




什麼是kafka
Kafka官網自己的介紹是:一個可支持分佈式的流平臺。
kafka官網介紹
kafka三個關鍵能力:
1.發佈訂閱記錄流,類似於消息隊列與企業信息系統
2.以容錯的持久方式存儲記錄流
3.對流進行處理
kafka通常應用再兩大類應用中:
1.構建實時流數據管道,在系統或應用程序之間可靠地獲取數據
2.構建轉換或響應數據流的實時流應用程序
kafka的一些基本概念:
1.Kafka作爲一個集羣運行在一個或多個服務器上,這些服務器可以跨越多個數據中心。
2.Kafka集羣將記錄流存儲在稱爲topic的類別中。
3.每個記錄由一個鍵、一個值和一個時間戳組成。
kafka核心API:
1.Producer API:允許應用程序將記錄流發佈到一個或多個topic。
2.Consumer API:允許應用程序訂閱一個或多個topic並處理生成給它們的記錄流。
3.Streams API:允許應用程序充當流處理器,使用來自一個或多個topic的輸入流,
並生成一個或多個輸出topic的輸出流,從而有效地將輸入流轉換爲輸出流。
4.Connector API:允許構建和運行可重用的生產者或消費者,將topic連接到現有的應用程序或數據系統。
例如,到關係數據庫的連接器可能捕獲對錶的每個更改。作爲消息系統
傳統消息傳遞有兩類模型:消息隊列、發佈訂閱。在消息隊列中,一個消費者池可以從一個服務器讀取數據,而每個記錄都將被髮送到其中一個服務器;在發佈-訂閱中,記錄被廣播給所有消費者。這兩種模型各有優缺點:
消息隊列優缺點:
它允許您在多個使用者實例上劃分數據處理,這使您可以擴展處理。
隊列不是多訂閱者的—一旦一個進程讀取了它丟失的數據。
發佈訂閱優缺點:
Publish-subscribe允許您將數據廣播到多個進程,
但是由於每個消息都傳遞到每個訂閱者,因此無法擴展處理。作爲消息傳遞系統,那麼跟mq有什麼區別呢?(RabbitMq\redis\RocketMq\ActiveMq)
RabbitMQ:
遵循AMQP協議,由內在高併發的erlang語言開發,用在實時的對可靠性要求比較高的消息傳遞上.
萬級數據量,社區活躍度極高,可視化操作界面豐富。
提供了全面的核心功能,是消息隊列的優秀產品。
因爲是erlang語言開發,難以維護並且開發者很難二次開發。
Redis:
redis的主要場景是內存數據庫,作爲消息隊列來說可靠性太差,而且速度太依賴網絡IO。
在服務器本機上的速度較快,且容易出現數據堆積的問題,在比較輕量的場合下能夠適用。
RocketMq:
rocketMq幾十萬級別數據量,基於Java開發。是阿里巴巴開源的一個消息產品。
應對了淘寶雙十一考驗,並且文檔十分的完善,擁有一些其他消息隊列不具備的高級特性,
如定時推送,其他消息隊列是延遲推送,如rabbitMq通過設置expire字段設置延遲推送時間。
又比如rocketmq實現分佈式事務,比較可靠的。RocketMq也是用過的唯一支持分佈式事務的一款產品。
Kafka:
kafka原本設計的初衷是日誌統計分析,現在基於大數據的背景下也可以做運營數據的分析統計。
kafka真正的大規模分佈式消息隊列,提供的核心功能比較少。基於zookeeper實現的分佈式消息訂閱。
幾十萬級數據量級,比RokectMq更強。
客戶端和服務器之間的通信是通過一個簡單的、高性能的、語言無關的TCP協議來完成的。
ActiveMq:
Apache ActiveMQ™是最流行的開源、多協議、基於java的消息服務器。它支持行業標準協議,
因此用戶可以在各種語言和平臺上選擇客戶端。可以使用來自C、c++、Python、. net等的連接性。
使用通用的AMQP協議集成您的多平臺應用程序。使用STOMP在websockets上交換web應用程序之間的消息。
使用MQTT管理物聯網設備。支持您現有的JMS基礎結構及其他。ActiveMQ提供了支持任何messagi的強大功能
和靈活性。備註:因爲該文章主要介紹kafka,所以上述只是簡單羅列了一些特點,如果有興趣的同學可以詳細的分析一下,這些產品我後續都會專門寫文章來歸納總結分析,在這裏先簡單帶過。
爲什麼要用消息隊列?
該部分是擴展內容,很多人包括我剛畢業那年使用消息隊列,但別人問道我爲啥用消息隊列,我都沒有一個很清晰的認識,所以在這裏也說一下。希望給有需要的同學一些幫助。
那麼爲什麼要使用消息隊列呢?首先我們來回顧一下消息傳遞。前端而言,傳統方式是通過全局變量來傳遞,後面有了數據總線的概念,再後來有相應的解決方案產品比如說vuex、redux、store等。對於後端來說,最先系統之間的通信,消息傳遞都非常依賴於通信對象彼此,高度耦合,後面有了一些產品來解決這些問題,比如說webservice.但這樣的方式極其不友好,而且維護繁瑣,職責難以分清,工作量增加,所以mq誕生後,基本解決了這些問題。
消息隊列的引入是爲了:
1.解耦:
比如:A系統操作p,需要將消息傳遞給B、C兩個系統,如果沒有消息隊列,那麼A系統中需要給B發一條消息,
又得給C發一條消息,然後有一天D、E、F系統說:A系統你也要給我發p的消息,這個時候A又得修改代碼,
發佈上線,DEF才能正常接收消息。然後過了n天,C又說,不要給我發消息了,把給我發消息的部分去掉吧。
A系統的開發人員又得哐哧哐哧的去掉,發佈上線。這樣日復一日,隨着系統增多,接入和退出的操作增多,
那麼A系統需要頻繁發佈上線,降低了穩定性、可用時間、同時每次上線都需要測試跟蹤測試,這裏面的成本
與風險不言而喻。而消息隊列一旦引入,A不需要關心誰消費,誰退出消費,A只負責將消息放入隊列即可,
而其他系統只需要監聽這個隊列,就算其他系統退出,對A而言也是沒有任何影響的,能夠一直持續不斷的
提供服務,這難道不香嗎?
2.異步
比如說:傳統方式發送消息給B、C、D,需要120ms,那麼如果採用了消息隊列,就可以大大降低耗時。但
這些對於那些非必要的同步業務邏輯適用。
3.削峯
傳統模式下,請求直接進入到數據庫,當峯值到達一定時,必然會掛掉。如果適用了中間件消息隊列,那麼就可以很好的保證系統正常提供服務,這也是秒殺系統中會常常談到的限流、這樣可以防止系統崩潰,提供系統可用性。配置MAVEN
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.0</version>
</dependency>生產者
/**
* @author chandlerHuang
* @description @TODO
* @date 2020/1/15
*/
public class KafkaProducerService implements Runnable {
private final KafkaProducer<String,String> producer;
private final String topic;
public KafkaProducerService(String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", "綁定的外網IP:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
this.producer = new KafkaProducer<String, String>(props);
this.topic = topic;
}
@Override
public void run() {
int messageNo = 1;
try {
for(;;) {
String messageStr="["+messageNo+"]:hello,boys!";
producer.send(new ProducerRecord<String, String>(topic, "Message", messageStr));
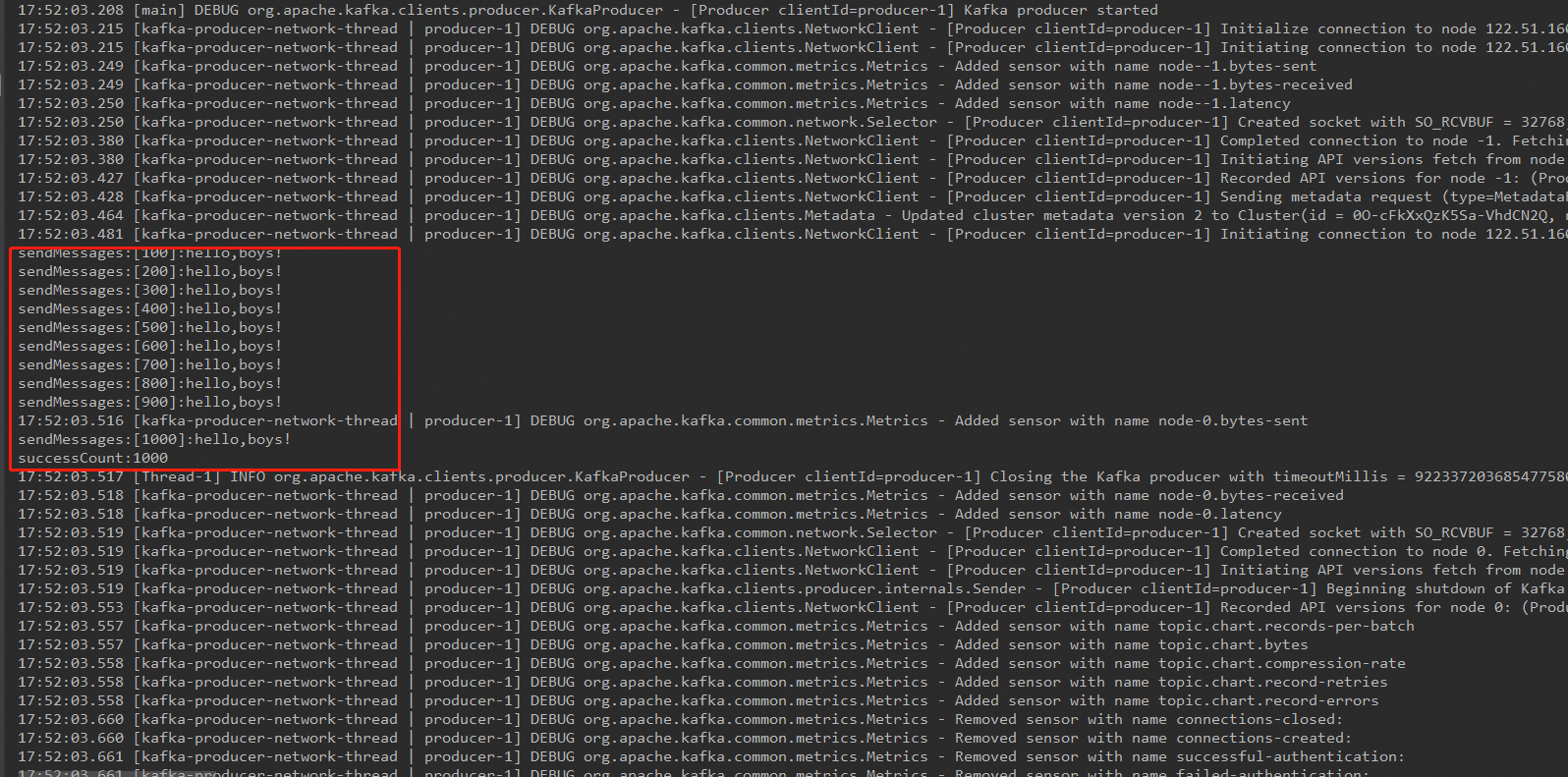
//生產了100條就打印
if(messageNo%100==0){
System.out.println("sendMessages:" + messageStr);
}
//生產1000條就退出
if(messageNo%1000==0){
System.out.println("successCount:"+messageNo);
break;
}
messageNo++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
public static void main(String args[]) {
KafkaProducerService test = new KafkaProducerService(TopicConstant.CHART_TOPIC);
Thread thread = new Thread(test);
thread.start();
}
}

消費者
/**
* @author chandlerHuang
* @description @TODO
* @date 2020/1/15
*/
public class KafkaConsumerService implements Runnable{
private final KafkaConsumer<String, String> consumer;
private ConsumerRecords<String, String> msgList;
private final String topic;
private static final String GROUPID = "groupA";
public KafkaConsumerService(String topicName) {
Properties props = new Properties();
props.put("bootstrap.servers", "綁定的外網IP:9092");
props.put("group.id", GROUPID);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<String, String>(props);
this.topic = topicName;
this.consumer.subscribe(Arrays.asList(topic));
}
@Override
public void run() {
int messageNo = 1;
System.out.println("---------開始消費---------");
try {
for (;;) {
msgList = consumer.poll(1000);
if(null!=msgList&&msgList.count()>0){
for (ConsumerRecord<String, String> record : msgList) {
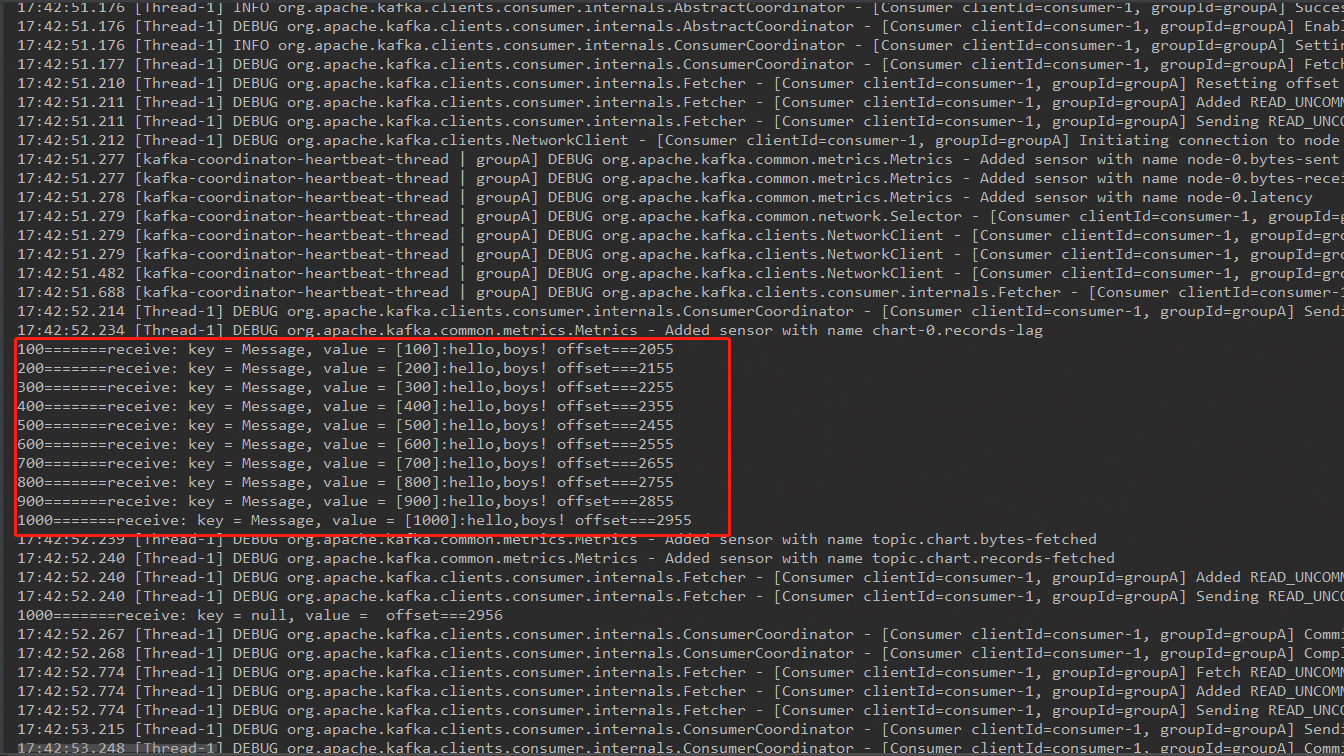
//消費100條就打印 ,但打印的數據不一定是這個規律的
if(messageNo%100==0){
System.out.println(messageNo+"=======receive: key = " + record.key() + ", value = " + record.value()+" offset==="+record.offset());
}
//當消費了1000條就退出
if(messageNo%1000==0){
break;
}
messageNo++;
}
}else{
Thread.sleep(1000);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
public static void main(String args[]) {
KafkaConsumerService test1 = new KafkaConsumerService(TopicConstant.CHART_TOPIC);
Thread thread1 = new Thread(test1);
thread1.start();
}
}
備註:上述demo編寫過程中,發現報了一個Exception:Kafka java client 連接異常(org.apache.kafka.common.errors.TimeoutException: Failed to update metadata )...
kafka中需要配置server.文件:
advertised.listeners=PLAINTEXT://外網地址:9092
zookeeper.connect=內網地址:2181如果你是雲服務器的話需要,在安全組設置對應端口開放,否則無法訪問響應接口!