序列化是幹什麼的
簡單說就是爲了保存在內存中的各種對象的狀態(也就是實例變量,不是方法),並且可以把保存的對象狀態再讀出來。雖然你可以用你自己的各種各樣的方法來保 存object states,但是Java給你提供一種應該比你自己好的保存對象狀態的機制,那就是序列化。
什麼情況下需要序列化
- 當你想把的內存中的對象狀態保存到一個文件中或者數據庫中時候;
- 當你想用套接字在網絡上傳送對象的時候;
- 當你想通過RMI傳輸對象的時候;
序列化的幾種方式
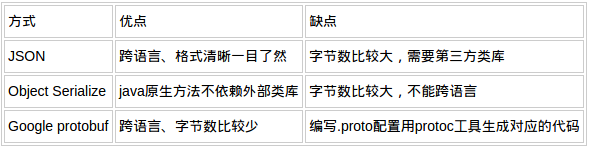
在Java中socket傳輸數據時,數據類型往往比較難選擇。可能要考慮帶寬、跨語言、版本的兼容等問題。比較常見的做法有兩種:一是把對象包裝成JSON字符串傳輸,二是採用java對象的序列化和反序列化。隨着Google工具protoBuf的開源,protobuf也是個不錯的選擇。對JSON,Object Serialize,ProtoBuf 做個對比。
Object Serialize
public interface Serializable類通過實現 java.io.Serializable 接口以啓用其序列化功能。未實現此接口的類將無法使其任何狀態序列化或反序列化。可序列化類的所有子類型本身都是可序列化的。序列化接口沒有方法或字段,僅用於標識可序列化的語義。
要允許不可序列化類的子類型序列化,可以假定該子類型負責保存和還原超類型的公用 (public)、受保護的 (protected) 和(如果可訪問)包 (package) 字段的狀態。僅在子類型擴展的類(父類)有一個可訪問的無參數構造方法來初始化該類的狀態時,纔可以假定子類型有此責任。如果不是這種情況,則聲明一個類爲可序列化類是錯誤的。該錯誤將在運行時檢測到。
在反序列化過程中,將使用該類的公用或受保護的無參數構造方法初始化不可序列化類的字段。可序列化的子類必須能夠訪問無參數的構造方法。可序列化子類的字段將從該流中還原。
Java的序列化機制是通過在運行時判斷類的serialVersionUID來驗證版本一致性的。在進行反序列化時,JVM會把傳來的字節流中的serialVersionUID與本地相應實體(類)的serialVersionUID進行比較,如果相同就認爲是一致的,可以進行反序列化,否則就會出現序列化版本不一致的異常。
serialVersionUID 用來表明類的不同版本間的兼容性。有兩種生成方式:
- 一個是默認的1L,比如:private static final long serialVersionUID = 1L;
- 一個是根據類名、接口名、成員方法及屬性等來生成一個64位的哈希字段,比如: private static final long serialVersionUID = xxxxL;
下面來討論Java類中爲什麼需要重載 serialVersionUID 屬性?
當兩個進程在進行遠程通信時,彼此可以發送各種類型的數據。無論是何種類型的數據,都會以二進制序列的形式在網絡上傳送。發送方需要把這個Java對象轉換爲字節序列,才能在網絡上傳送;接收方則需要把字節序列再恢復爲Java對象。
- 把Java對象轉換爲字節序列的過程稱爲對象的序列化。
- 把字節序列恢復爲Java對象的過程稱爲對象的反序列化。
對象的序列化主要有兩種用途:(1)把對象的字節序列永久地保存到硬盤上,通常存放在一個文件中; (2)在網絡上傳送對象的字節序列;
java.io.ObjectOutputStream代表對象輸出流,它的writeObject(Object obj)方法可對參數指定的obj對象進行序列化,把得到的字節序列寫到一個目標輸出流中。
java.io.ObjectInputStream代表對象輸入流,它的readObject()方法從一個源輸入流中讀取字節序列,再把它們反序列化爲一個對象,並將其返回。
只有實現了Serializable和Externalizable接口的類的對象才能被序列化。Externalizable接口繼承自Serializable接口,實現Externalizable接口的類完全由自身來控制序列化的行爲,而僅實現Serializable接口的類可以採用默認的序列化方式 。
凡是實現Serializable接口的類都有一個表示序列化版本標識符的靜態變量:private static final long serialVersionUID;
序列化運行時使用一個稱爲 serialVersionUID 的版本號與每個可序列化類相關聯,該序列號在反序列化過程中用於驗證序列化對象的發送者和接收者是否爲該對象加載了與序列化兼容的類。如果接收者加載的該對象的類的 serialVersionUID 與對應的發送者的類的版本號不同,則反序列化將會導致 InvalidClassException。可序列化類可以通過聲明名爲serialVersionUID的字段(該字段必須是靜態 (static)、最終 (final) 的 long 型字段)顯式聲明其自己的 serialVersionUID:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果可序列化類未顯式聲明 serialVersionUID,則序列化運行時將基於該類的各個方面計算該類的默認 serialVersionUID 值,如“Java™ 對象序列化規範”中所述。不過,強烈建議 所有可序列化類都顯式聲明 serialVersionUID 值,原因是計算默認的 serialVersionUID 對類的詳細信息具有較高的敏感性,根據編譯器實現的不同可能千差萬別,這樣在反序列化過程中可能會導致意外的 InvalidClassException。因此,爲保證 serialVersionUID 值跨不同 java 編譯器實現的一致性,序列化類必須聲明一個明確的 serialVersionUID 值。還強烈建議使用 private 修飾符顯示聲明 serialVersionUID(如果可能),原因是這種聲明僅應用於直接聲明類 – serialVersionUID 字段作爲繼承成員沒有用處。數組類不能聲明一個明確的 serialVersionUID,因此它們總是具有默認的計算值,但是數組類沒有匹配 serialVersionUID 值的要求。
類的serialVersionUID的默認值完全依賴於Java編譯器的實現,對於同一個類,用不同的Java編譯器編譯,有可能會導致不同的serialVersionUID,也有可能相同。爲了提高serialVersionUID的獨立性和確定性,強烈建議在一個可序列化類中顯示的定義serialVersionUID,爲它賦予明確的值。顯式地定義serialVersionUID有兩種用途:
- 在某些場合,希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有相同的serialVersionUID;在某些場合,不希望類的不同版本對序列化兼容,因此需要確保類的不同版本具有不同的serialVersionUID。
- 當你序列化了一個類實例後,希望更改一個字段或添加一個字段,不設置serialVersionUID,所做的任何更改都將導致無法反序化舊有實例,並在反序列化時拋出一個異常。如果你添加了serialVersionUID,在反序列舊有實例時,新添加或更改的字段值將設爲初始化值(對象爲null,基本類型爲相應的初始默認值),字段被刪除將不設置。
相關注意事項:
a)序列化時,只對對象的狀態進行保存,而不管對象的方法;
b)當一個父類實現序列化,子類自動實現序列化,不需要顯式實現Serializable接口;
c)當一個對象的實例變量引用其他對象,序列化該對象時也把引用對象進行序列化;
詳細描述:
序列化的過程就是對象寫入字節流和從字節流中讀取對象。將對象狀態轉換成字節流之後,可以用java.io包中的各種字節流類將其保存到文件中,管道到另一 線程中或通過網絡連接將對象數據發送到另一主機。對象序列化功能非常簡單、強大,在RMI、Socket、JMS、EJB都有應用。對象序列化問題在網絡 編程中並不是最激動人心的課題,但卻相當重要,具有許多實用意義。
- 對象序列化可以實現分佈式對象。主要應用例如:RMI要利用對象序列化運行遠程主機上的服務,就像在本地機上運行對象時一樣。
- java 對象序列化不僅保留一個對象的數據,而且遞歸保存對象引用的每個對象的數據。可以將整個對象層次寫入字節流中,可以保存在文件中或在網絡連接上傳遞。利用 對象序列化可以進行對象的“深複製”,即複製對象本身及引用的對象本身。序列化一個對象可能得到整個對象序列。
從上面的敘述中,我們知道了對象序列化是java編程中的必備武器,那麼讓我們從基礎開始,好好學習一下它的機制和用法。
java序列化比較簡單,通常不需要編寫保存和恢復對象狀態的定製代碼。實現java.io.Serializable接口的類對象可以轉換成字節流或從 字節流恢復,不需要在類中增加任何代碼。只有極少數情況下才需要定製代碼保存或恢復對象狀態。這裏要注意:不是每個類都可序列化,有些類是不能序列化的, 例如涉及線程的類與特定JVM有非常複雜的關係。
序列化機制:
序列化分爲兩大部分:序列化和反序列化。序列化是這個過程的第一部分,將數據分解成字節流,以便存儲在文件中或在網絡上傳輸。反序列化就是打開字節流並重構對象。對象序列化不僅要將基本數據類型轉換成字節 表示,有時還要恢復數據。恢復數據要求有恢復數據的對象實例。ObjectOutputStream中的序列化過程與字節流連接,包括對象類型和版本信 息。反序列化時,JVM用頭信息生成對象實例,然後將對象字節流中的數據複製到對象數據成員中。
處理對象流:序列化過程和反序列化過程
java.io包有兩個序列化對象的類。ObjectOutputStream負責將對象寫入字節流,ObjectInputStream從字節流重構對象。
我們先了解ObjectOutputStream類吧。ObjectOutputStream類擴展DataOutput接口。writeObject() 方法是最重要的方法,用於對象序列化。如果對象包含其他對象的引用,則writeObject()方法遞歸序列化這些對象。每個 ObjectOutputStream維護序列化的對象引用表,防止發送同一對象的多個拷貝。(這點很重要)由於writeObject()可以序列化整 組交叉引用的對象,因此同一ObjectOutputStream實例可能不小心被請求序列化同一對象。這時,進行反引用序列化,而不是再次寫入對象字節流。
// 序列化 today’s date 到一個文件中.
FileOutputStream f = new FileOutputStream(“tmp”); //創建一個包含恢復對象(即對象進行反序列化信息)的”tmp”數據文件
ObjectOutputStream s = new ObjectOutputStream(f);
s.writeObject(“Today”); //寫入字符串對象;
s.writeObject(new Date()); //寫入瞬態對象;
s.flush();
現在,讓我們來了解ObjectInputStream這個類。它與ObjectOutputStream相似。它擴展DataInput接口。 ObjectInputStream中的方法鏡像DataInputStream中讀取Java基本數據類型的公開方法。readObject()方法從 字節流中反序列化對象。每次調用readObject()方法都返回流中下一個Object。對象字節流並不傳輸類的字節碼,而是包括類名及其簽名。 readObject()收到對象時,JVM裝入頭中指定的類。如果找不到這個類,則readObject()拋出 ClassNotFoundException,如果需要傳輸對象數據和字節碼,則可以用RMI框架。ObjectInputStream的其餘方法用於定製反序列化過程。
//從文件中反序列化 string 對象和 date 對象
FileInputStream in = new FileInputStream(“tmp”);
ObjectInputStream s = new ObjectInputStream(in);
String today = (String)s.readObject(); //恢復對象;
Date date = (Date)s.readObject();
定製序列化過程:
序列化通常可以自動完成,但有時可能要對這個過程進行控制。java可以將類聲明爲serializable,但仍可手工控制聲明爲static或transient的數據成員。
public class SimpleSerializableClass implements Serializable{
String sToday=”Today:”;
transient Date dtToday=new Date();
}
序列化時,類的所有數據成員應可序列化除了聲明爲transient或static的成員。將變量聲明爲transient告訴JVM我們會負責將變元序列 化。將數據成員聲明爲transient後,序列化過程就無法將其加進對象字節流中,沒有從transient數據成員發送的數據。後面數據反序列化時, 要重建數據成員(因爲它是類定義的一部分),但不包含任何數據,因爲這個數據成員不向流中寫入任何數據。記住,對象流不序列化static或 transient。我們的類要用writeObject()與readObject()方法以處理這些數據成員。使用writeObject()與 readObject()方法時,還要注意按寫入的順序讀取這些數據成員。
//重寫writeObject()方法以便處理transient的成員。
public void writeObject(ObjectOutputStream outputStream) throws IOException{
outputStream.defaultWriteObject();//使定製的writeObject()方法可以利用自動序列化中內置的邏輯。
outputStream.writeObject(oSocket.getInetAddress());
outputStream.writeInt(oSocket.getPort());
}
//重寫readObject()方法以便接收transient的成員。
private void readObject(ObjectInputStream inputStream) throws IOException,ClassNotFoundException{
inputStream.defaultReadObject();//defaultReadObject()補充自動序列化
InetAddress oAddress=(InetAddress)inputStream.readObject();
int iPort =inputStream.readInt();
oSocket = new Socket(oAddress,iPort);
iID=getID();
dtToday =new Date();
}
完全定製序列化過程:
如果一個類要完全負責自己的序列化,則實現Externalizable接口而不是Serializable接口。Externalizable接口定義包 括兩個方法writeExternal()與readExternal()。利用這些方法可以控制對象數據成員如何寫入字節流.類實現 Externalizable時,頭寫入對象流中,然後類完全負責序列化和恢復數據成員,除了頭以外,根本沒有自動序列化。這裏要注意了。聲明類實現 Externalizable接口會有重大的安全風險。writeExternal()與readExternal()方法聲明爲public,惡意類可
以用這些方法讀取和寫入對象數據。如果對象包含敏感信息,則要格外小心。這包括使用安全套接或加密整個字節流。到此爲至,我們學習了序列化的基礎部分知識。
以下來源於J2EE API:
對象的默認序列化機制寫入的內容是:對象的類,類簽名,以及非瞬態和非靜態字段的值。其他對象的引用(瞬態和靜態字段除外)也會導致寫入那些對象。可使用引用共享機制對單個對象的多個引用進行編碼,這樣即可將對象的圖形還原爲最初寫入它們時的形狀。
例如,要寫入可通過 ObjectInputStream 中的示例讀取的對象,請執行以下操作:
FileOutputStream fos = new FileOutputStream(“t.tmp”);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeInt(12345);
oos.writeObject(“Today”);
oos.writeObject(new Date());
oos.close();
在序列化和反序列化過程中需要特殊處理的類必須實現具有下列準確簽名的特殊方法:
private void writeObject(java.io.ObjectOutputStream stream) throws IOException;
writeObject 方法負責寫入特定類的對象狀態,以便相應的 readObject 方法可以還原它。該方法本身不必與屬於對象的超類或子類的狀態有關。狀態是通過使用 writeObject 方法或使用 DataOutput 支持的用於基本數據類型的方法將各個字段寫入 ObjectOutputStream 來保存的。
private void readObject(java.io.ObjectInputStream stream) throws IOException, ClassNotFoundException;
readObject 方法負責從流中讀取並還原類字段。它可以調用 in.defaultReadObject 來調用默認機制,以還原對象的非靜態和非瞬態字段。defaultReadObject 方法使用流中的信息來分配流中通過當前對象中相應命名字段保存的對象的字段。這用於處理類發展後需要添加新字段的情形。
序列化操作不寫出沒有實現 java.io.Serializable 接口的任何對象的字段。不可序列化的 Object 的子類可以是可序列化的。在此情況下,不可序列化的類必須有一個無參數構造方法,以便允許初始化其字段。在此情況下,子類負責保存和還原不可序列化的類的 狀態。經常出現的情況是,該類的字段是可訪問的(public、package 或 protected),或者存在可用來還原狀態的 get 和 set 方法。
實現 writeObject 和 readObject 方法可以阻止對象的序列化,這時拋出 NotSerializableException。ObjectOutputStream 導致發生異常並中止序列化進程。
實現 Externalizable 接口允許對象假定可以完全控制對象的序列化形式的內容和格式。調用 Externalizable 接口的方法(writeExternal 和 readExternal)來保存和恢復對象的狀態。通過類實現時,它們可以使用 ObjectOutput 和 ObjectInput 的所有方法讀寫它們自己的狀態。對象負責處理出現的任何版本控制。
Enum 常量的序列化不同於普通的 serializable 或 externalizable 對象。enum 常量的序列化形式只包含其名稱;常量的字段值不被傳送。爲了序列化 enum 常量,ObjectOutputStream 需要寫入由常量的名稱方法返回的字符串。與其他 serializable 或 externalizable 對象一樣,enum 常量可以作爲序列化流中後續出現的 back 引用的目標。用於序列化 enum 常量的進程不可定製;在序列化期間,由 enum 類型定義的所有類特定的 writeObject 和 writeReplace 方法都將被忽略。類似地,任何 serialPersistentFields 或 serialVersionUID 字段聲明也將被忽略,所有 enum 類型都有一個 0L 的固定的 serialVersionUID。
基本數據(不包括 serializable 字段和 externalizable 數據)以塊數據記錄的形式寫入 ObjectOutputStream 中。塊數據記錄由頭部和數據組成。塊數據部分包括標記和跟在部分後面的字節數。連續的基本寫入數據被合併在一個塊數據記錄中。塊數據記錄的分塊因子爲 1024 字節。每個塊數據記錄都將填滿 1024 字節,或者在終止塊數據模式時被寫入。調用 ObjectOutputStream 方法 writeObject、defaultWriteObject 和 writeFields 最初只是終止所有現有塊數據記錄。
將對象寫入流時需要指定要使用的替代對象的可序列化類,應使用準確的簽名來實現此特殊方法:
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException;
此 writeReplace 方法將由序列化調用,前提是如果此方法存在,而且它可以通過被序列化對象的類中定義的一個方法訪問。因此,該方法可以擁有私有 (private)、受保護的 (protected) 和包私有 (package-private) 訪問。子類對此方法的訪問遵循 java 訪問規則。
在從流中讀取類的一個實例時需要指定替代的類應使用的準確簽名來實現此特殊方法。
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException;
此 readResolve 方法遵循與 writeReplace 相同的調用規則和訪問規則。
序列化類的所有子類本身都是可序列化的。這個序列化接口沒有任何方法和域,僅用於標識序列化的語意。允許非序列化類的子類型序列化,子類型可以假定負責保存和恢復父類型的公有的、保護的和(如果可訪問)包的域的狀態。只要該類(即父類)有一個無參構造子,可初始化它的狀態,那麼子類型就可承擔上述職責;如果該類沒有無參構造函數,在這種情況下申明一個可序列化的類是一個錯誤。此錯誤將在運行時被檢測。
JSON化
UserVo src = new UserVo();
src.setName("Yaoming");
src.setAge(30);
src.setPhone(13789878978L);
UserVo f1 = new UserVo();
f1.setName("tmac");
f1.setAge(32);
f1.setPhone(138999898989L);
UserVo f2 = new UserVo();
f2.setName("liuwei");
f2.setAge(29);
f2.setPhone(138999899989L);
List<UserVo> friends = new ArrayList<UserVo>();
friends.add(f1);
friends.add(f2);
src.setFriends(friends);
// 採用Google的gson-2.2.2.jar 進行轉義:
Gson gson = new Gson();
String json = gson.toJson(src);
得到的字符串:(字節數爲153)
{“name”:“Yaoming”,“age”:30,“phone”:13789878978,“friends”:[{“name”:“tmac”,“age”:32,“phone”:138999898989},{“name”:“liuwei”,“age”:29,“phone”:138999899989}]}
Json的優點:明文結構一目瞭然,可以跨語言,屬性的增加減少對解析端影響較小。缺點:字節數過多,依賴於不同的第三方類庫。
Google ProtoBuf
protocol buffers 是google內部得一種傳輸協議,目前項目已經開源(http://code.google.com/p/protobuf/)。它定義了一種緊湊得可擴展得二進制協議格式,適合網絡傳輸,並且針對多個語言有不同得版本可供選擇。
以protobuf-2.5.0rc1爲例,準備工作:
下載源碼,解壓,編譯,安裝:
tar zxvf protobuf-2.5.0rc1.tar.gz
./configure
./make
./make install
測試:
MacBook-Air:~ ming$ protoc --version
libprotoc 2.5.0
安裝成功!進入源碼得java目錄,用mvn工具編譯生成所需得jar包,protobuf-java-2.5.0rc1.jar
(1)編寫.proto文件,命名UserVo.proto:
package serialize;
option java_package = "serialize";
option java_outer_classname="UserVoProtos";
message UserVo{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
}
(2)在命令行利用protoc 工具生成builder類:
protoc -IPATH=.proto文件所在得目錄 --java_out=java文件的輸出路徑 .proto的名稱
(3)編寫序列化代碼:
UserVoProtos.UserVo.Builder builder = UserVoProtos.UserVo.newBuilder();
builder.setName("Yaoming");
builder.setAge(30);
builder.setPhone(13789878978L);
UserVoProtos.UserVo.Builder builder1 = UserVoProtos.UserVo.newBuilder();
builder1.setName("tmac");
builder1.setAge(32);
builder1.setPhone(138999898989L);
UserVoProtos.UserVo.Builder builder2 = UserVoProtos.UserVo.newBuilder();
builder2.setName("liuwei");
builder2.setAge(29);
builder2.setPhone(138999899989L);
builder.addFriends(builder1);
builder.addFriends(builder2);
UserVoProtos.UserVo vo = builder.build();
byte[] v = vo.toByteArray();
字節數爲53
(4)反序列化:
UserVoProtos.UserVo uvo = UserVoProtos.UserVo.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
google protobuf 優點:字節數很小,適合網絡傳輸節省io,跨語言 。缺點:需要依賴於工具生成代碼。
工作機制
proto文件是對數據的一個描述,包括字段名稱,類型,字節中的位置。protoc工具讀取proto文件生成對應builder代碼的類庫。protoc xxxxx –java_out=xxxxxx 生成java類庫。builder類根據自己的算法把數據序列化成字節流,或者把字節流根據反射的原理反序列化成對象。
官方的示例:https://developers.google.com/protocol-buffers/docs/javatutorial。
proto文件中的字段類型和java中的對應關係: 
protobuf 在序列化和反序列化的時候,是依賴於.proto文件生成的builder類完成,字段的變化如果不表現在.proto文件中就不會影響反序列化,比較適合字段變化的情況。做個測試:
把UserVo序列化到文件中:
UserVoProtos.UserVo vo = builder.build();
byte[] v = vo.toByteArray();
FileOutputStream fos = new FileOutputStream(dataFile);
fos.write(vo.toByteArray());
fos.close();
爲UserVo增加字段,對應的.proto文件:
package serialize;
option java_package = "serialize";
option java_outer_classname="UserVoProtos";
message UserVo{
optional string name = 1;
optional int32 age = 2;
optional int64 phone = 3;
repeated serialize.UserVo friends = 4;
optional string address = 5;
}
從文件中反序列化回來:
FileInputStream fis = new FileInputStream(dataFile);
byte[] dstb = new byte[fis.available()];
for(int i=0;i<dstb.length;i++){
dstb[i] = (byte)fis.read();
}
fis.close();
UserVoProtos.UserVo uvo = UserVoProtos.UserVo.parseFrom(dstb);
System.out.println(uvo.getFriends(0).getName());
三種方式對比傳輸同樣的數據,google protobuf只有53個字節是最少的。結論: