




實現延遲任務的方式有很多,各有利弊,有單機和分佈式的。在這裏做一個總結,在遇到這類問題的時候希望給大家一個參考和思路。
延遲任務有別於定式任務,定式任務往往是固定週期的,有明確的觸發時間。而延遲任務一般沒有固定的開始時間,它常常是由一個事件觸發的,而在這個事件觸發之後的一段時間內觸發另一個事件。延遲任務相關的業務場景如下:
場景一:物聯網系統經常會遇到向終端下發命令,如果命令一段時間沒有應答,就需要設置成超時。
場景二:訂單下單之後30分鐘後,如果用戶沒有付錢,則系統自動取消訂單。
下面我們來探討一些方案,其實這些方案沒有好壞之分,和系統架構一樣,只有最適合。對於數據量較小的情況下,任意一種方案都可行,考慮的是簡單明瞭和開發速度,儘量避免把系統搞複雜了。而對於數據量較大的情況下,就需要有一些選擇,並不是所有的方案都適合了。
1. 數據庫輪詢
這是比較常見的一種方式,所有的訂單或者所有的命令一般都會存儲在數據庫中。我們會起一個線程去掃數據庫或者一個數據庫定時Job,找到那些超時的數據,直接更新狀態,或者拿出來執行一些操作。這種方式很簡單,不會引入其他的技術,開發週期短。
如果數據量比較大,千萬級甚至更多,插入頻率很高的話,上面的方式在性能上會出現一些問題,查找和更新對會佔用很多時間,輪詢頻率高的話甚至會影響數據入庫。一種可以嘗試的方式就是使用類似TBSchedule或Elastic-Job這樣的分佈式的任務調度加上數據分片功能,把需要判斷的數據分到不同的機器上執行。
如果數據量進一步增大,那掃數據庫肯定就不行了。另一方面,對於訂單這類數據,我們也許會遇到分庫分表,那上述方案就會變得過於複雜,得不償失。
2. JDK延遲隊列
Java中的DelayQueue位於java.util.concurrent包下,作爲單機實現,它很好的實現了延遲一段時間後觸發事件的需求。由於是線程安全的它可以有多個消費者和多個生產者,從而在某些情況下可以提升性能。DelayQueue本質是封裝了一個PriorityQueue,使之線程安全,加上Delay功能,也就是說,消費者線程只能在隊列中的消息“過期”之後才能返回數據獲取到消息,不然只能獲取到null。
之所以要用到PriorityQueue,主要是需要排序。也許後插入的消息需要比隊列中的其他消息提前觸發,那麼這個後插入的消息就需要最先被消費者獲取,這就需要排序功能。PriorityQueue內部使用最小堆來實現排序隊列。隊首的,最先被消費者拿到的就是最小的那個。使用最小堆讓隊列在數據量較大的時候比較有優勢。使用最小堆來實現優先級隊列主要是因爲最小堆在插入和獲取時,時間複雜度相對都比較好,都是O(logN)。
下面例子實現了未來某個時間要觸發的消息。我把這些消息放在DelayQueue中,當消息的觸發時間到,消費者就能拿到消息,並且消費,實現處理方法。示例代碼:
-
/* -
* 定義放在延遲隊列中的對象,需要實現Delayed接口 -
*/ -
public class DelayedTask implements Delayed { -
private int _expireInSecond = 0; -
public DelayedTask(int delaySecond) { -
Calendar cal = Calendar.getInstance(); -
cal.add(Calendar.SECOND, delaySecond); -
_expireInSecond = (int) (cal.getTimeInMillis() / 1000); -
} -
public int compareTo(Delayed o) { -
long d = (getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS)); -
return (d == 0) ? 0 : ((d < 0) ? -1 : 1); -
} -
public long getDelay(TimeUnit unit) { -
//TODO Auto-generated method stub -
Calendar cal = Calendar.getInstance(); -
return _expireInSecond - (cal.getTimeInMillis() / 1000); -
} -
}
下面定義了三個延遲任務,分別是10秒,5秒和15秒。依次入隊列,期望5秒鐘後,5秒的消息先被獲取到,然後每個5秒鐘,依次獲取到10秒數據和15秒的那個數據。
-
public static void main(String[] args) throws InterruptedException { -
//TODO Auto-generated method stub -
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); -
//定義延遲隊列 -
DelayQueue<DelayedTask> delayQueue = new DelayQueue<DelayedTask>(); -
//定義三個延遲任務 -
DelayedTask task1 = new DelayedTask(10); -
DelayedTask task2 = new DelayedTask(5); -
DelayedTask task3 = new DelayedTask(15); -
delayQueue.add(task1); -
delayQueue.add(task2); -
delayQueue.add(task3); -
System.out.println(sdf.format(new Date()) + " start"); -
while(delayQueue.size() != 0) { -
//如果沒到時間,該方法會返回 -
DelayedTask task = delayQueue.poll();
-
if(task != null) { -
Date now = new Date(); -
System.out.println(sdf.format(now)); -
} -
Thread.sleep(1000); -
} -
}
輸出結果如下圖:

DelayQueue是一種很好的實現方式,雖然是單機,但是可以多線程生產和消費,提高效率。拿到消息後也可以使用異步線程去執行下一步的任務。如果有分佈式的需求可以使用Redis來實現消息的分發,如果對消息的可靠性有非常高的要求可以使用消息中間件:
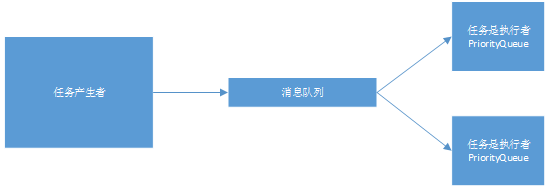
使用DelayQueue需要考慮程序掛掉之後,內存裏面未處理消息的丟失帶來的影響。
3. JDK ScheduledExecutorService
JDK自帶的一種線程池,它能調度一些命令在一段時間之後執行,或者週期性的執行。文章開頭的一些業務場景主要使用第一種方式,即,在一段時間之後執行某個操作。代碼例子如下:
-
public static void main(String[] args) { -
// TODO Auto-generated method stub -
ScheduledExecutorService executor = Executors.newScheduledThreadPool(100); -
for(inti = 10; i > 0; i--) { -
executor.schedule(new Runnable() { -
public void run() { -
//TODO Auto-generated method stub -
System.out.println("Work start, thread id:" + Thread.currentThread().getId() + " " + sdf.format(new Date())); -
} -
}, i, TimeUnit.SECONDS); -
} -
}
執行結果:

ScheduledExecutorService的實現類ScheduledThreadPoolExecutor提供了一種並行處理的模型,簡化了線程的調度。DelayedWorkQueue是類似DelayQueue的實現,也是基於最小堆的、線程安全的數據結構,所以會有上例排序後輸出的結果。
ScheduledExecutorService比上面一種DelayQueue更加實用。因爲,一般來說,使用DelayQueue獲取消息後觸發事件都會實用多線程的方式執行,以保證其他事件能準時進行。而ScheduledThreadPoolExecutor就是對這個過程進行了封裝,讓大家更加方便的使用。同時在加強了部分功能,比如定時觸發命令。
4. 時間輪
時間輪是一種非常驚豔的數據結構。其在Linux內核中使用廣泛,是Linux內核定時器的實現方法和基礎之一。按使用場景,大致可以分爲兩種時間輪:原始時間輪和分層時間輪。分層時間輪是原始時間輪的升級版本,來應對時間“槽”數量比較大的情況,對內存和精度都有很高要求的情況。我們延遲任務的場景一般只需要用到原始時間輪就可以了。
原始時間輪:如下圖一個輪子,有8個“槽”,可以代表未來的一個時間。如果以秒爲單位,中間的指針每隔一秒鐘轉動到新的“槽”上面,就好像手錶一樣。如果當前指針指在1上面,我有一個任務需要4秒以後執行,那麼這個執行的線程回調或者消息將會被放在5上。那如果需要在20秒之後執行怎麼辦,由於這個環形結構槽數只到8,如果要20秒,指針需要多轉2圈。位置是在2圈之後的5上面(20 % 8 + 1)。這個圈數需要記錄在槽中的數據結構裏面。這個數據結構最重要的是兩個指針,一個是觸發任務的函數指針,另外一個是觸發的總第幾圈數。時間輪可以用簡單的數組或者是環形鏈表來實現。

相比DelayQueue的數據結構,時間輪在算法複雜度上有一定優勢。DelayQueue由於涉及到排序,需要調堆,插入和移除的複雜度是O(lgn),而時間輪在插入和移除的複雜度都是O(1)。
時間輪比較好的開源實現是Netty的
-
//創建Timer, 精度爲100毫秒, -
HashedWheelTimer timer = new HashedWheelTimer(); -
System.out.println(sdf.format(new Date())); -
MyTask task1 = new MyTask(); -
MyTask task2 = new MyTask(); -
MyTask task3 = new MyTask(); -
timer.newTimeout(task1, 5, TimeUnit.SECONDS); -
timer.newTimeout(task2, 10, TimeUnit.SECONDS); -
timer.newTimeout(task3, 15, TimeUnit.SECONDS); -
//阻塞main線程 -
try{ -
System.in.read(); -
} catch(IOException e) { -
//TODO Auto-generated catch block -
e.printStackTrace(); -
}
其中HashedWheelTimer有多個構造函數。其中:
ThreadFactory :創建線程的類,默認Executors.defaultThreadFactory()。
TickDuration:多少時間指針順時針轉一格,單位由下面一個參數提供。
TimeUnit:上一個參數的時間單位。
TicksPerWheel:時間輪上的格子數。
如果一個任務要在120s後執行,時間輪是默認參數的話,那麼這個任務在時間輪上需要經過
120000ms / (512 * 100ms) = 2輪
120000ms % (512 * 100ms) = 176格。
在使用HashedWheelTimer的過程中,延遲任務的實現最好使用異步的,HashedWheelTimer的任務管理和執行都在一個線程裏面。如果任務比較耗時,那麼指針就會延遲,導致整個任務就會延遲。
4. Quartz
quartz是一個企業級的開源的任務調度框架,quartz內部使用TreeSet來保存Trigger,如下圖。Java中的TreeSet是使用TreeMap實現,TreeMap是一個紅黑樹實現。紅黑樹的插入和刪除複雜度都是logN。和最小堆相比各有千秋。最小堆插入比紅黑樹快,刪除頂層節點比紅黑樹慢。

相比上述的三種輕量級的實現功能豐富很多。有專門的任務調度線程,和任務執行線程池。quartz功能強大,主要是用來執行週期性的任務,當然也可以用來實現延遲任務。但是如果只是實現一個簡單的基於內存的延時任務的話,quartz就稍顯龐大。
5. Redis ZSet
Redis中的ZSet是一個有序的Set,內部使用HashMap和跳錶(SkipList)來保證數據的存儲和有序,HashMap裏放的是成員到score的映射,而跳躍表裏存放的是所有的成員,排序依據是HashMap裏存的score,使用跳躍表的結構可以獲得比較高的查找效率,並且在實現上比較簡單。
-
public class ZSetTest { -
private JedisPool jedisPool = null; -
//Redis服務器IP -
private String ADDR = "10.23.22.42"; -
//Redis的端口號 -
private int PORT = 6379; -
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); -
public void intJedis() { -
jedisPool = new JedisPool(ADDR, PORT); -
} -
public static void main(String[] args) { -
//TODO Auto-generated method stub -
ZSetTest zsetTest = new ZSetTest(); -
zsetTest.intJedis(); -
zsetTest.addItem(); -
zsetTest.getItem(); -
zsetTest.deleteZSet(); -
} -
public void deleteZSet() { -
Jedis jedis = jedisPool.getResource(); -
jedis.del("zset_test"); -
} -
public void addItem() { -
Jedis jedis = jedisPool.getResource(); -
Calendar cal1 = Calendar.getInstance(); -
cal1.add(Calendar.SECOND, 10); -
int second10later = (int) (cal1.getTimeInMillis() / 1000); -
Calendar cal2 = Calendar.getInstance(); -
cal2.add(Calendar.SECOND, 20); -
int second20later = (int) (cal2.getTimeInMillis() / 1000); -
Calendar cal3 = Calendar.getInstance(); -
cal3.add(Calendar.SECOND, 30); -
int second30later = (int) (cal3.getTimeInMillis() / 1000); -
Calendar cal4 = Calendar.getInstance(); -
cal4.add(Calendar.SECOND, 40); -
int second40later = (int) (cal4.getTimeInMillis() / 1000); -
Calendar cal5 = Calendar.getInstance(); -
cal5.add(Calendar.SECOND, 50); -
int second50later = (int) (cal5.getTimeInMillis() / 1000); -
jedis.zadd("zset_test", second50later, "e"); -
jedis.zadd("zset_test", second10later, "a"); -
jedis.zadd("zset_test", second30later, "c"); -
jedis.zadd("zset_test", second20later, "b"); -
jedis.zadd("zset_test", second40later, "d"); -
System.out.println(sdf.format(new Date()) + " add finished."); -
} -
public void getItem() { -
Jedis jedis = jedisPool.getResource(); -
while(true) { -
try { -
Set<Tuple> set = jedis.zrangeWithScores("zset_test", 0, 0); -
String value = ((Tuple) set.toArray()[0]).getElement(); -
int score = (int) ((Tuple) set.toArray()[0]).getScore(); -
Calendar cal = Calendar.getInstance(); -
int nowSecond = (int) (cal.getTimeInMillis() / 1000); -
if (nowSecond >= score) { -
jedis.zrem("zset_test", value); -
System.out.println(sdf.format(new Date()) + " removed value:" + value); -
} -
if(jedis.zcard("zset_test") <= 0) -
{ -
System.out.println(sdf.format(new Date()) + " zset empty "); -
return; -
} -
Thread.sleep(1000); -
} catch(InterruptedException e) { -
//TODO Auto-generated catch block -
e.printStackTrace(); -
} -
} -
} -
}
在用作延遲任務的時候,可以在添加數據的時候,使用zadd把score寫成未來某個時刻的unix時間戳。消費者使用zrangeWithScores獲取優先級最高的(最早開始的的)任務。注意,zrangeWithScores並不是取出來,只是看一下並不刪除,類似於Queue的peek方法。程序對最早的這個消息進行驗證,是否到達要運行的時間,如果是則執行,然後刪除zset中的數據。如果不是,則繼續等待。
由於zrangeWithScores 和 zrem是先後使用,所以有可能有併發問題,即兩個線程或者兩個進程都會拿到一樣的一樣的數據,然後重複執行,最後又都會刪除。如果是單機多線程執行,或者分佈式環境下,可以使用Redis事務,也可以使用由Redis實現的分佈式鎖,或者使用下例中Redis Script。你可以在Redis官方的Transaction 章節找到事務的相關內容。
使用Redis的好處主要是:
1. 解耦:把任務、任務發起者、任務執行者的三者分開,邏輯更加清晰,程序強壯性提升,有利於任務發起者和執行者各自迭代,適合多人協作。
2. 異常恢復:由於使用Redis作爲消息通道,消息都存儲在Redis中。如果發送程序或者任務處理程序掛了,重啓之後,還有重新處理數據的可能性。
3. 分佈式:如果數據量較大,程序執行時間比較長,我們可以針對任務發起者和任務執行者進行分佈式部署。特別注意任務的執行者,也就是Redis的接收方需要考慮分佈式鎖的問題。
6. Jesque
Jesque是Resque的java實現,Resque是一個基於Redis的Ruby項目,用於後臺的定時任務。Jesque實現延遲任務的方法也是在Redis裏面建立一個ZSet,和上例一樣的處理方式。上例提到在使用ZSet作爲優先級隊列的時候,由於zrangeWithScores 和 zrem沒法保證原子性,所有在分佈式環境下會有問題。在Jesque中,它使用的Redis Script來解決這個問題。Redis Script可以保證操作的原子性,相比事務也減少了一些網絡開銷,性能更加出色。
7. RabbitMQ TTL和DXL
使用RabbitMQ的TTL和DXL實現延遲隊列在這裏不做詳細的介紹。
綜上所述,解決延遲隊列有很多種方法。選擇哪個解決方案也需要根據不同的數據量、實時性要求、已有架構和組件等因素進行判斷和取捨。對於比較簡單的系統,可以使用數據庫輪訓的方式。數據量稍大,實時性稍高一點的系統可以使用JDK延遲隊列(也許需要解決程序掛了,內存中未處理任務丟失的情況)。如果需要分佈式橫向擴展的話推薦使用Redis的方案。但是對於系統中已有RabbitMQ,那RabbitMQ會是一個更好的方案。