




先來詳細的講一下EM算法。
前提準備
Jupyter notebook 或 Pycharm
火狐瀏覽器或Chrome瀏覽器
win7或win10電腦一臺
網盤提取csv數據
需求分析
實現高斯混合模型的 EM 算法(GMM_EM)
高斯混合模型是多個高斯模型的線性疊加而成的,高斯混合模型的概率分佈表示如下:
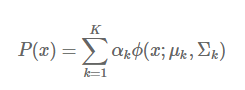
其中,k表示模型的個數,αkα_kαk 是第 k 個模型的係數,表示出現該模型的概率,ϕ(x;μk,Σk) 是第 k 個高斯模型的概率分佈。
E步:樣本 xix_ixi來自於第 k 個模型的概率,我們把這個概率稱爲模型 k 對樣本 xix_ixi 的“責任”,也叫“響應度”,記作 γ(ik)γ_(ik)γ(ik),計算公式如下:
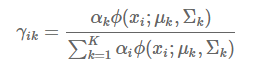
M步:根據樣本和當前 γ 矩陣重新估計參數,注意這裏 x 爲列向量
【目標】給定一堆沒有標籤的樣本和模型個數 K,以此求得混合模型的參數,然後就可以用這個模型來對樣本進行聚類。
python代碼如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal #本問題考慮的是高斯混合模型,所以導入多元高斯分佈multivariate_normal
def prob_Y_k(Y,mu_k,cov_k): #Y爲樣本矩陣
norm = multivariate_normal(mean = mu_k , cov = cov_k) #生成多元正太分佈,mu爲第k個模型的均值,cov爲第k個模型的協方差矩陣(協方差矩陣必須是實對稱矩陣)
return norm.pdf(Y) #返回樣本Y來自於第k個模型的概率
def Estep(Y,mu,cov,alpha): #Y爲樣本矩陣,alpha爲權重
N = Y.shape[0] #樣本數
K = alpha.shape[0] #模型數
assert N>1 , "There must be more than one sample!" #爲避免單個樣本導致返回的結果的類型不一致,因此要求樣本數必須大於一
assert K>1 , "There must be more than one gaussian model!" #爲避免單個模型結果的類型不一致,因此要求模型須大於一
gamma = np.mat(np.zeros((N,K))) #初始化響應度矩陣,行對應樣本數,列對應模型數
prob = np.zeros((N,K)) #初始化所有樣本出現的概率矩陣,行對應樣本數,列對應響應度
for k in range(K):
prob[:,k] = prob_Y_k(Y,mu[k],cov[k]) #第k個模型的概率prob_Y_k
prob = np.mat(prob) #K個prob放入數組中
for k in range(K):
gamma[:,k] = alpha[k] * prob[:,k] #計算模型k對樣本i的響應度
for i in range(N):
gamma[i,:] /= np.sum(gamma[i,:]) #第i個樣本的佔總樣本的響應程度
return gamma #gamma爲響應度矩陣
def Mstep(Y,gamma): #傳入樣本矩陣Y和Estep得到的gamma響應度矩陣
N, D = Y.shape #N爲樣本數,D爲特徵數
K = gamma.shape[1] #模型數
mu = np.zeros((K,D)) #初始化參數均值mu,每個模型的D維各有均值故mu的矩陣爲K行D列
cov = [] #初始化參數協方差矩陣
alpha = np.zeros(K) # 初始化權重數組,每個模型都有權值
#接下來是更新每個模型的參數
for k in range(K):
Nk = np.sum(gamma[:,k]) #第k個模型所有樣本的響應度之和
mu[k,:] = np.sum(np.multiply(Y, gamma[:,k]),axis=0)/Nk #更新參數均值mu,對每個特徵求均值
cov_k = (Y - mu[k]).T * np.multiply((Y - mu[k]), gamma[:,k]) / Nk #更新cov
cov = np.append(cov_k)
alpha[k] = Nk / N
cov = np.array(cov)
return mu, cov, alpha
def normalize_data(Y): #將所有數據進行歸一化處理,
for i in range(Y.shape[1]):
max_data = Y[:,i].max()
min_data = Y[:,i].min()
Y[:,i] = (Y[:,i] - min_data)/(max_data - min_data) #此處用到min-max歸一化
debug("Data Normalized")
return Y
def init_params(shape,K): #在執行該算法之前,需要先給出一個初始化的模型參數。我們讓每個模型的μ爲隨機值,Σ 爲單位矩陣,α 爲 1/K,即每個模型初始時都是等概率出現的。
N, D = shape
mu = np.random.rand(K, D) #生成一個K行D列的[0,1)之間的數組
cov = np.array([np.eye(D)] * K) #生成K個D維的對角矩陣
alpha = np.array([1.0 / K] * K) #生成K個權重
debug("Parameters initialized.")
debug("mu:",mu, "cov:",cov ,"alpha:",alpha,sep = "\n" )
return mu, cov, alpha
def GMM_EM(Y, K, times): #高斯混合EM算法,Y爲給定樣本矩陣,K爲模型個數,times爲迭代次數,目的是求該模型的參數
Y = normalize_data(Y) #調用前面定義的normalize_data函數,歸一化樣本矩陣Y
mu, cov, alpha = init_params(Y.shape, K) #調用init_params函數得到初始化的參數mu,cov,alpha
for i in range(times):鄭州婦科醫院 http://m.zyfuke.com/
gamma = Estep(Y, mu, cov, alpha) #調用Estep得到響應度矩陣
mu, cov, alpha = Mstep(Y, gamma) #調用Mstep得到更新後的參數mu,cov,alpha
debug("{sep} Result {sep}".format(sep="-"*20))
debug("mu:", mu , "cov:",cov , "alpha:",alpha , sep="\n")
return mu,cov,alpha
import matplotlib.pyplot as plt
from gmm import *
DEBUG = True
Y = np.loadtxt("gmm.data") #載入數據
matY = np.matrix(Y ,copy = True)
K = 2 #模型個數(相當於聚類的類別個數)
mu, cov, alpha = GMM_EM(matY , K , 100) #調用GMM_EM函數,計算GMM模型參數
N = Y.shape[0]
gamma = Estep(matY, mu, cov, alpha) #求當前模型參數下,各模型對樣本的響應矩陣
category = gamma.argmax(axis = 1).flatten().tolist()[0] #對每個樣本,求響應度最大的模型下標,作爲其類別標識
class1 = np.array([Y[i] for i in range(N) if category[i] == 0]) #將每個樣本放入對應樣本的列表中
class2 = np.array([Y[i] for i in range(N) if category[i] == 1])
plt.plot(class1[:,0],class1[:,1], 'rs' ,label = "class1")
plt.plot(class2[:,0],class2[:,1], 'bo' ,label = "class2")
plt.legend(loc = "best")
plt.title("GMM Clustering By EM Algorithm")
plt.show()
import numpy as np
import matplotlib.pyplot as plt
cov1 = np.mat("0.3 0 ; 0 0.1") #2維協方差矩陣(必須是對角矩陣)
cov2 = np.mat("0.2 0 ; 0 0.3")
mu1 = np.array([0,1])
mu2 = np.array([2,1])
sample = np.zeros((100,2)) #初始化100個樣本,樣本特徵爲2
sample[:30, :] = np.random.multivariate_normal(mean=mu1, cov=cov1, size=30) #生成多元正態分佈矩陣
sample[30:, :] = np.random.multivariate_normal(mean=mu2, cov=cov2, size=70)
np.savetxt("sample.data",sample) # 將array保存到txt文件中
plt.plot(sample[:30, 0], sample[:30, 1], "bo") #30個樣本用藍色圓圈標記
plt.plot(sample[30:, 0], sample[30:, 1], "rs") #70個樣本用紅色方塊標記
plt.title("sample_data")
plt.show()