




1、查詢語句是如何執行的?
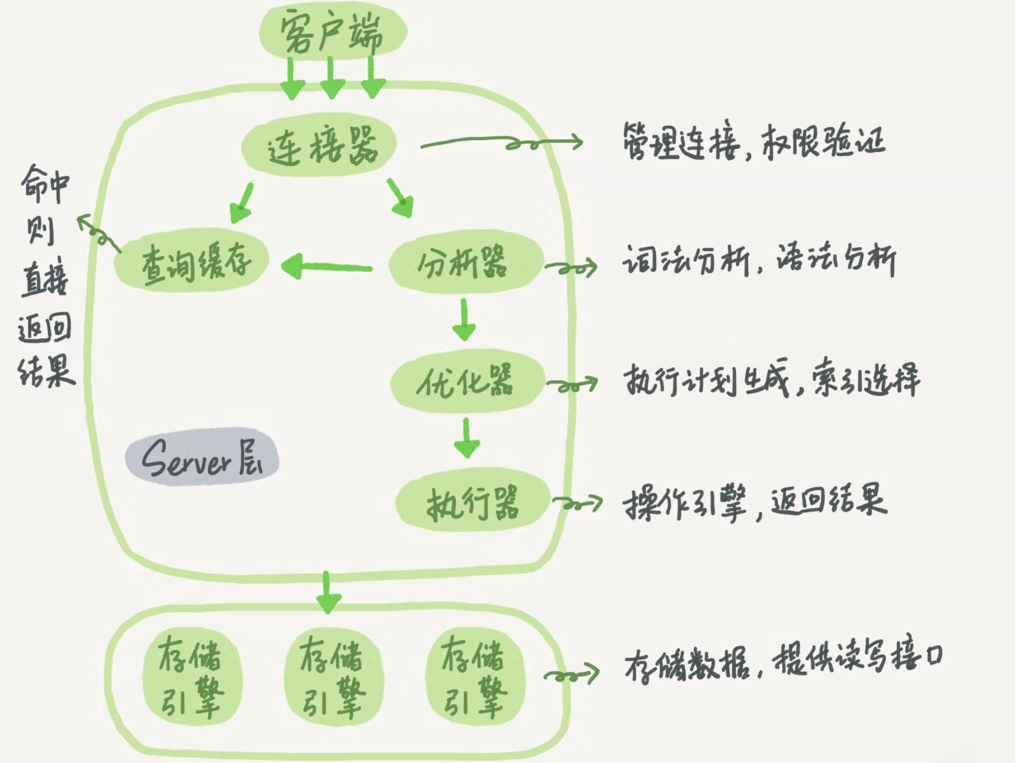
1、連接
1、建立連接
2、驗證權限,修改了權限,創建新的連接纔會生效。
3、SQL執行的臨時內存
2、查詢緩存
1、先查詢緩存,更新操作會導致所有緩存失效。
2、MySQL 8.0功能去掉
3、分析
詞法解析,語法解析
4、優化
1、決定使用哪個索引,比方說根據統計信息預估掃描行數,是否使用臨時表,需不需要排序等。
2、決定join的各個表的連接順序
5、執行
1、調用引擎接口,查找到第一條符合條件的數據,然後依次查詢,返回結果。
更新是如何執行的?
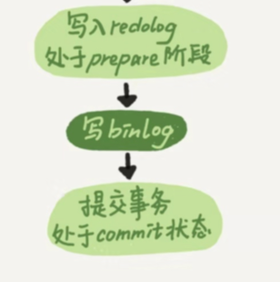
1、日誌先行,redo log 和 undo log
2、binlog
3、兩階段提交
事務隔離&多版本控制
1、4種隔離級別
2、可重複讀的實現原理,一致性視圖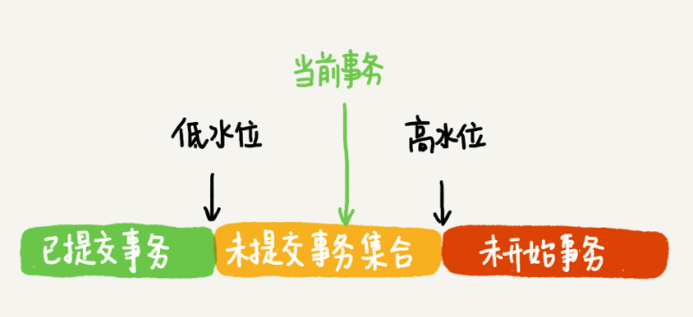
3、例子
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into t(id,k) values (1,1),(2,2);
注意:不帶索引的更新,會升級爲表鎖!
CREATE TABLE `t1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`ext` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `city` (`city`,`name`,`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=9001 DEFAULT CHARSET=utf8 事務1,更新了一條數據,where不帶索引。
START TRANSACTION with CONSISTENT SNAPSHOT;
update t1 set name = 'test2' where ext = 'test';事務2,普通查詢可以,for update查詢被阻塞。
select * from t1 where id=4002;
select city,name,age from t1 where id=4002 for update;4、讀提交和RR的區別
索引結構
1、B+樹
2、主鍵索引和普通索引的區別
排序原理
1、全字段排序(sort_buffer,參數:sort_buffer_size)
2、rowid排序(參數:max_length_for_sort_data)
3、例子:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
select city,name,age from t1 where city='北京' order by name limit 1000;
表中有4000條北京的數據,1000條上海的數據。

1、Using filesort表示會使用排序。
2、通過以下語句查看是否使用了文件排序,文件排序一般是歸併排序。
SELECT * FROM information_schema.OPTIMIZER_TRACE;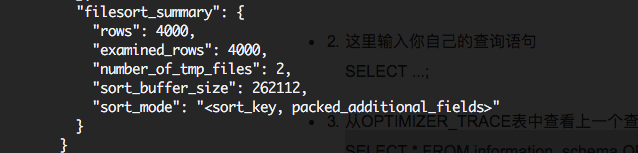
number_of_tmp_files,代表了使用了幾個臨時文件。
3、轉rowid排序
set max_length_for_sort_data = 16;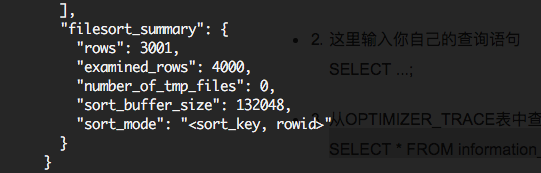
使用rowid了排序,這個時候沒有使用文件排序,使用臨時文件個數爲0;
4、增加覆蓋索引,就不會再排序了,因爲索引默認是有順序的。