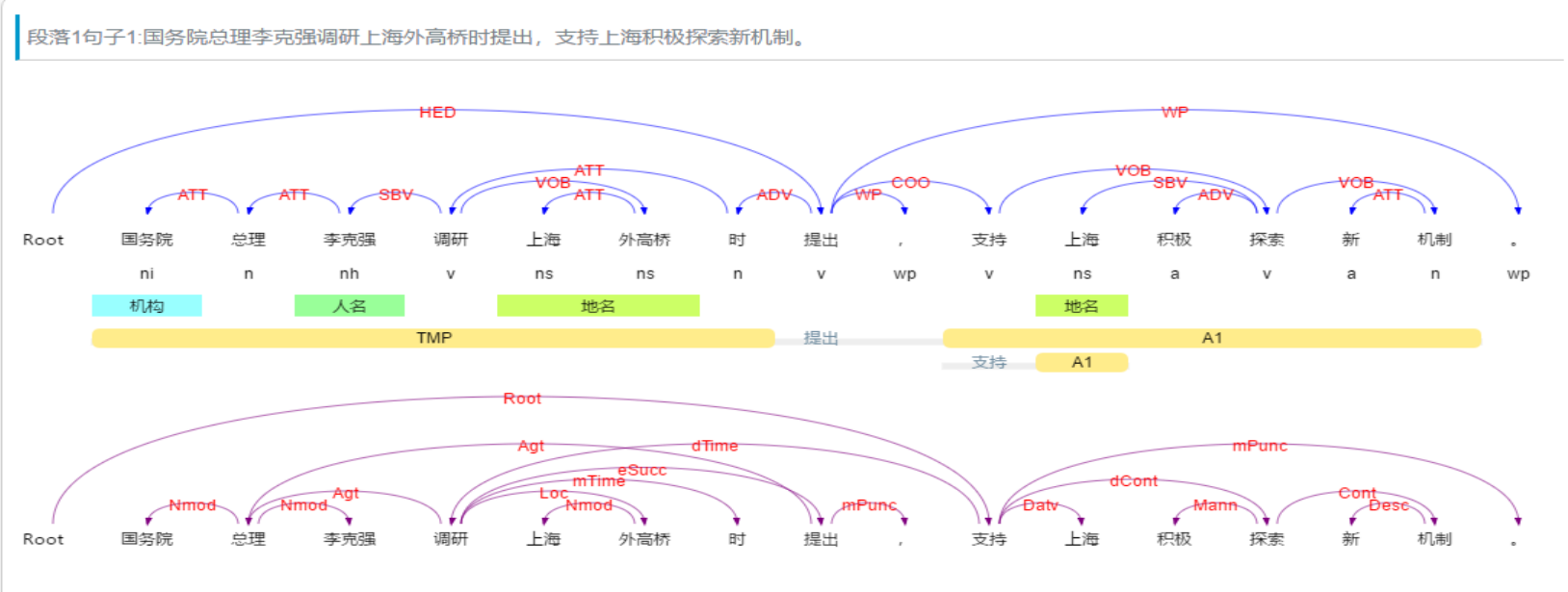
上面的例子,其分析結果爲:
• 從分析結果中我們可以看到,句子的核心謂詞爲“提出”,主語是“×××”,提出的賓語是“支持上海...”,“調研...時”是“提出”的(時間)狀語,“×××”的修飾語是“×××總理”,“支持”的賓語是“探索新機制”。有了上面的句法分析結果,我們就可以比較容易的看到,“提出者”是“×××”,而丌是“上海”戒“外高橋”,即使它們都是名詞,而且距離“提出”更近。
依存句法分析標註關係 (共14種) 及含義如下:
• 關係類型 Tag Description Example
主謂關係 SBV subject-verb 我送她一束花 (我 <– 送)
動賓關係 VOB 直接賓語,verb-object 我送她一束花 (送 –> 花)
間賓關係 IOB 間接賓語,indirect-object 我送她一束花 (送 –> 她)
前置賓語 FOB 前置賓語,fronting-object 他什麼乢都讀 (乢 <– 讀)
兼語 DBL double 他請我吃飯 (請 –> 我)
定中關係 ATT attribute 紅蘋果 (紅 <– 蘋果)
狀中結構 ADV adverbial 非常美麗 (非常 <– 美麗)
動補結構 CMP complement 做完了作業 (做 –> 完)
並列關係 COO coordinate 大山和大海 (大山 –> 大海)
介賓關係 POB preposition-object 在貿易區內 (在 –> 內)
左附加關係 LAD left adjunct 大山和大海 (和 <– 大海)
右附加關係 RAD right adjunct 孩子們 (孩子 –> 們)
獨立結構 IS independent structure 兩個單句在結構上彼此獨立
核心關係 HED head 指整個句子的核心4.2 語義依存分析 (Semantic Dependency Parsing, SDP)
語義依存分析:分析句子各個語言單位之間的語義關聯,並將語義關聯以依存結構呈現。使用語義依存刻畫句子語義,好處在於丌需要去抽象詞彙本身,而是通過詞彙所承受的語義框架來描述該詞彙,而論元的數目相對詞彙來說數量總是少了很多的。語義依存分析目標是跨越句子表層句法結構的束縛,直接獲取深層的語義信息。 例如以下三個句子,用不同的表達方式表達了同一個語義信息,即張三實施了一個吃的動作,吃的動作是對蘋果實施的。
• 語義依存分析不受句法結構的影響,將具有直接語義關聯的語言單元直接連接依存弧並標記上相應的語義關係。這也是語義依存分析不句法依存分析的重要區別。
• 語義依存關係分爲三類,分別是主要語義角色,每一種語義角色對應存在一個嵌套關係和反關係;事件關係,描述兩個事件間的關係;語義依附標記,標記說話者語氣等依附性信息。

語義依存分析標註關係及含義如下:
關係類型 Tag Description Example
施事關係 Agt Agent 我送她一束花 (我 <-- 送)
當事關係 Exp Experiencer 我跑得快 (跑 --> 我)
感事關係 Aft Affection 我思念家鄉 (思念 --> 我)
領事關係 Poss Possessor 他有一本好讀 (他 <-- 有)
受事關係 Pat Patient 他打了××× (打 --> ×××)
客事關係 Cont Content 他聽到×××聲 (聽 --> ×××聲)
成事關係 Prod Product 他寫了本小說 (寫 --> 小說)
源事關係 Orig Origin 我軍繳獲敵人四輛坦克 (繳獲 --> 坦克)
涉事關係 Datv Dative 他告訴我個祕密 ( 告訴 --> 我 )
比較角色 Comp Comitative 他成績比我好 (他 --> 我)
屬事角色 Belg Belongings 老趙有倆女兒 (老趙 <-- 有)
類事角色 Clas Classification 他是中學生 (是 --> 中學生)
依據角色 Accd According 本庭依法宣判 (依法 <-- 宣判)
緣故角色 Reas Reason 他在愁女兒婚事 (愁 --> 婚事)
。。。。。。4.3 自定義語法與CFG
什麼是語法解析?
• 在自然語言學習過程中,每個人一定都學過語法,例如句子可以用主語、謂語、賓語來表示。在自然語言的處理過程中,有許多應用場景都需要考慮句子的語法,因此研究語法解析變得非常重要。
• 語法解析有兩個主要的問題,其一是句子語法在計算機中的表達與存儲方法,以及語料數據集;其二是語法解析的算法。
4.3.1 句子語法在計算機中的表達與存儲方法
• 對於第一個問題,我們可以用樹狀結構圖來表示,如下圖所示,S表示句子;NP、VP、PP是名詞、動詞、介詞短語(短語級別);N、V、P分別是名詞、動詞、介詞。

4.3.2 語法解析的算法
上下文無關語法(Context-Free Grammer)
• 爲了生成句子的語法樹,我們可以定義如下的一套上下文無關語法。
• 1)N表示一組非葉子節點的標註,例如{S、NP、VP、N...}
• 2)Σ表示一組葉子結點的標註,例如{boeing、is...}
• 3)R表示一組覎則,每條規則可以表示爲
• 4)S表示語法樹開始的標註
• 舉例來說,語法的一個語法子集可以表示爲下圖所示。
當給定一個句子時,我們便可以按照從左到右的順序來解析語法。
例如,句子the man sleeps就可以表示爲(S (NP (DT the) (NN man)) (VP sleeps))。
概率分佈的上下文無關語法(Probabilistic Context-Free Grammar)
• 上下文無關的語法可以很容易的推導出一個句子的語法結構,但是缺點是推導出的結構可能存在二義性。
• 由於語法的解析存在二義性,我們就需要找到一種方法從多種可能的語法樹中找出最可能的一棵樹。
一種常見的方法既是PCFG (Probabilistic Context-Free Grammar)。
如下圖所示,除了常見的語法規則以外,我們還對每一條規則賦予了一個概率。
對於每一棵生成的語法樹,我們將其中所有規則的概率的乘積作爲語法樹的出現概率。
當我們獲得多顆語法樹時,我們可以分別計算每顆語法樹的概率p(t),
出現概率最大的那顆語法樹就是我們希望得到的結果,即arg max p(t)。
訓練算法
• 我們已經定義了語法解析的算法,而這個算法依賴於CFG中對於N、Σ、
R、S的定義以及PCFG中的p(x)。上文中我們提到了Penn Treebank通
過手工的方法已經提供了一個非常大的語料數據集,我們的任務就是從
語料庫中訓練出PCFG所需要的參數。
• 1)統計出語料庫中所有的N與Σ;
• 2)利用語料庫中的所有規則作爲R;
• 3)針對每個規則A -> B,從語料庫中估算p(x) = p(A -> B) / p(A);
• 在CFG的定義的基礎上,我們重新定義一種叫Chomsky的語法格式。
這種格式要求每條規則只能是X -> Y1 Y2或者X -> Y的格式。實際上
Chomsky語法格式保證生產的語法樹總是二叉樹的格式,同時任意一
棵語法樹總是能夠轉化成Chomsky語法格式。語法樹預測算法
• 假設我們已經有一個PCFG的模型,包含N、Σ、R、S、p(x)等參數,並
且語法樹總是Chomsky語法格式。當輸入一個句子x1, x2, ... , xn時,
我們要如何計算句子對應的語法樹呢?
• 第一種方法是暴力遍歷的方法,每個單詞x可能有m = len(N)種取值,
句子長度是n,每種情況至少存在n個規則,所以在時間複雜度O(m n n)
的情況下,我們可以判斷出所有可能的語法樹並計算出最佳的那個。
• 第二種方法當然是動態規劃,我們定義w[i, j, X]是第i個單詞至第j個單
詞由標註X來表示的最大概率。直觀來講,例如xi, xi+1, ... , xj,當
X=PP時,子樹可能是多種解釋方式,如(P NP)或者(PP PP),但是w[i,
j, PP]代表的是繼續往上一層遞歸時,我們只選擇當前概率最大的組合
方式。
語法解析按照上述的算法過程便完成了。雖說PCFG也有一些缺點,例
如:1)缺乏詞法信息;2)連續短語(如名詞、介詞)的處理等。但總體來講它給語法解析提供了一種非常有效的實現方法。