




服务器的衡量标准:
计算机系统的可用性(availability)是通过系统的可靠性(reliability)和可维护性(maintainability)来度量的。工程上通常用平均无故障时间(MTTF)来度量系统的可靠性,用平均维修时间(MTTR)来度量系统的可维护性。于是可用性被定义为:MTTF/(MTTF+MTTR)*100%
99.9% 一年宕机时间不超过10h
99.999% 一年宕机时间不超过6min
如何提高服务器的可用性呢,这就需要使用HA(high availability)集群,一般是由多个节点的来组成。
99.9% 一年宕机时间不超过10h
99.999% 一年宕机时间不超过6min
如何提高服务器的可用性呢,这就需要使用HA(high availability)集群,一般是由多个节点的来组成。
HA集群是集群中较为常见的一种,当硬件和软件系统发生故障的时候,运行在集群系统中的数据不易丢失,而且能在尽可能短的时间里恢复正常运行。
双机热备是HA集群中常见的一种解决方案,双机热备按照工作方式不同可以分为一下几种:
1.主-备(active-standby)主 - 备方式即指的是一台服务器处于某种业务的激活状态,另一台服务器处于该业务的备用状态;
2.主-主(active-active)双主机方式即指两种不同业务分别在两台服务器上互为主备状态;
1.主-备(active-standby)主 - 备方式即指的是一台服务器处于某种业务的激活状态,另一台服务器处于该业务的备用状态;
2.主-主(active-active)双主机方式即指两种不同业务分别在两台服务器上互为主备状态;
主服务器&&备用服务器
主服务器和备用服务器是建立双机热备的基本条件。两个系统上的数据库服务器共享同一个数据库文件。通常情况下,数据库文件挂靠在主数据库服务器上,用户连接到主服务器上进行数据库操作。当主服务器出现故障时,备用服务器会自动连接数据库文件,并接替主系统的工作。用户在未告知的情况下,通过备用数据库连接到数据库文件进行操作。等主服务器的故障修复之后,又可以重新加入集群;
主服务器和备用服务器是建立双机热备的基本条件。两个系统上的数据库服务器共享同一个数据库文件。通常情况下,数据库文件挂靠在主数据库服务器上,用户连接到主服务器上进行数据库操作。当主服务器出现故障时,备用服务器会自动连接数据库文件,并接替主系统的工作。用户在未告知的情况下,通过备用数据库连接到数据库文件进行操作。等主服务器的故障修复之后,又可以重新加入集群;
说到这里,那么备用服务器是如何知道主服务器挂掉了呢,这就要使用一定的机制,如心跳检测,也就是说每一个节点都会定期向其他节点通知自己的心跳信息,尤其主服务器,如果备用服务器在3~5个心跳周期还没有检测到的话,就认为主服务器宕掉了,而这期间在通告心跳信息当然不能使用tcp的,如果使用tcp检测,还要经过三次握手,等手握完了,不定经过几个心跳周期了,所以在检测心跳信息的时候采用的是udp的端口号694进行传递信息的
如果主服务器在某一端时间由于服务繁忙,没时间响应心跳信息,如果这个时候备用服务器要是一下子把服务资源抢过去,但是这个时候主服务器还没有宕掉,这样就会导致资源抢占,就这样用户在主辅上都能访问,如果仅仅是读操作还没事,要是有写的操作,那就会导致文件系统崩溃,这样一切都玩了,所以在资源抢占的时候,可以采用一定的隔离方法,来实现,就是备用服务器抢占资源的时候,直接把主服务器给“一脚踹死”;
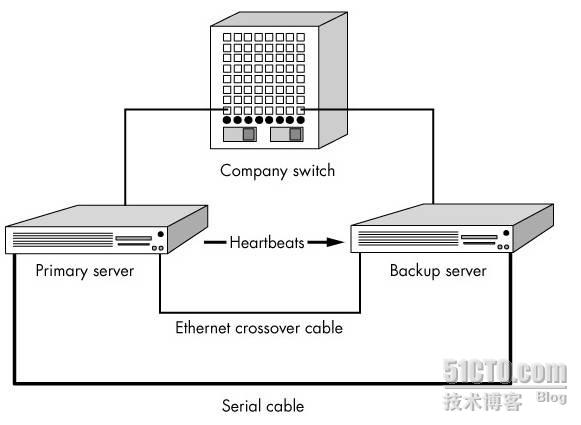
运行于备用主机上的Heartbeat可以通过以太网连接检测主服务器的运行状态,一旦其无法检测到主服务器的“心跳”则自动接管主服务器的资源。通常情况下,主、备服务器间的心跳连接是一个独立的物理连接,这个连接可以是串行线缆、一个由“交叉线”实现的以太网连接。Heartbeat甚至可同时通过多个物理连接检测主服务器的工作状态,而其只要能通过其中一个连接收到主服务器处于活动状态的信息,就会认为主服务器处于正常状态。从实践经验的角度来说,建议为Heartbeat配置多条独立的物理连接,以避免Heartbeat通信线路本身存在单点故障。
1、串行电缆:被认为是比以太网连接安全性稍好些的连接方式,因为hacker无法通过串行连接运行诸如telnet、ssh或rsh类的程序,从而可以降低其通过已劫持的服务器再次侵入备份服务器的机率。但串行线缆受限于可用长度,因此主、备服务器的距离必须非常短。
2、以太网连接:使用此方式可以消除串行线缆的在长度方面限制,并且可以通过此连接在主备服务器间同步文件系统,从而减少了从正常通信连接带宽的占用。
3、光电交换机
总体部署如下图所示,当然只是选择其中的一种方式就行了:
![]()
1、串行电缆:被认为是比以太网连接安全性稍好些的连接方式,因为hacker无法通过串行连接运行诸如telnet、ssh或rsh类的程序,从而可以降低其通过已劫持的服务器再次侵入备份服务器的机率。但串行线缆受限于可用长度,因此主、备服务器的距离必须非常短。
2、以太网连接:使用此方式可以消除串行线缆的在长度方面限制,并且可以通过此连接在主备服务器间同步文件系统,从而减少了从正常通信连接带宽的占用。
3、光电交换机
总体部署如下图所示,当然只是选择其中的一种方式就行了:
隔离级别:
1.节点级别:
STONITH:Shoot The Other Node In the Head (俗称“爆头”)呵呵,挺形象的,意思就是直接切断电源;常用的方法是所有节点都接在一个电源交换机上,如果有故障,就直接导致该节点的电压不稳定,或断电,是有故障的节点重启
2.资源级别:
fencing 只是把某种资源截获过来
而对于多节点的集群就要复杂了,在多节点集群中要有个“头头”就是指定的“协调员”DC,就是一个集群中每个几点上都有一个相当于选举票的权值,而这个权值就是根据服务器的性能进行手动分配的,性能好的可以分配的大点,而所有的其他节点都要听从DC的调度,在一个集群中只有选票达到50%以上才能称为集群系统。
如果出现故障了,就会有一个故障转移(failover),设置不同的优先级,可以使故障按照优先级的高低进行转移,选择一个性能好的服务器当DC。
1.节点级别:
STONITH:Shoot The Other Node In the Head (俗称“爆头”)呵呵,挺形象的,意思就是直接切断电源;常用的方法是所有节点都接在一个电源交换机上,如果有故障,就直接导致该节点的电压不稳定,或断电,是有故障的节点重启
2.资源级别:
fencing 只是把某种资源截获过来
而对于多节点的集群就要复杂了,在多节点集群中要有个“头头”就是指定的“协调员”DC,就是一个集群中每个几点上都有一个相当于选举票的权值,而这个权值就是根据服务器的性能进行手动分配的,性能好的可以分配的大点,而所有的其他节点都要听从DC的调度,在一个集群中只有选票达到50%以上才能称为集群系统。
如果出现故障了,就会有一个故障转移(failover),设置不同的优先级,可以使故障按照优先级的高低进行转移,选择一个性能好的服务器当DC。
既然前面讲到了共享存储,下面就简单的介绍一下共享存储的方式:
DAS:(Direct attached storage)设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有耽误时间
RAID
SCSI
NAS:(network attached storage)网络附加存储
文件级别的共享
SAN:(storage area network)存储区域网络
块级别的
模拟的scsi协议
FC光网络(交换机的光接口超贵,有一个差不多2万,如果使用这个,代价太高)
IPSAN(iscsi)存取快,块级别
DAS:(Direct attached storage)设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有耽误时间
RAID
SCSI
NAS:(network attached storage)网络附加存储
文件级别的共享
SAN:(storage area network)存储区域网络
块级别的
模拟的scsi协议
FC光网络(交换机的光接口超贵,有一个差不多2万,如果使用这个,代价太高)
IPSAN(iscsi)存取快,块级别
集群文件系统:GFS2、OCFS2,这只能在集群中使用
HA的架构层次:
从下向上讲:
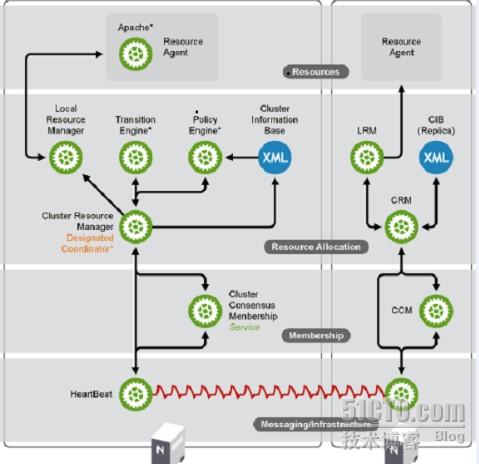
1.Messageing and Infrastructure Layer (信息基础架构层):<套件---heartbeat,keepalive,corosync/openais,RHCS
传递心跳信息的非常重要的子层,通过单独的服务组件来实现,除了心跳信息,还传递集群事务信息
2.Membership 成员层: <套件-----pacemaker(心脏起搏器),cman
(CCM,成员信息)
重新收敛集群成员信息,生成一个概览图,为第三层采取动作提供信息
3.Resource Allocation资源分配层
Cluster Resource Manage(集群资源管理)
LRM,决策本地资源(local resource manage)。定义资源的属性,反映本地资源的信息
policy engine 策略引擎,做决策
transition engine 执行引擎,执行策略引擎做的决定
Cluster information Base 集群信息基础,他是一个包括membership,resoutces,constraints的XML文,在任意一个节点上使用命令进行修改,都会自动的同步到主节点DC的配置文件中去
4.Resource Layer(资源层)
Resource Agent资源代理:就是运行具体的服务,服务启动的脚本,数据文件等资源整体结构如下图所示:
HA的架构层次:
从下向上讲:
1.Messageing and Infrastructure Layer (信息基础架构层):<套件---heartbeat,keepalive,corosync/openais,RHCS
传递心跳信息的非常重要的子层,通过单独的服务组件来实现,除了心跳信息,还传递集群事务信息
2.Membership 成员层: <套件-----pacemaker(心脏起搏器),cman
(CCM,成员信息)
重新收敛集群成员信息,生成一个概览图,为第三层采取动作提供信息
3.Resource Allocation资源分配层
Cluster Resource Manage(集群资源管理)
LRM,决策本地资源(local resource manage)。定义资源的属性,反映本地资源的信息
policy engine 策略引擎,做决策
transition engine 执行引擎,执行策略引擎做的决定
Cluster information Base 集群信息基础,他是一个包括membership,resoutces,constraints的XML文,在任意一个节点上使用命令进行修改,都会自动的同步到主节点DC的配置文件中去
4.Resource Layer(资源层)
Resource Agent资源代理:就是运行具体的服务,服务启动的脚本,数据文件等资源整体结构如下图所示:
heartbeat v1上的配置
总体拓扑如下图所示:
![]()
总体拓扑如下图所示:

一、首先实现两个节点之间的主机相互登录不使用密码,方便后面的使用
Node1上的配置
#ssh-keygen -t rsa //生成公钥和密钥,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //输入密码就行了
Node2上的配置
#ssh-keygen -t rsa //生成公钥和密钥,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //输入密码就行了
二、配置Node1:
1.配置网卡的地址,强烈建议使用静态地址
2.#vim /etc/hosts对所有的节点主机的心跳IP和主机名都写入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.编辑主机名
#vim /etc/sysconfig/network
HOSTNAME=node1.a.org
#hostname node1.a.org
#yum install httpd
#echo "<h1>node1server</h1>" >/var/www/html/index.html
任何集群服务都不能自动启动,而且还不能开机自动启动
#server httpd stop
#chkconfig httpd off
4.安装heartbeat,复制配置文件及配置
Node1上的配置
#ssh-keygen -t rsa //生成公钥和密钥,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //输入密码就行了
Node2上的配置
#ssh-keygen -t rsa //生成公钥和密钥,一步enter到底就行了
## ssh-copy-id -i .ssh/id_rsa [email protected] //输入密码就行了
二、配置Node1:
1.配置网卡的地址,强烈建议使用静态地址
2.#vim /etc/hosts对所有的节点主机的心跳IP和主机名都写入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.编辑主机名
#vim /etc/sysconfig/network
HOSTNAME=node1.a.org
#hostname node1.a.org
#yum install httpd
#echo "<h1>node1server</h1>" >/var/www/html/index.html
任何集群服务都不能自动启动,而且还不能开机自动启动
#server httpd stop
#chkconfig httpd off
4.安装heartbeat,复制配置文件及配置
所需的软件包如下所示

#yum localinstall * -y --nogpgcheck //安装heartbeat软件包
#cd /usr/share/doc/heartbeat-2.1.4/
#cp ha.cf haresources authkeys /etc/ha.d/
#cd /etc/ha.d/
#vim /etc/ha.d/ha.cf
修改如下内容
keepalive 2 //保持时间
deadtime 30 //死亡时间
warntime 10 //警告时间
initdead 120 //启动时间
udpport 694 //使用udp的端口
bcast eth1 //心跳接口
logfile /var/log/ha-log //日志文件
auto_failback on //失败自动退回
node node1.a.org //节点对应的主机名,这里面要写所有的
node node2.a.org
#vim authkeys
auth 2
2 sha1 jlasdlfladddd //这个后面的密码可以随意写,也可以使用自动生成随机数(#dd if=/dev/urandom bs=512 count=1 |md5sum )的方式来生成,但是节点之间是一样的
#chmod 400 authkeys //修改权限
#vim haresources
node1.a.org 192.168.1.254/24eth0/192.168.1.255 httpd //生成一个VIP
#cd /usr/lib/heabeat
./ha_propagate //拷贝文件authkeys和ha.cf文件
三、配置Node2:
1.配置网卡的地址,强烈建议使用静态地址
2.#vim /etc/hosts对所有的节点主机的心跳IP和主机名都写入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.编辑主机名
#vim /etc/sysconfig/network
HOSTNAME=node2.a.org
#hostname node2.a.org
#yum install httpd
#echo "<h1>node2server</h1>" >/var/www/html/index.html
任何集群服务都不能自动启动,而且还不能开机自动启动
#server httpd stop
#chkconfig httpd off
#cd /usr/share/doc/heartbeat-2.1.4/
#cp ha.cf haresources authkeys /etc/ha.d/
#cd /etc/ha.d/
#vim /etc/ha.d/ha.cf
修改如下内容
keepalive 2 //保持时间
deadtime 30 //死亡时间
warntime 10 //警告时间
initdead 120 //启动时间
udpport 694 //使用udp的端口
bcast eth1 //心跳接口
logfile /var/log/ha-log //日志文件
auto_failback on //失败自动退回
node node1.a.org //节点对应的主机名,这里面要写所有的
node node2.a.org
#vim authkeys
auth 2
2 sha1 jlasdlfladddd //这个后面的密码可以随意写,也可以使用自动生成随机数(#dd if=/dev/urandom bs=512 count=1 |md5sum )的方式来生成,但是节点之间是一样的
#chmod 400 authkeys //修改权限
#vim haresources
node1.a.org 192.168.1.254/24eth0/192.168.1.255 httpd //生成一个VIP
#cd /usr/lib/heabeat
./ha_propagate //拷贝文件authkeys和ha.cf文件
三、配置Node2:
1.配置网卡的地址,强烈建议使用静态地址
2.#vim /etc/hosts对所有的节点主机的心跳IP和主机名都写入
10.1.1.1 node1.a.org node1
10.1.1.2 node2.a.org node2
3.编辑主机名
#vim /etc/sysconfig/network
HOSTNAME=node2.a.org
#hostname node2.a.org
#yum install httpd
#echo "<h1>node2server</h1>" >/var/www/html/index.html
任何集群服务都不能自动启动,而且还不能开机自动启动
#server httpd stop
#chkconfig httpd off
四、安装heartbeat软件包并拷贝配置文件
#yum localinstall * -y --nogpgcheck //和Node1 一样的安装
#yum localinstall * -y --nogpgcheck //和Node1 一样的安装
#cd /usr/lib/heatbeat
#./ha_propagate //拷贝文件authkeys和ha.cf文件
#cd /etc/ha.d/
#scp haresources node2:/etc/ha.d/
五、启动服务
#/etc/init.d/heartbeat start
#ssh node2 --'/etc/init.d/heartbeat start' //无论哪个先启动,但是所有集群的节点必须在同一个上面启动其他节点
六、测试:
在浏览器中输入http://192.168.1.254进行访问
测试的时候,在Node2上停止Node1的服务
#ssh node1 --'/etc/init.d/heartbeat stop'
在主节点上执行/usr/lig/heartbeat/hb_standy 让出主节点
/usr/lig/heartbeat/hb_takeover 主节点把资源抢回来
实验结束!
#./ha_propagate //拷贝文件authkeys和ha.cf文件
#cd /etc/ha.d/
#scp haresources node2:/etc/ha.d/
五、启动服务
#/etc/init.d/heartbeat start
#ssh node2 --'/etc/init.d/heartbeat start' //无论哪个先启动,但是所有集群的节点必须在同一个上面启动其他节点
六、测试:
在浏览器中输入http://192.168.1.254进行访问
测试的时候,在Node2上停止Node1的服务
#ssh node1 --'/etc/init.d/heartbeat stop'
在主节点上执行/usr/lig/heartbeat/hb_standy 让出主节点
/usr/lig/heartbeat/hb_takeover 主节点把资源抢回来
实验结束!