




MySQL高可用集羣方案之PXC
1. 前言
在之前的公衆號文章《 在遊戲運維實戰中摸索前行的“異地雙活”架構 》中,我們向大家介紹了我們遊戲中對“異地雙活”架構的實踐歷程。
其中爲了實現DB層的多點寫入及數據強一致性,我們結合實際的業務場景測試對比了Percona Xtradb Cluster和MySQL Cluster。
我們選擇最新版的sysbench 0.5版本來測試數據庫性能。南北機器分別併發20、60、100個進程進行壓測。以下是壓測對比的結果:
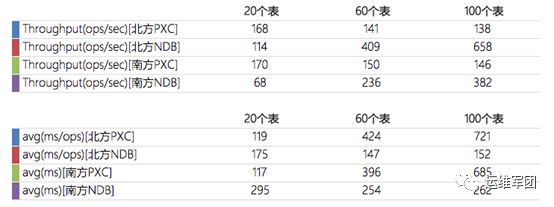
從測試結果上看,大數量和大併發的場景下,MySQL Cluster集羣的整體性能都越優於Percona Xtradb Cluster集羣。這需要得益於MySQL Cluster基於內存的引擎NDB。但NDB引擎耗內存、易崩潰、運維成本巨大。而反觀Percona Xtradb Cluster,節點與傳統MySQL實例基本無異,日常運維也是差不多的。在性能方面我們可以藉助SSD+RAID10提高IO性能,異地機房藉助專線以降低網絡抖動。基於實際場景,我們允許集羣本身有一定的性能犧牲,然後藉助底層硬件的提升來彌補,最終我們採用了Percona Xtradb Cluster。
今天,筆者向大傢俱體介紹Percona Xtradb Cluster,以及我們的經驗總結。
2. 集羣介紹
PerconaXtradb Cluster是一種完全開源的MySQL高可用解決方案,它將Percona Server、Percona XtraBackup與Galera庫集成在一起,以實現同步多主複製的MySQL集羣。

- Multi-master的架構,數據多點寫入並自動同步到集羣。
- 本地執行查詢,所有節點都具備完整的數據副本,查詢涉及本地數據。
- 基於驗證的複製機制,數據寫入需要集羣所有節點驗證通過了纔會提交,保證了數據的強一致性。
- 去中心化架構,集羣節點可自由伸縮,脫離集羣的節點可以將其轉爲普通MySQL實例的角色提供服務。
PerconaXtradb Cluster作爲一種出色的MySQL高可用解決方案,滿足了現有業務架構的需求,但其劣勢也是很明顯,在使用前一定要摸清其短板。Percona Xtradb Cluster主要有以下限制:
- 集羣的複製只支持 InnoDB 引擎。
- 集羣吞吐量取決了性能最差的節點。
- 不支持InnoDB fake changes和XA事務。
- 不允許大事務,事務提交的最大行數及大小受制於變量: wsrep_max_ws_rows 和wsrep_max_ws_size variables。
- 不支持鎖表:LOCK TABLES、UNLOCK TABLES,不支持鎖表函數: GET_LOCK()、RELEASE_LOCK()
- 樂觀鎖併發控制,事務提交時仍可能在該階段被中止。
3. 基礎概念
除了摸清短板,要想玩好Percona Xtradb Cluster,還需要對集羣的基礎概念有一定的瞭解纔好辦。本節,筆者先給大家講講Percona Xtradb Cluster的一些重要基礎概念。
3.1 常見術語
- IST:數據增量同步,節點加入集羣的數據同步方式
- SST:數據全量同步,節點加入集羣的數據同步方式
- write-sets:事務寫集
- Donor節點:新節點加入集羣時,集羣會投票選出Donor節點提供新節點所需的數據
3.2 主要端口
- 3306:節點對外提供服務的端口
- 4567:節點間相互通信及複製的端口
- 4444: SST使用的端口,Joiner節點以SST方式加入集羣時啓用該端口接受數據(Donor節點會啓動隨機端口主動來連接4444端口)
- 4568: IST使用的端口,Joiner節點以IST方式加入集羣時啓用該端口接受數據(Donor節點會啓動隨機端口主動來連接4568端口)
3.3 grastate.dat
grastate.dat是節點狀態記錄文件,它一個非常重要的文件。節點故障恢復的第一步就是恢復這個文件,節點重新加入集羣第一個需要關注的也是這個文件。這個文件位於數據目錄下。該文件的內容如下:

- uuid:節點所屬集羣的uuid
- seqno:節點正常關閉時最後提交的事務編號,如果集羣非正常關閉或者正在運行狀態,seqno的值爲-1
- safe_to_bootstrap:集羣最後一個關閉的節點的值爲1,其它爲0
節點重新加入集羣時,會從grastat.dat中的seqno開始做IST。若這個文件不存在或者損壞了,那麼意味着節點將會以SST的方式加入集羣,這是我們最不願見到的。
3.4 GCache
GCache是一種環形緩衝區,主要由內存、內存映射文件和物理文件組成。在節點運行期間,GCache緩存着最新的寫集。Donor節點可以直接將GCache中最新增量數據給Joiner節點,實現Joiner節點快速加入集羣。
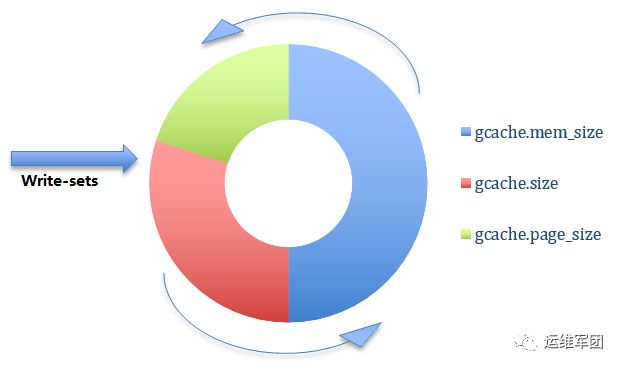
GCache的使用順序:優先使用內存,再使用映射文件,都用完了同時還是沒有PURGE出空間來,則使用物理文件。
GCache的大小決定了節點可以離開集羣多長時間重新以IST的方式加入集羣。
3.5 重要的狀態變量
- wsrep_local_state_comment:節點當前的狀態
- wsrep_cluster_status:集羣當前的狀態
- wsrep_local_cached_downto:當前節點gcache中緩存的最小事務編號
- wsrep_last_committed :當前節點已提交的事務編號
4.基本維護
4.1 新集羣的啓動方式
第一個節點先初始化,再以bootstrap方式啓動:
# 初始化 /usr/local/mysql/bin/mysqld --initialize --datadir=/data/database/mysql/ --basedir=/usr/local/mysql/ --user=mysql # 啓動 /usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf--wsrep-new-cluster &其他的節點無需初始化,直接按普通MySQL實例的方式啓動,會自動加入集羣。
4.2 集羣全部關機後如何啓動
原則:維護前最後關閉的節點,維護後以bootstrap的方式第一個啓動
/usr/local/mysql/bin/mysqld_safe –defaults-file=/etc/my.cnf –wsrep-new-cluster&
Q:怎麼知道哪個節點是最後關閉的?
A:從前面我們可以知道,grastate.dat文件中的safe_to_bootstrap字段,集
最後一個關閉的節點的值爲1,其它爲0。因此可以根據grastate.dat文件判斷。
4.3 節點重啓
節點不管以哪種方式離開集羣,需要以IST的方式重新加入集羣,都受到GCache大小的限制。在重新加入集羣時,都不可直接啓動節點,需要檢查grastate.dat文件和對比集羣中其他節點的“wsrep_local_cached_downto”狀態,已確定是否能IST加入,具體我們在後面細說。
4.4 節點備份
使用xtrabackup/innobackupex進行全庫備份時,加上–galera-info參數,備份會生成xtrabackup_galera_info文件。做故障恢復或者新節點加入時,可以直接利用這個文件重建grastate.dat。
xtrabackup_galera_info文件內容包含了集羣UUID和備份時節點最新提交的事務編號,如下:
bf26341f-43cb-11e8-a863-62c0eb4d9e79:529045
5.常見故障處理
PerconaXtradb Cluster集羣節點數推薦是3個節點,我們線上也採用3節點的部署方案。這裏筆者就以3節點的集羣作爲說明。
5.1 節點進入非主模式
PerconaXtradb Cluster爲了保證數據一致性,當某個節點脫離集羣,或者發生腦裂時,節點數小於50%的子集羣會進入非主模式拒絕對外提供服務。

如上圖所示,AB兩個節點故障宕機,集羣只剩C節點,而C節點與另外兩個節點失聯認爲自己脫離了集羣而進入非主模式,這時候C節運行正常,但不允許執行任何SQL,如下報錯:
ERROR 1047 (08S01): WSREP has not yet prepared node for applicationuse
這時候緊要急恢復業務,可以先讓C節點允許訪問,然後再恢復AB兩個節點。可以在C上執行:
SET GLOBAL wsrep_provider_options=‘pc.bootstrap=true’;
這樣就可以讓C節點對外提供正常的讀寫服務了。
5.2 節點互相失聯
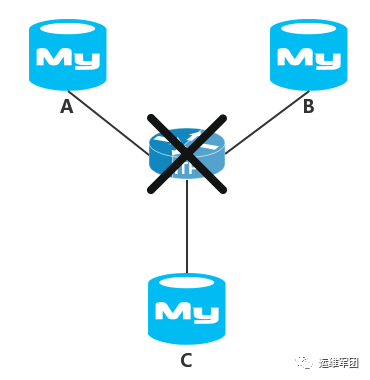
如上圖所示,因中間交換機的故障導致ABC三個節點相互失聯,所有節點都進入非主模式,所有節點正常運行卻都不可訪問。爲了緊急恢復業務,我們需要優先緊急恢復其中一個節點提供服務。但是這三個節點都正常運行,我們恢復哪個節點提供服務呢?從前面的介紹可以知道,節點的狀態變量wsrep_last_committed 表示當前節點已提交的事務編號,我們可以讓已提交事務最新的節點恢復服務:

5.3 節點宕機恢復思路
由於集羣每個節點都有相同的數據副本,我們並不擔心節點故障宕機會導致數據丟失。我們需要思考的是,節點故障宕機後如何正確恢復並重新加入集羣。
對於故障節點,我們可以用xtrabackup/innobackupex拉取數據做IST加入集羣,或者藉助備份,甚至任性點清空故障節點的數據目錄直接啓動做SST加入。不過,相信不管是運維還是DBA,都希望直接利用本地已有的數據做IST恢復吧。
本小節,我們先給出故障節點如何以IST的方式重新加入集羣的思路,後面做具體的實踐。思路如下:
- 恢復grastate.dat文件
- 確定能否以IST的方式加入集羣,既找到donor節點
- 不存在合適的donor(無法IST),先追binlog,再IST
5.4 恢復grastate.dat文件
從前面對grastate.dat文件的說明可以知道,節點重啓時需要從grastate.dat中讀取seqno做IST。因此,故障恢復的第一步就是恢復grastate.dat文件。
恢復具體步驟:
1、直接啓動服務,生成wsrep_recovery日誌。
這時候啓動會啓動失敗,因爲mysqld進程因爲找不到seqno而進行recovery,終端會打印如下內容:
mysqld_safe WSREP: Running position recovery with–log_error=‘/data/database/mysql/wsrep_recovery.5UKe8s’
2、藉助wsrep_recovery日誌,找到seqmo:
grep “Recovered” /data/database/mysql/wsrep_recovery.5UKe8s2018–04–03T08:18:54.534461Z 0 [Note] WSREP: Recovered position: bf26341f-43cb-11e8-a863-62c0eb4d9e79: 529045
3、重建grastate.dat文件:
# GALERA saved state version: 2.1uuid: bf26341f-43cb-11e8-a863-62c0eb4d9e79 seqno: 529045safe_to_bootstrap: 0
到現在,一個宕機節點的grastate.dat文件就恢復好了。目前這個節點的狀態如同一個正常關機的節點一樣。但這不代表啓動就一定會以IST的方式加入集羣。
5.5 確定Donor節點
從集羣中確定一個節點爲donor節點,目的就是爲了讓重新加入集羣的節點能從donor節點獲得增量數據,以IST的方式加入集羣。
1、查看集羣現有節點gcache中最小事務編號:


2、 哪個節點gcache緩存中最小事務編號小於新加入節點的seqno,說明該節點的gcache緩存有故障節點宕機期間產生的所有事務。由上面的兩個截圖可以看出30.0.0.226(pxc-node-0)可以確定爲donor節點。
3、指定donor節點啓動:
/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/mysql.cnf--wsrep_sst_donor=pxc-node-0 &到此,一個故障節點就恢復了,IST加入集羣這個過程會非常快。但如果故障節點停機過長,或者數據量過大導致gcache不足以緩存停機期間的write-sets,那麼就找不到donor節點而無法做IST。怎麼辦?
5.6 Binlog追數據
對於停機時間較長的節點,可能集羣所有節點gcache緩存的write-sets都小於停機期間產生的write-sets,這時候停機節點將無法直接IST加入集羣。不過可以藉助binlog追數據,使停機節點的數據儘可能靠近集羣,再做IST。
1、 藉助已恢復的seqno找到其他節點的binlog的start-position:
如果停機期間,集羣生成了多個binlog,那麼就需要藉助mysqlbinlog工具定位到具體的binlog文件。這裏假設是mysql-bin.0000015:
mysqlbinlog -vv mysql-bin.0000015| grep -A5 “Xid = 529045”

這裏用到的特性就是Xid的值,也就是GTID值的後半部分,在集羣中同一個事務對應的Xid值是完全一樣並且有序的,只要找到Xid的值,就可以在其它節點中找到對應位置及相關信息。
2、導出binlog:
mysqlbinlog –skip-gtids=true –start-position=388603320 -vv mysql-bin.0000015 > data.sql
這裏需要藉助–skip-gtids=true參數使解析出來的文件中就不包含“SET@@SESSION.GTID_NEXT=”,否則可能會binlog導入失效。
3、非主模式啓動節點
這裏讓故障節點以非主模式啓動,是爲了和集羣保持一致的uuid,同時又能獨立啓動以導入binlog。如下操作:
grastate.dat文件做如下修改:
safe_to_bootstrap: 1
獨立啓動:
/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf --wsrep-cluster-address="gcomm://" &關閉非主模式,導入數據:
mysql> SET GLOBAL wsrep_provider_options='pc.bootstrap=true'; mysql> source data.sql ;這裏除了要導入data.sql,還需要導入mysql-bin.0000015之後的binlog,讓故障節點儘可能追近集羣。
關閉實例並還原grastate.dat配置:
safe_to_bootstrap: 0
4、正常啓動實例
通過binlog,故障節點已經恢復到最接近集羣的狀態了。如果擔心,也可以再檢查是當前狀態是否滿足以IST方式加入集羣,畢竟導binlog的過程也是很花時間的。
6.總結
文章對Percona Xtradb Cluster的介紹,比較淺顯,更深入的探索,是需要結合業務場景進行鑽研。
站在業務的角度,Percona Xtradb Cluster多點寫入、數據強一致的特點確實十分誘人。站在運維的角度,Percona Xtradb Cluster需要花一番功夫:節點的性能、中間鏈路的穩定性、集羣調優等,都是不小的一筆運維成本。展望未來,我們對Percona Xtradb Cluster仍需不斷深入實踐,從遊戲的異地雙活,再到平臺級的多活。