




RDS for SQL Server使用過程中,會遇到CPU使用率過高甚至達到100%的情況。本文將介紹造成該狀況的常見原因以及解決方法。
常見原因
RDS for SQL Server CPU使用率高的因素有很多,其中最常見的是應用的負載高、查詢語句的成本高,或者是實例的並行度設置不合理。
實例的並行度設置不合理
問題排查
多線程並行處理任務時,由於每個線程處理的數據量不一致,會出現CXPACKET等待情況,CXPACKET等待發生比較多的話,造成CPU使用率高。可以通過SQL Server Management Studio的活動監視器或者下面語句(多次執行取差值),監控是否存在大量CXPACKET等待。
說明 CXPACKET指線程正在等待彼此完成並行處理。當SQL Server發現一條指令複雜時,會決定用多個線程並行來執行,由於某些並行線程已完成工作,在等待其它並行線程來同步,這種等待就叫CXPACKET。
WITH [Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
-- Maybe uncomment these four if you have mirroring issues
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
-- Maybe uncomment these six if you have AG issues
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'MEMORY_ALLOCATION_EXT',
N'ONDEMAND_TASK_QUEUE',
N'PREEMPTIVE_XE_GETTARGETSTATE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_RECOVERY',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX( [W1].[Percentage] ) < 95; -- percentage threshold
GO
解決方案
- 從語句級別進行設置
- 通過查詢語句尋找消耗CPU的語句,SQL如下:
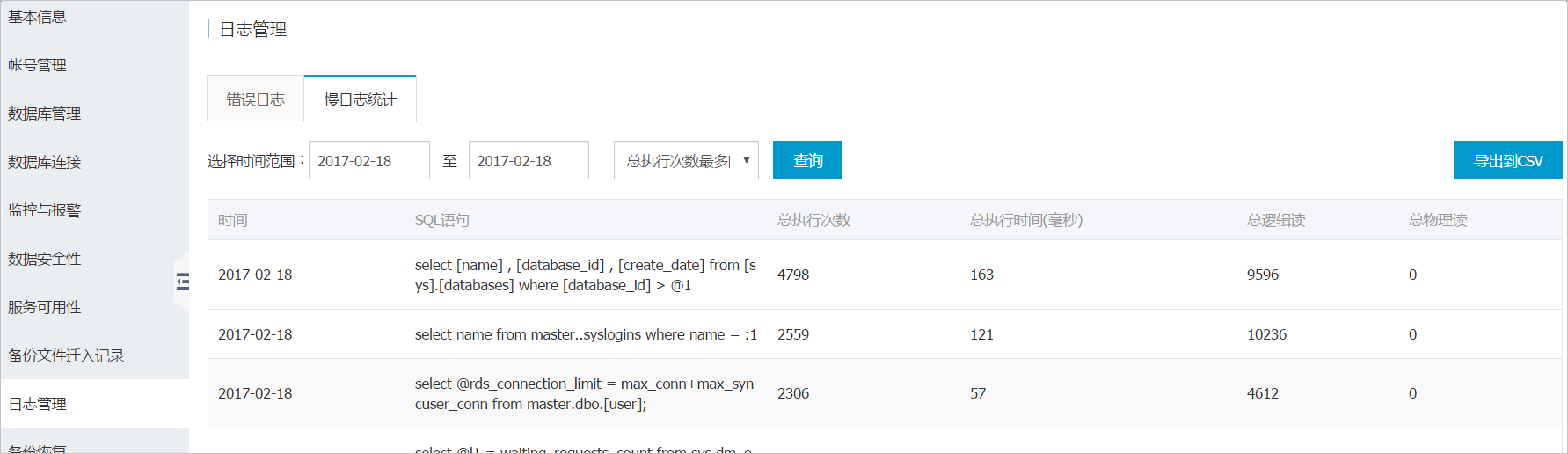
SELECT TOP 50 [Avg. MultiCore/CPU time(sec)] = qs.total_worker_time / 1000000 / qs.execution_count, [Total MultiCore/CPU time(sec)] = qs.total_worker_time / 1000000, [Avg. Elapsed Time(sec)] = qs.total_elapsed_time / 1000000 / qs.execution_count, [Total Elapsed Time(sec)] = qs.total_elapsed_time / 1000000, qs.execution_count, [Avg. I/O] = (total_logical_reads + total_logical_writes) / qs.execution_count, [Total I/O] = total_logical_reads + total_logical_writes, Query = SUBSTRING(qt.[text], (qs.statement_start_offset / 2) + 1, ( ( CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.[text]) ELSE qs.statement_end_offset END - qs.statement_start_offset ) / 2 ) + 1 ), Batch = qt.[text], [DB] = DB_NAME(qt.[dbid]), qs.last_execution_time, qp.query_plan FROM sys.dm_exec_query_stats AS qs CROSS APPLY sys.dm_exec_sql_text(qs.[sql_handle]) AS qt CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp where qs.execution_count > 5 --more than 5 occurences ORDER BY [Total MultiCore/CPU time(sec)] DESC - 對於RDS for SQL Server 2008 R2實例,可以在控制檯查看慢日誌統計,查找消耗CPU的語句。
![控制檯慢日誌統計]()
- 找到語句之後,查看其執行計劃,對於並行度較高的語句,可以在語句級別使用hint查詢,限制語句並行度。示例如下:
SELECT column1,column2 FROM table1 o INNER JOIN table2 d ON (o.d_id = d.d_id) OPTION (maxdop 1)
- 通過查詢語句尋找消耗CPU的語句,SQL如下:
- 從實例級別進行設置
- 查看當前實例的MAXDOP值,SQL如下:
select * from sys.configurations where name like '%max%'![查詢maxdop]()
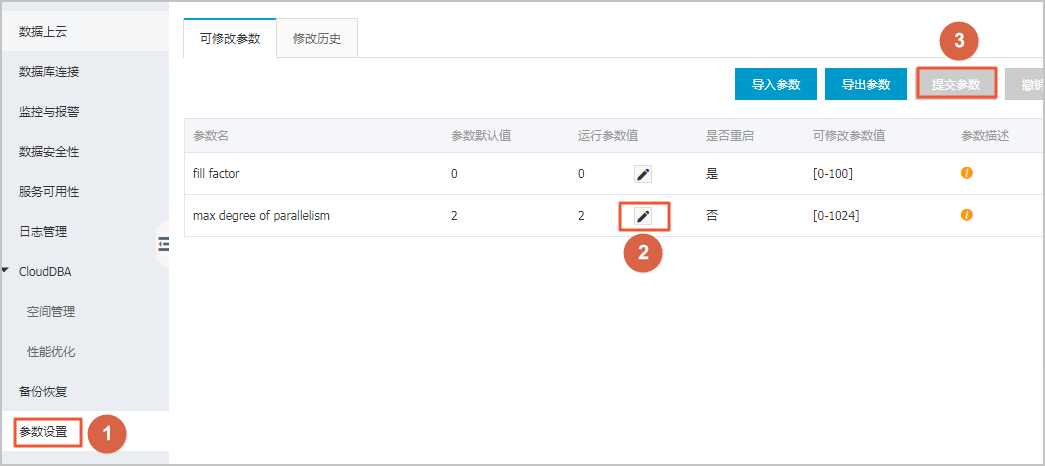
- 在實例級別設置該參數,對所有查詢均生效,SQL如下:
sp_rds_configure 'max degree of parallelism', 1; GO對於RDS for SQL Server 2008 R2實例,可以在RDS管理控制檯的參數設置中進行手動設置,需提交參數生效。
![修改maxdop]()
- 查看當前實例的MAXDOP值,SQL如下:

應用負載高
現象
沒有出現慢查詢(或者慢查詢不是問題主要原因),QPS和CPU使用率曲線變化吻合。常見於應用優化過的在線事務交易系統(比如訂單系統)、高讀取率的熱門Web網站應用等。
特徵
實例的QPS高,查詢比較簡單、執行效率高、優化餘地小。
解決方案
建議從應用架構、實例規格等方面來解決:
- 升級實例規格,增加CPU資源。
- 儘量優化查詢,減少查詢的執行成本(邏輯IO,執行需要訪問的表數據行數),提高應用可擴展性。
查詢語句的讀寫過高
現象
存在慢查詢,QPS和CPU使用率曲線變化不吻合,檢查消耗CPU的語句,存在I/O較大的語句。
特徵
實例的QPS不高;查詢執行效率低、執行需要掃描大量表中數據、優化餘地大。
解決方案
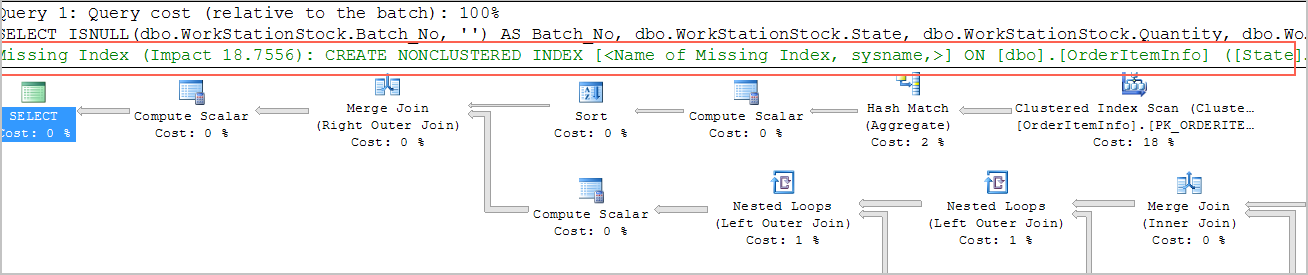
- 對於大表查詢,檢查是否有合適的索引。檢查實際執行計劃,針對全表掃描操作進行優化,執行計劃中也會給出缺失索引的建議。
![缺失索引檢查]()
- 通過CloudDBA檢查性能問題。
避免出現CPU使用100%的一般原則
- 設置CPU使用率告警,實例CPU使用率保證一定的冗餘度。
- 應用設計和開發過程中,要考慮查詢的優化,遵守SQL優化的一般優化原則,降低查詢的邏輯 I/O,提高應用可擴展性。
- 新功能、新模塊上線前,要使用生產環境數據進行壓力測試。
- 經常使用CloudDBA查看實例各項性能,及時發現問題。