




一 簡介
1 同步和異步
函數或方法掉調用的時候,被調用者是否能得到最終結果來判斷同步和異步
直接得到最終結果的,就是同步調用
不直接得到最終結果的,就是異步調用同步就是我讓你打飯,你不打好我就不走開,直到你打飯給了我
異步就是我讓你打飯,你大着,我不等你,但是我會盯着你,你打完我會過來拿走,異步並不能保證多長時間將飯打完。異步給的是臨死結果,目前是拿不到的
同步只看結果是不是最終結果進行判斷
2 阻塞,非阻塞
函數或方法調用的時候,是否立即返回
立即返回就是非阻塞調用
不立即返回就是阻塞調用
3 區別
同步,異步,阻塞,非阻塞 不相關
同步異步強調的是結果
阻塞,非阻塞強調的是時間,是否等待同步和異步的區別在於:調用者是否得到可想要的結果
同步就是一直要執行到返回結果
異步就是直接返回了,但是不是最終結果,調用者不能通過這種調用方式得到結果,還是需要通過被調用者,使用其他方式通知調用者,來取回最終的結果
同步阻塞:我啥事也不幹,就等你打飯給我,打飯是結果,而且我啥事也不敢就一直等,同步加阻塞。
同步非阻塞:我等着你打飯給我,但我可以完手機,看電視,打飯是結果,但我不一直等
異步阻塞: 我要打飯,你說等號,並沒有給我返回飯,我啥事也不幹,就等着飯好了叫我,叫號。
異步非阻塞:我要打飯,你說等號,並沒有返回飯,我在旁邊看電視,玩手機,反打好了叫我。
4 同步IO,異步IO,IO 多路複用
1 IO 兩個階段
1 數據準備階段
2 內核空間複製會用戶進程緩衝區階段
2 發生IO的時候
1 內核從輸入設備讀寫數據
2 進程從內核複製數據
系統調用read 函數
第一個IO阻塞的函數是input函數,是一個同步阻塞模型,網絡也是一個IO,標準輸入,標準輸出等也IO
5 零拷貝
1 零拷貝概念
CPU 不執行拷貝數據從一個存儲區域到另一個存儲區域的任務,這通常用於通過網絡傳輸一個文件時用於減少CPU週期和內存帶寬。
操作系統某些組件(例如驅動程序、文件系統和網絡協議棧)若採用零複製技術,則能極大地增強了特定應用程序的性能,並更有效地利用系統資源。通過使CPU得以完成其他而非將機器中的數據複製到另一處的任務,性能也得到了增強。另外,零複製操作減少了在用戶空間與內核空間之間切換模式的次數。
零複製協議對於網絡鏈路容量接近或超過CPU處理能力的高速網絡尤爲重要。在這種網絡下,CPU幾乎將所有時間都花在複製要傳送的數據上,因此將成爲使通信速率低於鏈路容量的瓶頸。
2 零拷貝帶來的好處
1 減少甚至完全避免不必要的CPU拷貝,從而讓CPU 解脫出來去執行其他任務
2 減少內存帶寬佔用
3 通常零拷貝技術還能減少用戶空間和內核空間之間的上下文切換
3 Linux 系統的"用戶空間"和"內核空間"
從Linux系統來看,除了引導系統的BIN區,整個內存空間主要被分成兩部分:
1 內核空間(kernel space ) : 主要提供給程序調度,內存分配,連接硬件資源等程序邏輯空間
2 用戶空間 (user space): 提供給各個進程的主要空間,用戶空間不具備訪問內核空間資源的權限,因此如果應用程序需要使用到內核空間的資源,則需要通過系統調度來完成,從用戶空間切換到內核空間,然後在完成操作後再從內核空間切換到用戶空間
4 Linux 中的零拷貝技術的實現方向
1 直接I/O: 對於這種傳輸方式來說,應用程序可以直接訪問硬件存儲,操作系統內核只是輔助數據傳輸,這種方式依舊存在用戶空間和內核空間的上下文切換,但硬件上的數據不會拷貝到內核空間,而是直接拷貝到可用戶空間,因此直接IO不存在內核空間緩衝區和用戶空間緩衝區之間的數據拷貝
2 在數據傳輸過程中,避免數據在用戶空間緩衝區和內核空間緩衝區之間的CPU拷貝,以及數據在系統內核空間的CPU拷貝,
3 copy-on-write(寫時複製技術):在某些情況下,Linux操作系統的內核緩衝區可能被多個應用程序共享,操作系統有可能會將用戶空間緩衝區地址映射考內核空間緩衝區,當應用程序需要對共享的數據進行修改時,才需要真正的拷貝數據到應用程序的用戶空間緩衝區中,並且對自己的用戶空間的緩衝區的數據進行修改不會影響到其他共享數據的應用程序,所以,如果應用程序不需要對數據進行任何修改,就不會存在數據從系統內核空間緩衝區拷貝到用戶空間緩衝區的操作。
對於零拷貝技術是否實現主要依賴於操作系統底層是否提供相應的支持。
5 傳統I/O 操作
1 發起read系統調用: 導致用戶空間到內核空間的上下文切換(第一次上下文切換),通過DMA引擎將文件中的數據從磁盤上讀取到內核空間緩衝區(第一次拷貝:hand drive ----> kernel buffer)
2 將內核空間緩衝區的數據拷貝到用戶空間緩衝區中(第二次拷貝: kernel buffer ---> user buffer),然後read系統調用返回,而系統調用的返回又會導致一次內核空間到用戶空間的上下文切換(第二次上下文切換)
3 發出write系統調用: 導致用戶空間到內核空間的上下文切換(第三次上下文切換),將用戶空間緩衝區的數據拷貝到內核空間中於socket相關的緩衝區中,(及第二步從內核空間緩衝區拷貝的數據原封不動的再次拷貝到內核空間的socket緩衝區中)( 第三次拷貝: user buffer--> socket buffer)
4 write 系統調用返回,導致內核空間到用戶空間的再次上下文切換(第四次上下文切換),通過DMA引擎將內核緩衝區中的數據傳遞到協議引擎(第四次拷貝:socket buffer -> protocol engine ),這次拷貝時獨立的異步的過程。
事實上調用的返回並不保證數據被傳輸,甚至不保證數據傳輸的開始,只是意味着將我麼要發送的數據放入到了一個待發送的隊列中,除非實現了優先環或者隊列,否則會是先進先出的方式發送數據的。
總的來說,傳統的I/O操作進行了4次用戶空間與內核空間的上下文切換,以及4次數據拷貝。其中4次數據拷貝中包括了2次DMA拷貝和2次CPU拷貝。
傳統模式爲何將數據從磁盤讀取到內核空間而不是直接讀取到用戶空間緩衝區,其原因是爲了減少IO操作以提高性能,因爲OS會根據局部性原理一次read() 系統調用的時候預讀取更多的文件數據到內核空間緩衝區中,這樣當下一次read()系統調用的時候發現要讀取的數據已經存在於內核空間緩衝區的時候只需要直接拷貝數據到用戶空間緩衝區即可,無需再進行一次低效的磁盤IO操作。
Bufferedinputstream 作用是會根據情況自動爲我們預讀取更多的數據到他自己維護的一個內部字節數據緩衝區,這樣能減少系統調用次數來提高性能。
總的來說,內核緩衝區的一大作用是爲了減少磁盤IO操做,Bufferedinputstream 則是減少"系統調用"
6 DMA
DMA(direct memory access) --- 直接內存訪問,DMA 是允許外設組件將IO數據直接傳送到主存儲器並並且傳輸不需要CPU參與,以此解放CPU去做其他的事情。
而用戶空間與內核空間之間的數據傳輸並沒有類似DMA這種可以不需要CPU參與的傳輸工具,因此用戶空間與內核空間之間的數據傳輸是需要CPU全程參與的。所有也就有了通過零拷貝技術來減少和避免不必要的CPU數據拷貝過程。
7 通過sendfile 實現零拷貝IO
1 發起sendfile系統調用,導致用戶空間到內核空間的上下文切換(第一次上下文切換),通過DMA引擎將磁盤文件中的內容拷貝到內核空間緩衝區中(第一次拷貝: hard drive --> kernel buffer)然後再將數據從內核空間拷貝到socket相關的緩衝區中,(第二次拷貝,kernel ---buffer --> socket buffer)
2 sendfile 系統調用返回,導致內核空間到用戶空間的上下文切換(第二次上下文切換)。通過DMA 引擎將內核空間的socket緩衝區的數據傳遞到協議引擎(第三次拷貝:socket buffer-> protocol engine )
總的來說,通過sendfile實現的零拷貝I/O只使用了2次用戶空間與內核空間的上下文切換,以及3次數據的拷貝。其中3次數據拷貝中包括了2次DMA拷貝和1次CPU拷貝。
Q:但通過是這裏還是存在着一次CPU拷貝操作,即,kernel buffer ——> socket buffer。是否有辦法將該拷貝操作也取消掉了?
A:有的。但這需要底層操作系統的支持。從Linux 2.4版本開始,操作系統底層提供了scatter/gather這種DMA的方式來從內核空間緩衝區中將數據直接讀取到協議引擎中,而無需將內核空間緩衝區中的數據再拷貝一份到內核空間socket相關聯的緩衝區中。
8 帶有DMA 收集拷貝功能的sendfile 實現的IO
從Linux 2.4 開始,操做系統底層提供了帶有scatter/gather 的DMA來從內核空間緩衝區中將數據讀取到協議引擎中,這樣以來待傳輸的數據可以分散再存儲的不同位置,而不需要再連續存儲中存放,那麼從文件中讀出的數據就根本不需要被拷貝到socket緩衝區中去,只是需要將緩衝區描述符添加到socket緩衝區中去,DMA收集操作會根據緩衝區描述符中的信息將內核空間中的數據直接拷貝到協議引擎中
1 發出sendfile 系統調用,導致用戶空間到內核空間的上下文切換,通過DMA 引擎將磁盤文件內容拷貝到內核空間緩衝區中(第一次拷貝: hard drive -> kernel buffer)
2 沒有數據拷貝到socket緩衝區,取而代之的是隻有向相應的描述信息被拷貝到相應的socket緩衝區中,該描述信息包含了兩個方面: 1 kernel buffer 的內存地址 2 kernel buffer 的偏移量。
3 sendfile 系統調用返回,導致內核空間到用戶空間的上下文切換(第二次上下文切換),DMA gather copy 根據 socket緩衝區中描述符提供的位置和偏移量信息直接將內核空間的數據拷貝到協議引擎上(kernel buffer --> protocol engine),這樣就避免了最後依次CPU數據拷貝
總的來說,帶有DMA收集拷貝功能的sendfile實現的I/O只使用了2次用戶空間與內核空間的上下文切換,以及2次數據的拷貝,而且這2次的數據拷貝都是非CPU拷貝。這樣一來我們就實現了最理想的零拷貝I/O傳輸了,不需要任何一次的CPU拷貝,以及最少的上下文切換。
在Linux 2.6.33 版本之前sendfile支持文件到套接字之間的傳輸,及in_fd 相當於一個支持mmap的文件,out_fd 必須是一個socket,但從Linux 2.6.33版本開始,out_fd 可以是任意類型文件描述符,所以從Linux 2.6.33 版本開始sendfile 可以支持文件到文件,文件到套接字之間的數據傳輸。
9 傳統I/O 和零拷貝及sendfile零拷貝I/O比較
傳統I/O通過兩條系統指令read、write來完成數據的讀取和傳輸操作,以至於產生了4次用戶空間與內核空間的上下文切換的開銷;而sendfile只使用了一條指令就完成了數據的讀寫操作,所以只產生了2次用戶空間與內核空間的上下文切換。
傳統I/O產生了2次無用的CPU拷貝,即內核空間緩存中數據與用戶空間緩衝區間數據的拷貝;而sendfile最多隻產出了一次CPU拷貝,即內核空間內之間的數據拷貝,甚至在底層操作體系支持的情況下,sendfile可以實現零CPU拷貝的I/O。
因傳統I/O用戶空間緩衝區中存有數據,因此應用程序能夠對此數據進行修改等操作;而sendfile零拷貝消除了所有內核空間緩衝區與用戶空間緩衝區之間的數據拷貝過程,因此sendfile零拷貝I/O的實現是完成在內核空間中完成的,這對於應用程序來說就無法對數據進行操作了。
Q:對於上面的第三點,如果我們需要對數據進行操作該怎麼辦了?
A:Linux提供了mmap零拷貝來實現我們的需求
10 通過mmap 實現零拷貝I/O
Mmap(內存映射)是一個比sendfile昂貴但優於傳統IO的方式
1 發出mmap系統調用,導致用戶空間到內核空間的上下文切換(第一次上下文切換)。通過DMA引擎將磁盤文件中的內容拷貝到內核空間緩衝區中(第一次拷貝: hard drive ——> kernel buffer)。
2 mmap 系統調用返回,導致內核空間到用戶空間的上下文切換(第二次上下文切換),接着用戶空間和內核空間共享這個緩衝區,而不需要將數據從內核空間拷貝到用戶空間,因此用戶空間和內核空間共享的緩衝區
3 發出write 系統調用紅,導致用戶空間到內核空間第三次上下文切換,將數據從內核空間拷貝到內核空間的socket相關的緩衝區(第二次拷貝:kernel buffer ----> socket buffer )
4 write 系統調用返回,導致內核空間到用戶空間的上下文切換(第四次上下文切換),通過DMA 引擎將內核空間socket緩衝區的數據傳遞到協議引擎(第三次拷貝: socket buffer---> protocol engine)
總的來說,通過mmap實現的零拷貝I/O進行了4次用戶空間與內核空間的上下文切換,以及3次數據拷貝。其中3次數據拷貝中包括了2次DMA拷貝和1次CPU拷貝。
6 同步IO
1 同步阻塞IO
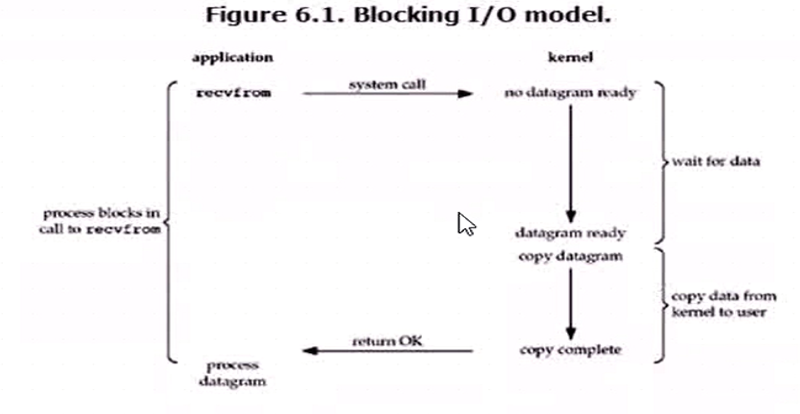
在文件讀取進入內核空間和從內核空間拷貝進入用戶進程空間的過程中,沒有任何的數據返回,客戶端在一直等待狀態。
2 同步非阻塞
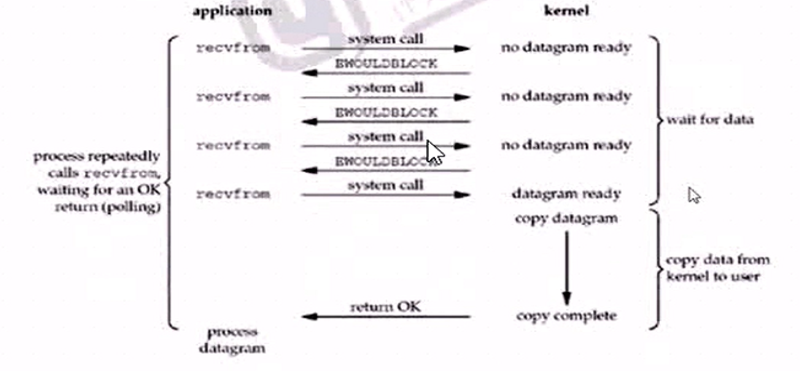
進程調用read操作,如果IO沒有準備好,立即返回ERROR,進程不阻塞,用戶可以再次發起系統調用,如果內核已經準備好,就阻塞,然後複製數據到用戶空間
第一階段數據沒準備好,就先忙別的,等會再看看,檢查數據是否準備好了的過程是非阻塞的
第二階段是阻塞的,及內核空間和用戶空間之間複製數據是阻塞的,但是要等待飯盛好纔是完事,這是同步的。
3 IO 多路複用
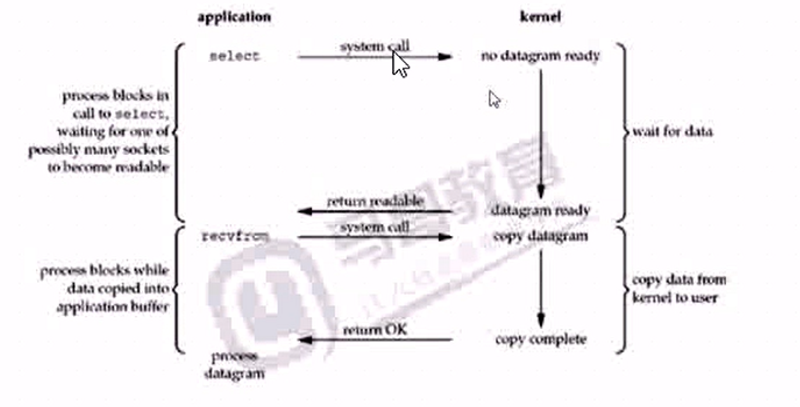
所謂的IO多路複用,就是同時監控多個IO,有一個準備好了,就不需要等待開始處理,提高了同時處理IO的能力
select是所有平臺都支持,poll是對select的升級
epoll,Linux 系統內核2.5+ 開始支持,對select和epoll的增強,在監視的基礎上,增加了回調機制,BSD,Mac的kqueue,還有windows的iocp
如果既想訪問網絡,又想訪問文件,則先將準備好的數據先處理,那個準備好了就處理那個
能夠提高同時處理IO的能力,誰先做玩我先處理誰
上面的兩種方式,效率太差了,等完一個完成後再等一個,太慢了。
誰好了處理誰,不同的平臺對IO多路複用的實現方式是不同的
Select 和 poll 在Linux,Windows,和MAC中都支持
一般來將select和poll 在同一個層次,epoll是Linux中存在的
select原理
1 將關注的IO操作告訴select函數並調用,進程阻塞,內核監視select關注的文件,描述符FD,被關注的任何一個FD對應的IO準備好了數據,select就返回,在使用read將數據複製到用用戶進程。其select模式下的準備好的通知是沒有針對性的,需要用戶自己找到是否是自己的並進行處理。select做到的是時間重疊
epoll增加了回調機制,那一路準備好了,我會告訴你,有一種是你不用管了,好了我直接替你調用。
7 異步調用
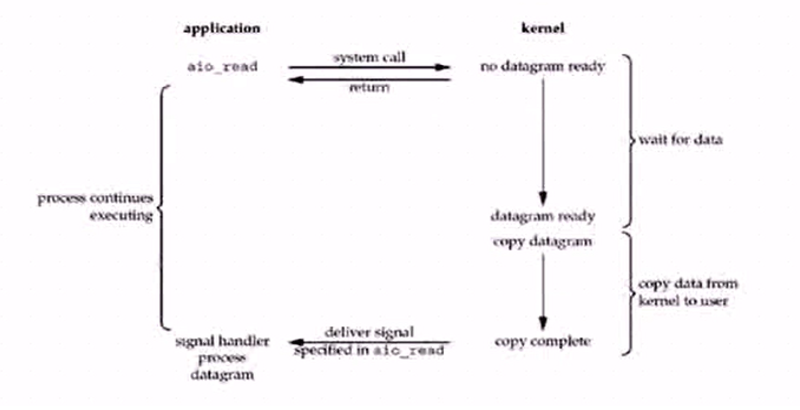
兩個階段
等待數據準備和拷貝階段
立即返回數據,給一個號。到時候叫號,直接返回
信號句柄,告訴你幾號好了,(signal handler process datagram)
有些時候是需要爭搶的
我可以不通知你,我也可以通知你後你再來
理解數據層面的東西,就不要理解其他的socket層面的東西
文件中實際就是兩個緩衝隊列,每個隊列是一個。
在異步模型中,操作系統通你的,你是在用戶空間的,操作系統可以是在內核空間的,進程和線程等等的都是操作系統層面的東西。
整個過程中進程都可以做其他的事,就算是通知了,也不一定要立即反應,這和你的設置有關
Linux中的AIO 的系統調用,內核版本從2.6開始支持
一般的IO是IO多路複用和異步複用
二 python中的IO 多路複用
1 簡介
IO 多路複用
大多數操作系統都支持select和poll
Linux 2.5+ 支持epoll
BSD,Mac支持kqueue
Windows 的 iocp
python的select庫實現了select,poll系統調用,這個基本上操作系統都支持,部分實現了epoll,底層的IO多路複用模塊
開發中的選擇
1 完全跨平臺,select 和poll ,但其性能較差
2 針對不同的操作系統自行選擇支持技術,這樣會提高IO處理能力selectors庫
3.4 版本後提供這個庫,高級的IO複用庫
類層次結構BaseSelector
+-- SelectSelector 實現select
+-- PollSelector 實現poll
+-- EpollSelector 實現epoll
+-- DevpollSelector 實現devpoll
+-- KqueueSelector 實現kqueueselectors.DefaultSelector返回當前平臺最有效,性能最最高的實現
但是由於沒有實現windows的IOCP,所以只能退化爲select。
默認會自適應,其會選擇最佳的方式,Linux 會直接選擇 epoll ,通過此處,能拿到平臺的最優方案。
DefaultSelector 源碼
if 'KqueueSelector' in globals():
DefaultSelector = KqueueSelector
elif 'EpollSelector' in globals():
DefaultSelector = EpollSelector
elif 'DevpollSelector' in globals():
DefaultSelector = DevpollSelector
elif 'PollSelector' in globals():
DefaultSelector = PollSelector
else:
DefaultSelector = SelectSelector2 基本方法
abstractmethod register(fileobj,events,data=None)
爲selection註冊一個文件獨享,監視它的IO事件
fileobj 被監視的文件對象,如socket對象
events 事件,該文件對象必須等待的事件,read或write

data 可選的與此文件對象相關的不透明數據,如可用來存儲每個客戶端的會話ID,可以是函數,類,實例,如果是函數,有點回調的意思,通知某個函數,某個實例,某個類,可以是類屬性,等,都可以,None表示消息發生了,沒人認領。
3 基本實現socket 操作監控
1 思路
第一步 :需要實例化 ,選擇一個最優的實現,將其實例化(選擇不同平臺實現的IO複用的最佳框架),python內部處理
第二步:註冊函數,將要監控對象,要監控事件和監控觸發後對象寫入register註冊中
1 註冊: 對象,啥事件,調用的函數
2 進行循環和監控select函數的返回,當監控的對象的事件滿足時會立即返回,在events中可以拿到這些數據events中有我是誰,我是什麼事件觸發的(讀和寫),讀的滿足可以recv,key 是讓我監控的東西,event是其什麼事件觸發的。將對象和事件拿到後做相應的處理。
第三步:實時關注socket有讀寫操作,從而影響events的變化
對socket來判斷有沒有讀,若讀了,則直接觸發對應的機制進行處理。一旦有新的連接準備,則會將其消息發送給對應的函數進行處理相關的操作。被調用的函數是有要求的,其需要傳送mask的,data 就是未來要調用的函數,建立了事件和未來參數之間建立的關係。
Accept 本身就是一個read事件
Selector 會調用自己的select函數進行監視,這個函數是阻塞的,當數據已經在內核緩衝區準備好了,你就可以讀取了,這些事給select進行處理在註冊的時候,後面加了data,後面直接使用,直接調用,不用管其他,data和每一個觀察者直接對應起來的。
只要有一個滿足要求,直接返回
讀事件指的是in操作,及就是當有連接的時候
當通知成功後,其函數內部是不會阻塞了,等待通知,通知成功後就不會阻塞了。此處的data相當於直接帶着窗口號,直接進行處理,而不需要一個一個的遍歷
當一個滿足了,就不會阻塞了。events: 兩個IO都滿足,等待幾路,幾路的IO都在此處,如果滿足,則直接向下打印events,其中key是註冊的唯一的東西,socket 也可以,但是可以定義socket的讀和寫,一般都是合着的
第四步:調用對應事件的對象,並執行相關操作
然後將events拿出來解構,key本身是一個多元祖,key上保存着註冊塞進去的data,key是存儲了4個信息的元祖,此處的data稱爲回調函數,加上() 稱爲調用
2 代碼實現
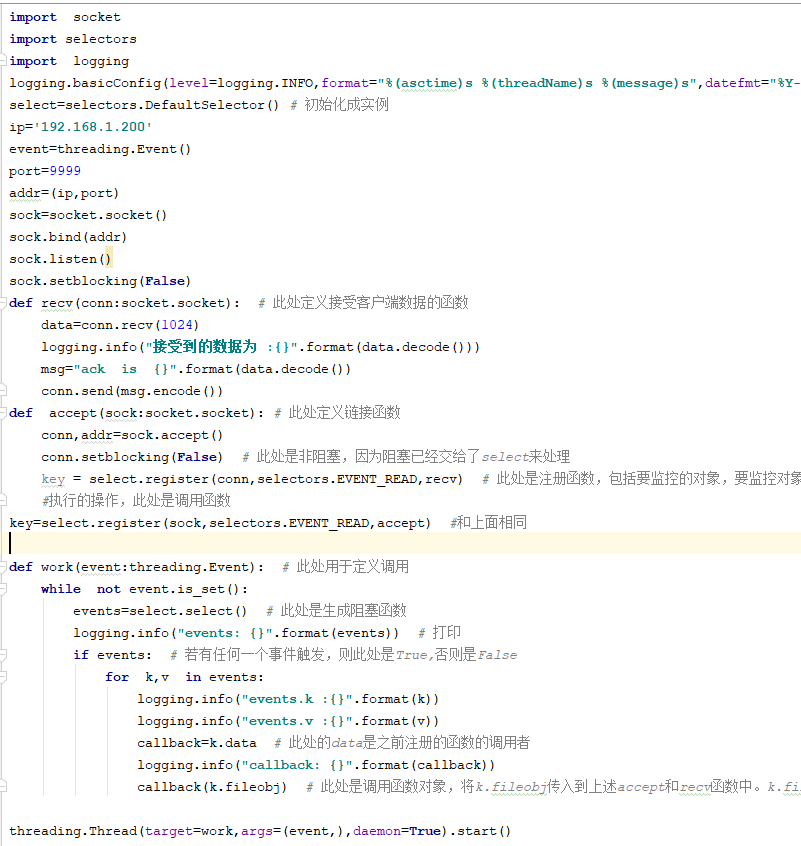

代碼下載目錄
IO 多路複用初始代碼
https://pan.baidu.com/s/18B5OL89Z4YSxEmX4gNkgDA
3 基本參數講解
1 events參數:
2019-09-01 09:37:46 Thread-1 events: [(SelectorKey(fileobj=<socket.socket fd=4, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('192.168.1.200', 9999)>, fd=4, events=1, data=<function accept at 0x7f50feb61d90>), 1)]
events中包含了兩組
第一組 :
fileobj 及套接字返回的相關參數,和之前的socket中的accpet中的conn 相似,fd 及文件描述符
events 及事件類型,
兩種
data 及註冊調用的函數,上述的有accept 和recv 函數
 兩種
兩種 第二組:
1 events 的狀態,及mask
2 select.get_map() 參數:
1 select.get_map().items() 中的key
2019-09-01 09:43:52 MainThread key:SelectorKey(fileobj=<socket.socket fd=4, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('192.168.1.200', 9999)>, fd=4, events=1, data=<function accept at 0x7fcf5a50ad90>)此處的key和上面的列表中的二元祖中的前一個完全相同
2 select.get_map().items() 中的fobj
2019-09-01 09:43:52 MainThread fobj: 4
其是其中的文件描述符
4 總結:
IO 多路複用就是一個線程來處理所有的IO
在單線程中進行處理IO多路複用
多線程中的IO阻塞時浪費CPU資源,其是等待狀態,等待狀態雖然不佔用CPU資源,但線程本身的狀態需要維持,還是會佔用一定的資源
4 改進版本的socket 監控
1 描述
send 是寫操作,有可能阻塞,也可以監聽
recv所在的註冊函數,要監聽讀與寫事件,回調的時候,需要mask 來判斷究竟是讀觸發了還是寫觸發了,所以,需要修改方法聲明,增加mask
寫操作當發送羣聊時,其每個鏈接是獨立的,需要queue隊列保存相關的數據,並進行接受和發送操作
 讀與寫事件,回調的時候,需要mask 來判斷究竟是讀觸發了還是寫觸發了,所以,需要修改方法聲明,增加mask
讀與寫事件,回調的時候,需要mask 來判斷究竟是讀觸發了還是寫觸發了,所以,需要修改方法聲明,增加mask 2 代碼實現
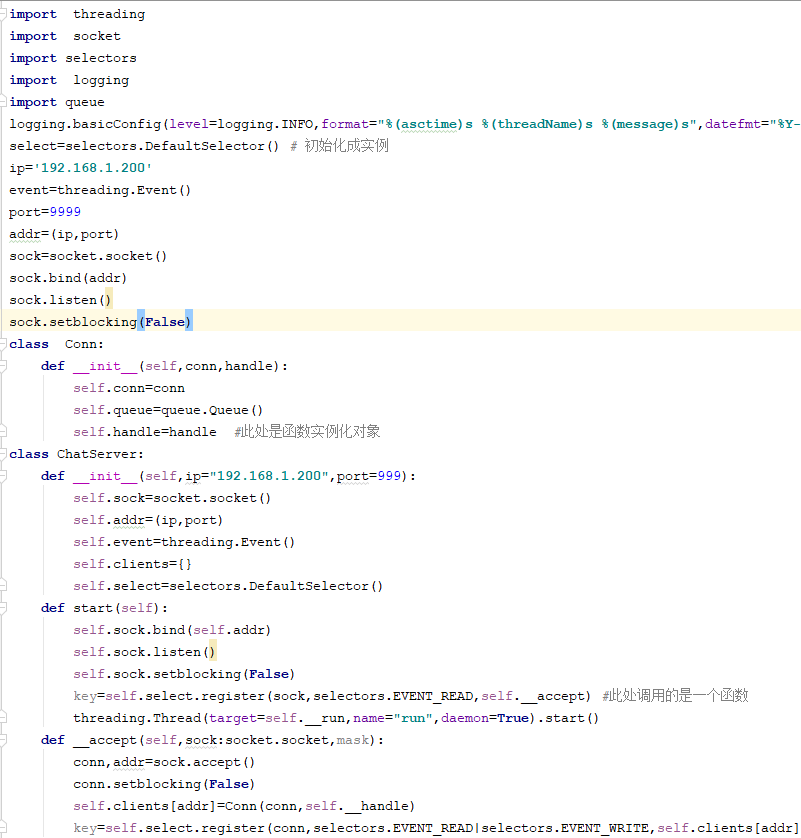


IO 多路複用最終代碼
https://pan.baidu.com/s/1y-3j607_5DxBpa4wZNxCEQ
三 異步編程
1 asyncio 簡介
3.4 版本加入標準庫
asyncio 底層是基於selectors實現的,看似庫,其實就是一個框架,包括異步IO,事件循環,協程,任務等
並行和串行的區分:
兩個事件的因果關係:
若有因果關係,則可以使用串行
若無因果關係,則可以使用並行,及多線程來處理
2 相關參數及詳解
| 參數 | 含義 |
|---|---|
| asyncio.get_event_loop() | 返回一個事件循環對象,是asyncio.BaseEventLoop的實例 |
| AbstractEventLoop.stop() | 停止運行事件循環 |
| AbstractEventLoop.run_forever() | 一直運行,直到stop() |
| AbstractEventLoop.run_until_complete(future) | 運行直到Future對象運行完成 |
| AbstractEventLoop.close() | 關閉事件循環 |
| AbstractEventLoop.is_running() | 返回事件循環是否運行 |
| AbstractEventLoop.close() | 關閉事件 |
3 協程
1 基本實例
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def a():
for i in range(3):
print (i)
def b():
for i in "abc":
print (i)
a()
b()

此處的默認執行順序是a()到b()的順序執行,若要使其交叉執行,則需要使用yield 來實現
實現方式如下
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
def a():
for i in range(3):
print (i)
yield
def b():
for i in "abc":
print (i)
yield
a=a()
b=b()
for i in range(3):
next(a)
next(b)
上述實例中通過生成器完成了調度,讓兩個函數都幾乎同時執行,這樣的調度不是操作系統進行的。而是用戶自己設計完成的
這個程序編寫要素:
1 需要使用yield來讓出控制權
2 需要循環幫助執行
2 協程簡介
協程不是進程,也不是線程,它是用戶空間調度的完成併發處理的方式。
進程,線程由操作系統完成調度,而協程是線程內完成調度的,不需要更多的線程,自然也沒有多線程切換的開銷
協程是非搶佔式調度,只有一個協程主動讓出控制權,另一個協程纔會被調度。
協程也不需要使用鎖機制,因爲其是在同一個線程中執行的
多CPU下,可以使用多進程和協程配合,既能進程併發,也能發揮出協程在單線程中的優勢。
python中的協程是基於生成器的。
3 協程基本書寫
3.4 引入的asyncio,使用裝飾器
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
@asyncio.coroutine
def a():
for i in range(3):
print (i)
yield
loop=asyncio.get_event_loop()
loop.run_until_complete(a())
loop.close()結果如下

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
@asyncio.coroutine
def a():
for i in range(3):
print (i)
yield
@asyncio.coroutine
def b():
for i in "abc":
print(i)
yield
loop=asyncio.get_event_loop()
task=[a(),b()]
loop.run_until_complete(asyncio.wait(task))
loop.close()結果如下

3.5 及其以後版本的書寫方式:
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
async def a():
for i in range(3):
print (i)
# await asyncio.sleep(0.0001)
async def b(): #使用此方式後,不能再次使用wait了
for i in "abc":
print(i)
# await asyncio.sleep(0.0001)
print (asyncio.iscoroutinefunction(a)) # 此處判斷是否是函數,和調用無關
a=a()
print (asyncio.iscoroutine(a)) # 此處是判斷對象,是調用後的結果
loop=asyncio.get_event_loop()
task=[a,b()]
loop.run_until_complete(asyncio.wait(task))
loop.close()
結果如下
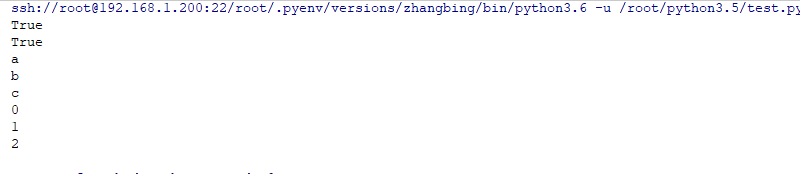
async def 用來定義協程函數,iscoroutinefunction()返回True,協程函數中可以不包含await,async關鍵字,但是不能使用yield關鍵字
如果生成器函數調用返回生成器對象一樣,協程函數調用也會返回一個對象成爲協程對象,iscoroutine()返回爲True
4 TCP echo server 實現
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
import socket
ip='192.168.1.200'
port=9999
async def handler(conn,send):
while True:
data=await conn.read(1024) # 接受客戶端的數據,相當於recv,wait 就是IO等待,此處會等待
print (conn,send)
client_addr=send.get_extra_info('peername') # 獲取客戶端信息
msg="{} {}".format(data.decode(),client_addr).encode() #封裝消息
send.write(msg) # 傳輸到客戶端
await send.drain() # 此處相當於makefile中的flush ,此處也會IO等待
loop=asyncio.get_event_loop() #實例化一個循環事件
crt=asyncio.start_server(handler,ip,port,loop=loop) #使用異步方式啓動函數,最後一個參數是應該用誰來循環處理
server=loop.run_until_complete(crt) # 此處是直到此方法完成後終止
print (server)
try:
loop.run_forever()
except KeyboardInterrupt:
pass
finally:
server.close()
loop.close()5 擴展aiohttp 庫
異步的http 庫,使用協程實現的
需要安裝第三方模塊 aiohttp
pip install aiohttp http server 基礎實現
#!/usr/bin/poython3.6
#conding:utf-8
from aiohttp import web
async def indexhandle(request:web.Request): # 處理客戶端請求函數
print("web",web.Request)
return web.Request(text=request.path,status=201) #返回文本和狀態碼
async def handle(request:web.Request):
print (request.match_info)
print (request.query_string)
return web.Response(text=request.match_info.get('id','0000'),status=200) # 此處是返回給客戶端的數據,後面的0000是默認
app=web.Application()
#路由選路,
app.router.add_get('/',indexhandle) # http://192.168.1.200:80/
app.router.add_get('/{id}',handle) # http://192.168.1.200:80/12345
web.run_app(app,host='0.0.0.0',port=80) #監聽IP和端口並運行客戶端實現
#!/usr/bin/poython3.6
#conding:utf-8
import asyncio
from aiohttp import ClientSession
async def get_html(url:str):
async with ClientSession() as session: # 獲取session,要和服務端通信,必須先獲取session,之後才能進行相關的操作 ,此處使用with是打開關閉會話,保證會話能夠被關閉。
async with session.get(url) as res: # 需要這個URL資源,獲取,
print (res.status) # 此處返回爲狀態碼
print (await res.text()) # 此處返回爲文本信息
url='http://www.baidu.com'
loop=asyncio.get_event_loop()
loop.run_until_complete(get_html(url))
loop.close()