




作者:myazi
鏈接:https://www.zhihu.com/question/20467170/answer/222792995
來源:知乎
著作權歸作者所有。商業轉載請聯繫作者獲得授權,非商業轉載請註明出處。
1歸一化特點 對不同特徵維度的伸縮變換的目的是使各個特徵維度對目標函數的影響權重是一致的,即使得那些扁平分佈的數據伸縮變換成類圓形。這也就改變了原始數據的一個分佈。好處:1 提高迭代求解的收斂速度2 提高迭代求解的精度2標準化特點 對不同特徵維度的伸縮變換的目的是使得不同度量之間的特徵具有可比性。同時不改變原始數據的分佈。好處1 使得不同度量之間的特徵具有可比性,對目標函數的影響體現在幾何分佈上,而不是數值上2 不改變原始數據的分佈舉例根據人的身高和體重預測人的健康指數假設有如下原始樣本數據是四維的(當然一般不會有這麼無聊的數據)

從上面兩個座標圖可以看出,樣本在數據值上的分佈差距是不一樣的,但是其幾何距離是一致的。而標準化就是一種對樣本數據在不同維度上進行一個伸縮變化(而不改變數據的幾何距離),也就是不改變原始數據的信息(分佈)。這樣的好處就是在進行特徵提取時,忽略掉不同特徵之間的一個度量,而保留樣本在各個維度上的信息(分佈)。
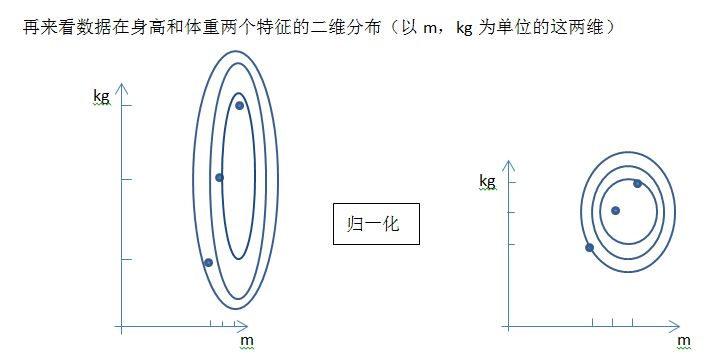
從採用大單位的身高和體重這兩個特徵來看,如果採用標準化,不改變樣本在這兩個維度上的分佈,則左圖還是會保持二維分佈的一個扁平性;而採用歸一化則會在不同維度上對數據進行不同的伸縮變化(歸一區間,會改變數據的原始距離,分佈,信息),使得其呈類圓形。雖然這樣樣本會失去原始的信息,但這防止了歸一化前直接對原始數據進行梯度下降類似的優化算法時最終解被數值大的特徵所主導。歸一化之後,各個特徵對目標函數的影響權重是一致的。這樣的好處是在提高迭代求解的精度。