




一. JVM內存區域的劃分
1.1 java虛擬機運行時數據區
java虛擬機運行時數據區分佈圖:
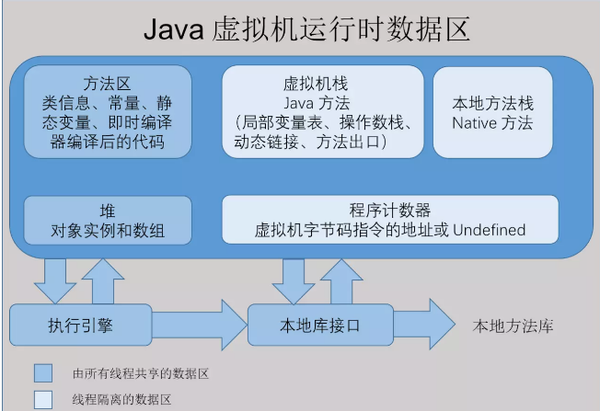
JVM棧(Java Virtual Machine Stacks): Java中一個線程就會相應有一個線程棧與之對應,因爲不同的線程執行邏輯有所不同,因此需要一個獨立的線程棧,因此棧存儲的信息都是跟當前線程(或程序)相關信息的,包括局部變量、程序運行狀態、方法返回值、方法出口等等。每一個方法被調用直至執行完成的過程,就對應着一個棧幀在虛擬機棧中從入棧到出棧的過程。
堆(Heap): 堆是所有線程共享的,主要是存放對象實例和數組。處於物理上不連續的內存空間,只要邏輯連續即可
方法區(Method Area): 屬於共享內存區域,存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯後的代碼等數據
常量池(Runtime Constant Pool): 它是方法區的一部分,用於存放編譯期生成的各種字面量和符號引用。
本地方法棧(Native Method Stacks)
其中,堆(Heap)和JVM棧是程序運行的關鍵,因爲:
棧是運行時的單位(解決程序的運行問題,即程序如何執行,或者說如何處理數據),而堆是存儲的單位(解決的是數據存儲的問題,即數據怎麼放、放在哪兒)。
堆存儲的是對象。棧存儲的是基本數據類型和堆中對象的引用;(參數傳遞的值傳遞和引用傳遞)
那爲什麼要把堆和棧區分出來呢?棧中不是也可以存儲數據嗎?
從軟件設計的角度看,棧代表了處理邏輯,而堆代表了數據,分工明確,處理邏輯更爲清晰體現了“分而治之”以及“隔離”的思想。
堆與棧的分離,使得堆中的內容可以被多個棧共享(也可以理解爲多個線程訪問同一個對象)。這樣共享的方式有很多收益:提供了一種有效的數據交互方式(如:共享內存);堆中的共享常量和緩存可以被所有棧訪問,節省了空間。
棧因爲運行時的需要,比如保存系統運行的上下文,需要進行地址段的劃分。由於棧只能向上增長,因此就會限制住棧存儲內容的能力。而堆不同,堆中的對象是可以根據需要動態增長的,因此棧和堆的拆分,使得動態增長成爲可能,相應棧中只需記錄堆中的一個地址即可。
堆和棧的結合完美體現了面向對象的設計。當我們將對象拆開,你會發現,對象的屬性即是數據,存放在堆中;而對象的行爲(方法)即是運行邏輯,放在棧中。因此編寫對象的時候,其實即編寫了數據結構,也編寫的處理數據的邏輯。
1.2 堆(Heap)和JVM棧
1.2.1 堆(Heap)
Java堆是java虛擬機所管理內存中最大的一塊內存空間,處於物理上不連續的內存空間,只要邏輯連續即可,主要用於存放各種類的實例對象。該區域被所有線程共享,在虛擬機啓動時創建,用來存放對象的實例,幾乎所有的對象以及數組都在這裏分配內存(棧上分配、標量替換優化技術的例外)。 在 Java 中,堆被劃分成兩個不同的區域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被劃分爲三個區域:Eden、From Survivor(S0)、To Survivor(S1)。如圖所示: 堆的內存佈局:
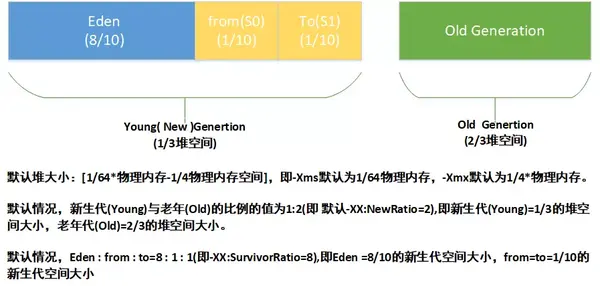
這樣劃分的目的是爲了使jvm能夠更好的管理內存中的對象,包括內存的分配以及回收。 而新生代按eden和兩個survivor的分法,是爲了
有效空間增大,eden+1個survivor;
有利於對象代的計算,當一個對象在S0/S1中達到設置的XX:MaxTenuringThreshold值後,會將其挪到老年代中,即只需掃描其中一個survivor。如果沒有S0/S1,直接分成兩個區,該如何計算對象經過了多少次GC還沒被釋放。
兩個Survivor區可解決內存碎片化
1.2.2 堆棧相關的參數

Note: 每次GC 後會調整堆的大小,爲了防止動態調整帶來的性能損耗,一般設置-Xms、-Xmx 相等。
新生代的三個設置參數:-Xmn,-XX:NewSize,-XX:NewRatio的優先級: 最高優先級: -XX:NewSize=1024m和-XX:MaxNewSize=1024m 次高優先級: -Xmn1024m (-XX:NewSize==XX:MaxNewSize==1024m) 最低優先級:-XX:NewRatio=2 推薦使用的是-Xmn參數,原因是這個參數很簡潔,相當於一次性設定NewSize和MaxNewSIze,而且兩者相等。
1.3 jvm對象
1.3.1 創建對象的方式
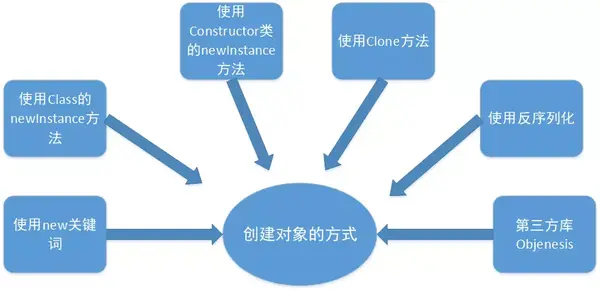
各個方式的實質操作如下:

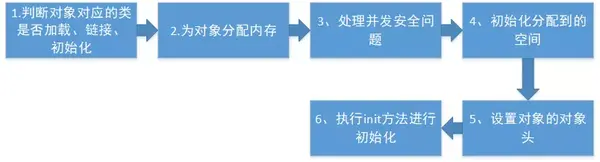
1.3.2 jvm對象分配
在虛擬機層面上創建對象的步驟:

1.3.3 對象分配內存方式
分配對象內存,有兩種分配方式,指針碰撞和空閒列表: (1)如果內存是規整的,那麼虛擬機將採用的是指針碰撞法(Bump The Pointer)來爲對象分配內存。意思是所有用過的內存在一邊,空閒的內存在另外一邊,中間放着一個指針作爲分界點的指示器,分配內存就僅僅是把指針向空閒那邊挪動一段與對象大小相等的距離罷了。 如果垃圾收集器選擇的是Serial、ParNew這種基於壓縮算法的,虛擬機採用這種分配方式。 一般使用帶有compact(整理)過程的收集器時,使用指針碰撞。 (2)如果內存不是規整的,已使用的內存和未使用的內存相互交錯,那麼虛擬機將採用的是空閒列表法來爲對象分配內存。意思是虛擬機維護了一個列表,記錄上哪些內存塊是可用的,再分配的時候從列表中找到一塊足夠大的空間劃分給對象實例,並更新列表上的內容。這種分配方式成爲“空閒列表(Free List)”。 Note: 選擇哪種分配方式由Java堆是否規整決定,而Java堆是否規整又由所採用的垃圾收集器是否帶有壓縮整理功能決定。
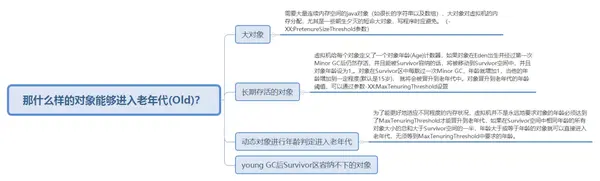
1.3.4 那什麼樣的對象能夠進入老年代(Old)
那什麼樣的對象能夠進入老年代(Old)?
1.4 內存分配與回收策略

二. 垃圾回收算法分類 2.1 引用

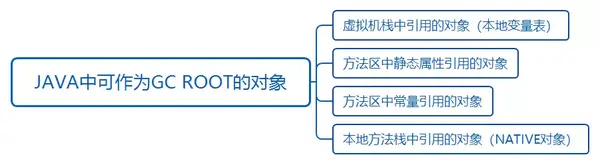
2.2 GC Root的對象
2.3 標記-清除(Mark—Sweep)
被譽爲現代垃圾回收算法的思想基礎。
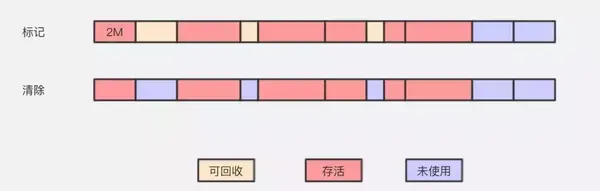
標記-清除算法採用從根集合進行掃描,對存活的對象對象標記,標記完畢後,再掃描整個空間中未被標記的對象,進行回收,如上圖所示。標記-清除算法不需要進行對象的移動,並且僅對不存活的對象進行處理,在存活對象比較多的情況下極爲高效,但由於標記-清除算法直接回收不存活的對象,因此會造成內存碎片。
2.4 複製算法(Copying)
該算法的提出是爲了克服句柄的開銷和解決堆碎片的垃圾回收。建立在存活對象少,垃圾對象多的前提下。此算法每次只處理正在使用中的對象,因此複製成本比較小,同時複製過去後還能進行相應的內存整理,不會出現碎片問題。但缺點也是很明顯,就是需要兩倍內存空間。
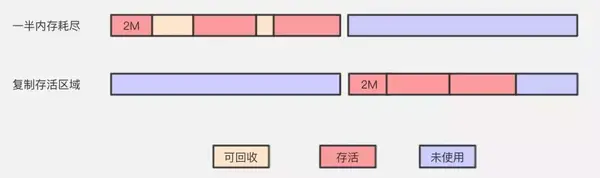
它開始時把堆分成 一個對象 面和多個空閒面, 程序從對象面爲對象分配空間,當對象滿了,基於copying算法的垃圾 收集就從根集中掃描活動對象,並將每個活動對象複製到空閒面(使得活動對象所佔的內存之間沒有空閒洞),這樣空閒面變成了對象面,原來的對象面變成了空閒面,程序會在新的對象面中分配內存。一種典型的基於coping算法的垃圾回收是stop-and-copy算法,它將堆分成對象面和空閒區域面,在對象面與空閒區域面的切換過程中,程序暫停執行
2.5 標記-整理(或標記-壓縮算法,Mark-Compact,又或者叫標記清除壓縮MarkSweepCompact)
此算法是結合了“標記-清除”和“複製算法”兩個算法的優點。避免了“標記-清除”的碎片問題,同時也避免了“複製”算法的空間問題。
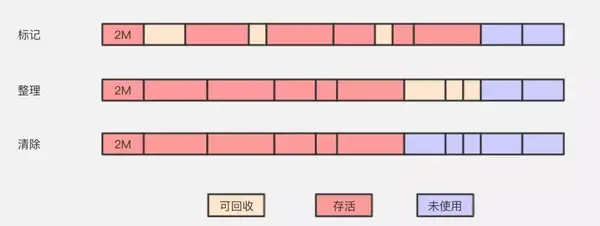
標記-整理算法採用標記-清除算法一樣的方式進行對象的標記,但在清除時不同,在回收不存活的對象佔用的空間後,會將所有的存活對象往左端空閒空間移動,並更新對應的指針。標記-整理算法是在標記-清除算法的基礎上,又進行了對象的移動,因此成本更高,但是卻解決了內存碎片的問題。在基於Compacting算法的收集器的實現中,一般增加句柄和句柄表。
2.6 分代回收策略(Generational Collecting)
基於這樣的事實:不同的對象的生命週期是不一樣的。因此,不同生命週期的對象可以採取不同的回收算法,以便提高回收效率。 新生代由於其對象存活時間短,且需要經常gc,因此採用效率較高的複製算法,其將內存區分爲一個eden區和兩個suvivor區,默認eden區和survivor區的比例是8:1,分配內存時先分配eden區,當eden區滿時,使用複製算法進行gc,將存活對象複製到一個survivor區,當一個survivor區滿時,將其存活對象複製到另一個區中,當對象存活時間大於某一閾值時,將其放入老年代。老年代和永久代因爲其存活對象時間長,因此使用標記清除或標記整理算法 總結:
新生代:複製算法(新生代回收的頻率很高,每次回收的耗時很短,爲了支持高頻率的新生代回收,虛擬機可能使用一種叫做卡表(Card Table)的數據結構,卡表爲一個比特位集合,每個比特位可以用來表示老年代的某一區域中的所有對象是否持有新生代對,
2.7 垃圾回收器
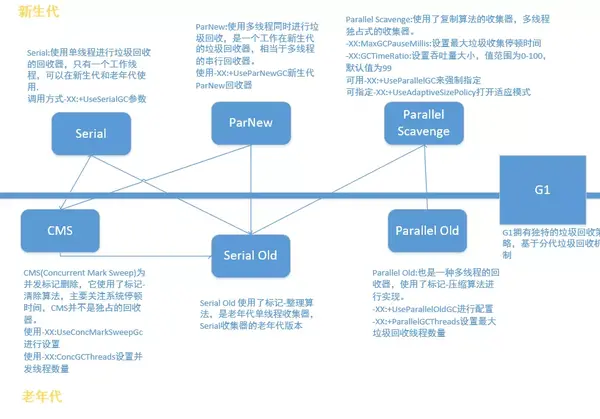
垃圾回收器的任務是識別和回收垃圾對象進行內存清理,不同代可使用不同的收集器:
新生代收集器使用的收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器使用的收集器:Serial Old(MSC)、Parallel Old、CMS。
總結:
Serial old和新生代的所有回收器都能搭配;也可以作爲CMS回收器的備用回收器;
CMS只能和新生代的Serial和ParNew搭配,而且ParNew是CMS默認的新生代回收器;
並行(Parallel):指多條垃圾收集線程並行工作,但此時用戶線程仍然處於等待狀態
併發(Concurrent):指用戶線程和垃圾收集線程同時執行(但不一定是並行的,可能是交替執行),用戶程序繼續運行,而垃圾收集程序運行在另外的CPU上。
三. GC的執行機制
Java 中的堆(deap) 也是 GC 收集垃圾的主要區域。 由於對象進行了分代處理,因此垃圾回收區域、時間也不一樣。GC有兩種類型:Scavenge GC(Minor GC)和Full GC(Major GC)。
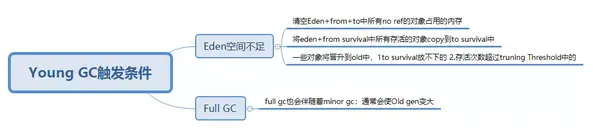
Scavenge GC(Minor GC): 一般情況下,當新對象生成(age=0),並且在Eden申請空間失敗時,就會觸發Scavenge GC,對Eden區域進行GC,清除非存活對象,並且把尚且存活的對象移動到Survivor區(age+1)。然後整理(其實是複製過去就順便整理了)Survivor的兩個區。這種方式的GC是對年輕代的Eden區進行,不會影響到年老代。因爲大部分對象都是從Eden區開始的,同時Eden區不會分配的很大,所以Eden區的GC會頻繁進行。因而,一般在這裏需要使用速度快、效率高的算法(即複製-清理算法),使Eden去能儘快空閒出來。Java 中的大部分對象通常不需長久存活,具有朝生夕滅的性質。
Full GC: 對整個堆進行整理,包括Young、Tenured和Perm。Full GC因爲需要對整個對進行回收,所以比Scavenge GC要慢,因此應該儘可能減少Full GC的次數。在對JVM調優的過程中,很大一部分工作就是對於FullGC的調節。
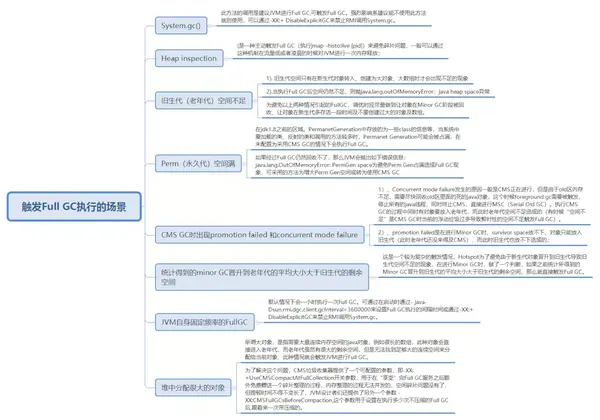
3.1 觸發Full GC執行的場景
3.2 Young GC觸發條件
3.3 新生對象GC收回流程
基於大多數新生對象都會在GC中被收回的假設。新生代的GC 使用複製算法,(將年輕代分爲3部分,主要是爲了生命週期短的對象儘量留在年輕代。老年代主要存放生命週期比較長的對象,比如緩存)。可能經歷過程:
對象創建時,一般在Eden區完成內存分配(有特殊);
當Eden區滿了,再創建對象,會因爲申請不到空間,觸發minorGC,進行young(eden+1survivor)區的垃圾回收;
minorGC時,Eden和survivor A不能被GC回收且年齡沒有達到閾值(tenuring threshold)的對象,會被放入survivor B,始終保證一個survivor是空的;
當做第3步的時候,如果發現survivor滿了,將這些對象copy到old區(分配擔保機制);或者survivor並沒有滿,但是有些對象已經足夠Old,也被放入Old區 XX:MaxTenuringThreshold;(回顧下對象進入老年代的情況)
直接清空eden和survivor A;
當Old區被放滿的之後,進行fullGC。
3.4 GC日誌
GC日誌相關參數:
-XX:+PrintGC:輸出GC日誌
-XX:+PrintGCDetails:輸出GC的詳細日誌
-XX:+PrintGCTimeStamps:輸出GC的時間戳(以基準時間的形式)
-XX:+PrintGCApplicationStoppedTime:打印垃圾回收期間程序暫停的時間
-XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中斷的執行時間
-XX:+PrintHeapAtGC:在進行GC的前後打印出堆的信息
-XX:+PrintTLAB:查看TLAB空間的使用情況
-XX:PrintTenuingDistribution:查看每次minor GC後新的存活週期的閾值
-XX:PrintReferenceFC:用來跟蹤系統內的(softReference)軟引用,(weadReference)弱引用,(phantomReference)虛引用,顯示引用過程
案例分析:
XX:+PrintGCApplicationStoppedTime
XX:+PrintGCApplicationConcurrentTime
一起使用
Application time: 0.3440086 seconds Total time for which application threads were stopped: 0.0620105 seconds Application time: 0.2100691 seconds Total time for which application threads were stopped: 0.0890223 seconds
得知應用程序在前344毫秒中是在處理實際工作的,然後將所有線程暫停了62毫秒,緊接着又工作了210ms,然後又暫停了89ms。
2796146K->2049K(1784832K)] 4171400K->2049K(3171840K), [Metaspace: 3134K->3134K(1056768K)], 0.0571841 secs] [Times: user=0.02 sys=0.04, real=0.06 secs] Total time for which application threads were stopped: 0.0572646 seconds, Stopping threads took: 0.0000088 seconds
應用線程被強制暫停了57ms來進行垃圾回收。其中又有8ms是用來等待所有的應用線程都到達安全點。 只要設置-XX:+PrintGCDetails 就會自動帶上-verbose:gc和-XX:+PrintGC
33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K->152K(11904K), 0.0031680 secs] 100.667: [Full GC [Tenured: 0K->210K(10240K), 0.0149142 secs] 4603K->210K(19456K), [Perm : 2999K->2999K(21248K)], 0.0150007 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
最前面的數字“33.125:”和“100.667:”代表了GC發生的時間,這個數字的含義是從Java虛擬機啓動以來經過的秒數。
GC日誌開頭的“[GC”和“[Full GC”說明了這次垃圾收集的停頓類型,而不是用來區分新生代GC還是老年代GC的。如果有“Full”,說明這次GC是發生了Stop-The-World的。
接下來的“[DefNew”、“[Tenured”、“[Perm”表示GC發生的區域,這裏顯示的區域名稱與使用的GC收集器是密切相關的,例如上面樣例所使用的Serial收集器中的新生代名爲“Default New Generation”,所以顯示的是“[DefNew”。如果是ParNew收集器,新生代名稱就會變爲“[ParNew”,意爲“Parallel New Generation”。如果採用Parallel Scavenge收集器,那它配套的新生代稱爲“PSYoungGen”,老年代和永久代同理,名稱也是由收集器決定的。
後面方括號內部的“3324K->152K(3712K)”含義是“GC前該內存區域已使用容量-> GC後該內存區域已使用容量 (該內存區域總容量)”。而在方括號之外的“3324K->152K(11904K)”表示“GC前Java堆已使用容量 -> GC後Java堆已使用容量 (Java堆總容量)”。
再往後,“0.0025925 secs”表示該內存區域GC所佔用的時間,單位是秒。有的收集器會給出更具體的時間數據
[Full GC 283.736: [ParNew: 261599K->261599K(261952K), 0.0000288 secs] 新生代收集器ParNew的日誌也會出現“[Full GC”(這一般是因爲出現了分配擔保失敗之類的問題,所以才導致STW)。如果是調用System.gc()方法所觸發的收集,那麼在這裏將顯示“[Full GC (System)”。
3.5 減少GC開銷的措施
從代碼上:

從JVM參數上調優上:

3.6 內存溢出分類
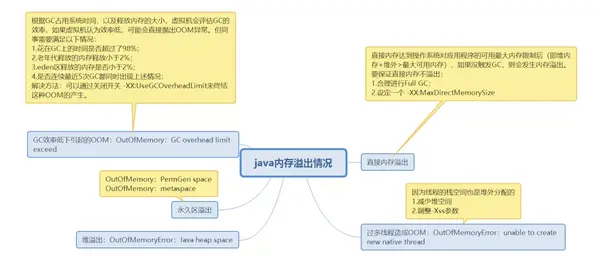
四. 總結-JVM調優相關
4.1 調優目的

4.2 JVM性能調優所處的層次
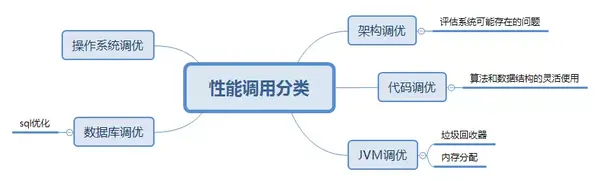
4.3 JVM調優流程

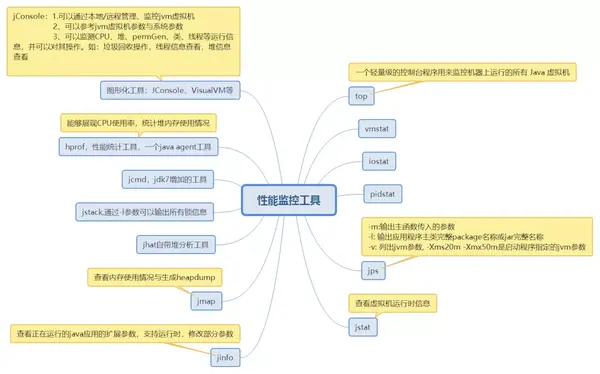
4.4 性能監控工具
調優的最終目的都是爲了令應用程序使用最小的硬件消耗來承載更大的吞吐。jvm的調優也不例外,jvm調優主要是針對垃圾收集器的收集性能優化,令運行在虛擬機上的應用能夠使用更少的內存以及延遲獲取更大的吞吐量。