




通過Rancher Kubernetes Engine運行高可用 PostgreSQL
這篇是我們關於在Kubernetes上運行PostgreSQL系列文章的其中一篇。下面是相關文章和鏈接。
- 在亞馬遜AWS Elastic Container Service for Kubernetes (EKS)
上運行高可用PostgreSQL: (https://portworx.com/postgresql-amazon-eks/) - 在微軟Azure Kubernetes Service (AKS) 上運行高可用 PostgreSQL:
(https://portworx.com/ha-postgresql-azure-aks/) - 在Google Kubernetes Engine (GKE) 上運行高可用 PostgreSQL:
(https://portworx.com/run-ha-postgresql-gke/) - 在RedHat OpenShift 上運行高可用 PostgreSQL:
(https://portworx.com/run-ha-postgresql-red-hat-openshift/) - 在IBM Cloud Kubernetes Service (IKS) 上運行高可用 PostgreSQL:
(https://portworx.com/run-ha-postgresql-ibm-cloud-kubernetes-service/) - 在IBM 私有云上運行高可用 PostgreSQL:
(https://portworx.com/run-ha-postgresql-ibm-cloud-private/)
Rancher Kubernetes Engine (RKE)是一個輕量級的Kubernetes 安裝程序,支持在裸金屬和虛擬機上安裝Kubernetes。RKE解決了Kubernetes安裝的複雜性問題。通過RKE安裝是比較簡單的,而跟下層的操作系統無關。
Portworx是一個雲原生的存儲和數據管理平臺,來支撐Kubernetes上持久性的工作負載。通過Portworx,用戶能夠管理不同基礎架構上的、不同容器調度器上的數據庫。它爲所有的有狀態服務(Stateful Service)提供了一個單一的數據管理層。
本文列出了操作步驟:通過RancherKubernetes Engine (RKE),在AWS的Kubernetes集羣上,部署和管理高可用PostgreSQL集羣。
總結來說,在Amazon上運行高可用PostgreSQL,需要:
- 通過Rancher KubernetesEngine安裝一個Kubernetes集羣
- 安裝雲原生存儲解決方案Portworx,作爲Kubernetes的一個DaemonSet。
- 建立一個存儲類來定義你的存儲要求,比如,複製因子,快照策略和性能情況
- 使用Kubernetes部署PostgreSQL
- 通過killing或者cordoning集羣中的節點,來測試故障恢復
- 可能的話,動態的調整PG Volume的大小,快照和備份Postgres到S3
如何通過RKE來創建一個Kubernetes集羣
RKE是一個安裝和配置Kubernetes的工具。可以支持的環境包括裸金屬,虛擬機或者IaaS。在本文中,我們會在AWS EC2上創建一個3節點的Kubernetes集羣。
更爲詳細的步驟,可以參考這篇tutorial from The New Stack. (https://thenewstack.io/run-stateful-containerized-workloads-with-rancher-kubernetes-engine-and-portworx/)
做完這些操作,我們會創建一個1 master 和 3 worker 節點的集羣。
在Kubernetes上安裝Portworx
在RKE的Kubernetes 上安裝Portworx,跟在Kubernetes集羣上通過Kops安裝沒什麼不同。Portworx有詳細的文檔,列出每步的操作 (https://docs.portworx.com/portworx-install-with-kubernetes/cloud/aws/),來完成在AWS環境的Kubernetes上運行Portworx集羣。
The New Stacktutorial(https://thenewstack.io/run-stateful-containerized-workloads-with-rancher-kubernetes-engine-and-portworx/) 也包含了在Kubernetes部署Portworx DaemonSet的所有操作步驟。
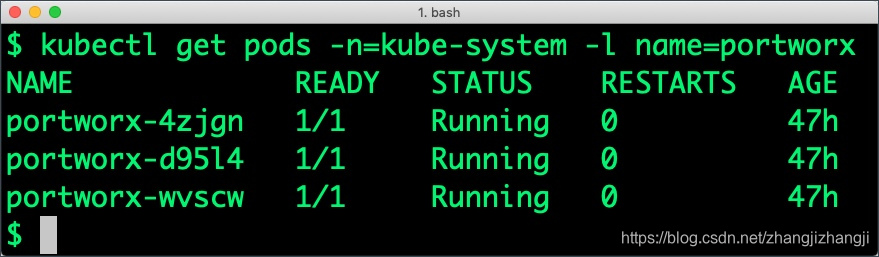
Kubernetes集羣運行起來,Portworx安裝和配置完成,我們就開始部署一個高可用的PostgreSQL數據庫。
創建一個Postgres 存儲類
通過存儲類對象,一個Admin可以定義集羣中不同的Portworx卷的類。這些類在動態的卷的部署過程中會被用到。存儲類本身定義了複製因子,IO情況(例如數據庫或者CMS),以及優先級(比如SSD或者HDD)。這些參數影響着工作負載的可用性和輸出,因此參數可以被根據每個卷分別設置。這很重要,因爲對生產系統的數據庫的要求,跟研發測試系統是完全不一樣的。
在下面的例子裏,我們部署的存儲類,它的複製因子是3,IO情況設定成“db”,優先級設定成“high”。這意味着存儲會被優化爲適合低傳輸速率的數據庫負載(Postgres),並且自動的部署在集羣具備最高性能的存儲裏。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-repl3-sc.yaml
storageclass "px-repl3-sc" created創建一個Postgres PVC
我們現在可以基於存儲類創建一個PersistentVolume Claim (PVC)。動態部署的優勢就在於,claims能夠在不需要顯性部署持久卷Persistent Volume (PV)的情況下被創建。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-postgres-pvc.yaml
persistentvolumeclaim "px-postgres-pvc" createdPostgreSQL的密碼會被創建成Secret。運行下面的命令來用正確的格式創建Secret。
$ echo postgres123 > password.txt
$ tr -d '\n' .strippedpassword.txt && mv .strippedpassword.txt password.txt
$ kubectl create secret generic postgres-pass --from-file=password.txt
secret "postgres-pass" created在Kubernetes上部署PostgreSQL
最後,讓我們創建一個PostgreSQL實例,作爲一個Kubernetes部署對象。爲了簡單起見,我們只部署一個單獨的Postgres Pod。因爲Portworx提供同步複製來達到高可用。因此一個單獨的Postgres實例,是Postgres數據庫的最佳部署方式。Portworx也支持多節點的Postgres部署方式,看你的需要。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/postgres-app.yaml
deployment "postgres" created確保Postgres的Pods是在運行的狀態。
$ kubectl get pods -l app=postgres -o wide --watch
等候直到Postgres pod變成運行狀態。

我們可以通過使用與PostgresPod一起運行的pxctl工具,來檢查Portworx卷。
$ VOL=`kubectl get pvc | grep px-postgres-pvc | awk '{print $3}'`
$ PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
$ kubectl exec -it $PX_POD -n kube-system -- /opt/pwx/bin/pxctl volume inspect ${VOL}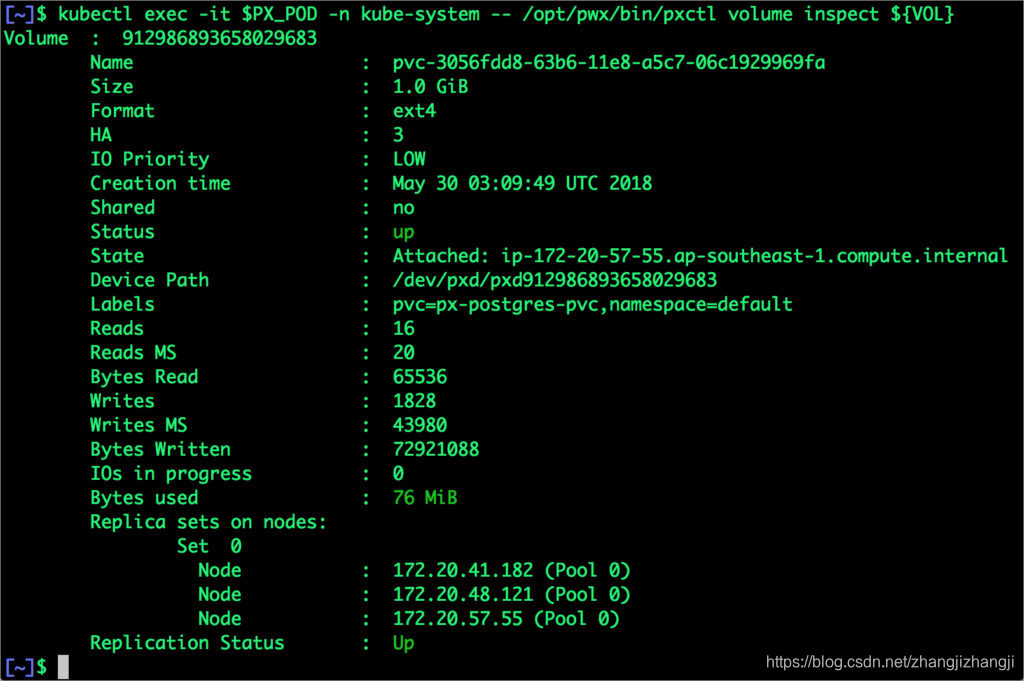
命令的輸出信息,確認了支撐PostgreSQL數據庫實例的卷已經被創建完成了。
PostgreSQL的錯誤恢復
讓我們爲數據庫填充5百萬行的樣例數據。
我們首先找到運行PostgreSQL的Pod,來訪問shell。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`
$ kubectl exec -it $POD bash現在我們進入了Pod,我們能夠連接到Postgres並且創建數據庫。
# psql
pgbench=# create database pxdemo;
pgbench=# \l
pgbench=# \q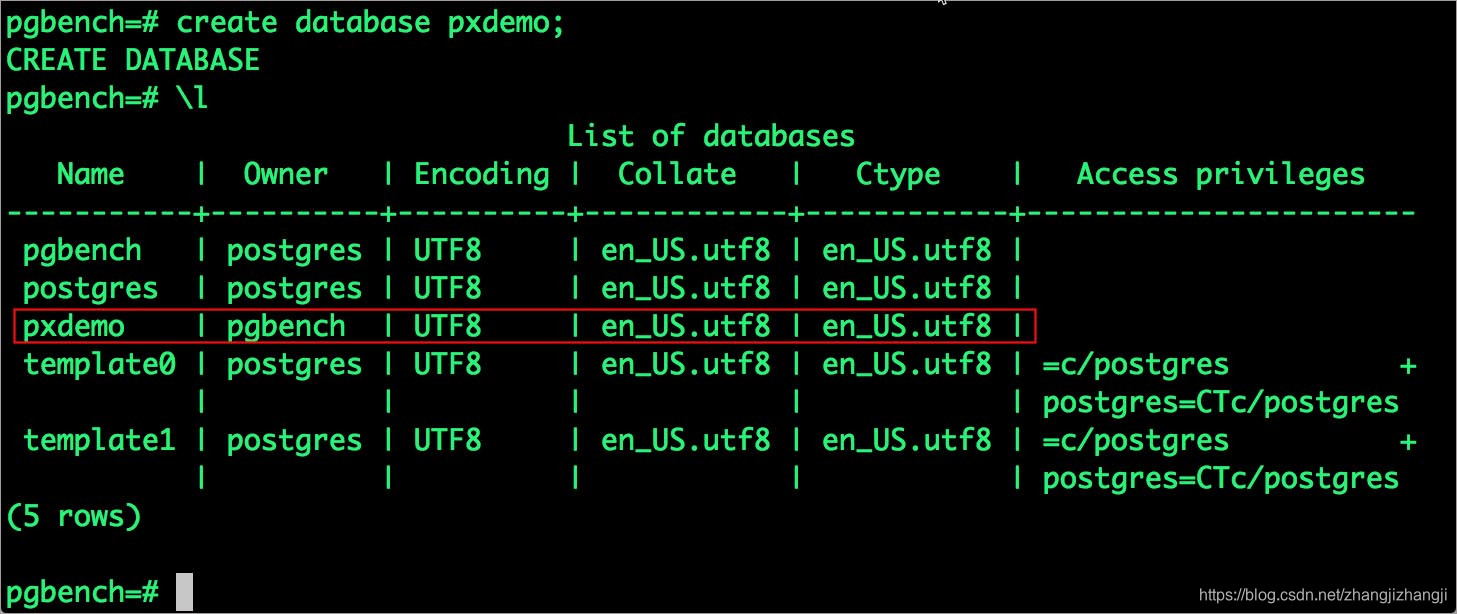
默認狀態下,Pgbench會創建4張表:(pgbench_branches,pgbench_tellers,pgbench_accounts,pgbench_history),在主pgbench_accounts表裏會有10萬行。這樣我們創建了一個簡單的16MB大小的數據庫。
使用-s選項, 我們可以增加在每張表中的行的數量。在上面的命令中,我們在“scaling”上填寫了50,這樣pgbench就會創建一個50倍默認大小的數據庫。
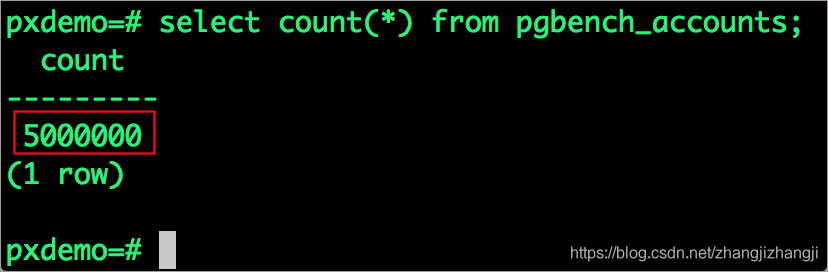
我們的pgbench_accounts現在有5百萬行了。這樣我們的數據庫變成了800MB (50*16MB)
# pgbench -i -s 50 pxdemo;等待直到pgbench完成表的創建。我們接着來確認一下
pgbench_accounts現在有500萬行的填充。
# psql pxdemo
\dt
select count(*) from pgbench_accounts;
\q
exit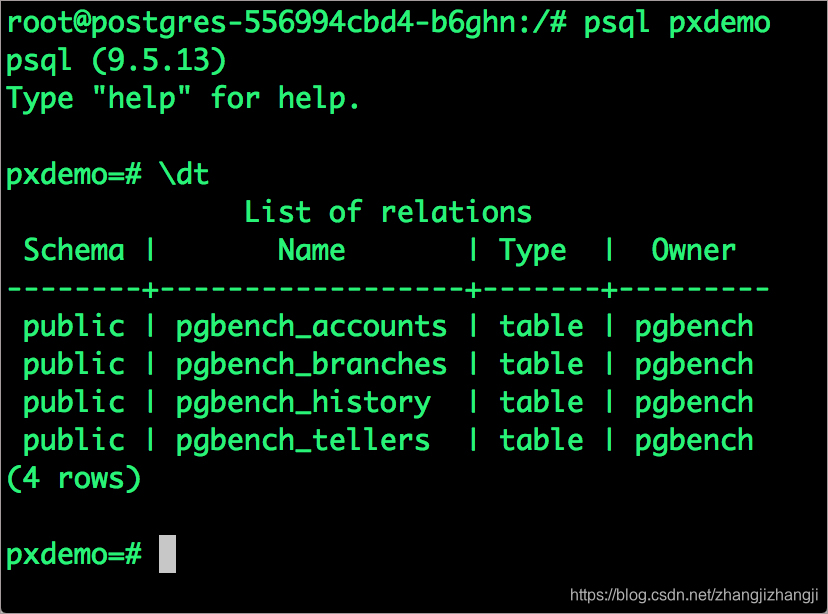
現在,我們來模擬PostgreSQL正在運行的節點的失效,
$ NODE=`kubectl get pods -l app=postgres -o wide | grep -v NAME | awk '{print $7}'`
$ kubectl cordon ${NODE}
node "ip-172-20-57-55.ap-southeast-1.compute.internal" cordoned執行kubectl get nods, 確認了其中一個節點的排程已經失效了。
$ kubectl get nodes
我們繼續刪除這個PostgreSQLpod。
$ POD=`kubectl get pods -l app=postgres -o wide | grep -v NAME | awk '{print $1}'`
$ kubectl delete pod ${POD}
pod "postgres-556994cbd4-b6ghn" deleted一旦刪除完成。Portworx STorageORchestrator for Kubernetes (STORK)(https://portworx.com/stork-storage-orchestration-kubernetes/),會把pod重置來創建有數據複製集的節點。
一旦Pod被刪除,它會被重置到有數據複製集的節點上。Portworx STorageORchestrator for Kubernetes (STORK) (https://portworx.com/stork-storage-orchestration-kubernetes/)- Portworx的客戶存儲排程器,允許在數據所在節點上放置多個pod,並且確保正確的節點能夠被選擇來用來排程Pod。
讓我們運行下面的命令驗證一下。我們會發現一個新的pod被創建了,並且被排程在了一個不同的節點上。
$ kubectl get pods -l app=postgres
讓我們把之前的節點重新部署回來。
$ kubectl uncordon ${NODE}
node "ip-172-20-57-55.ap-southeast-1.compute.internal" uncordoned最後,我們驗證一下數據仍然是可用的。
我們來看下容器裏的pod名稱和exec。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`
$ kubectl exec -it $POD bash現在用psql來確保我們的數據還在。
# psql pxdemo
pxdemo=# \dt
pxdemo=# select count(*) from pgbench_accounts;
pxdemo=# \q
pxdemo=# exit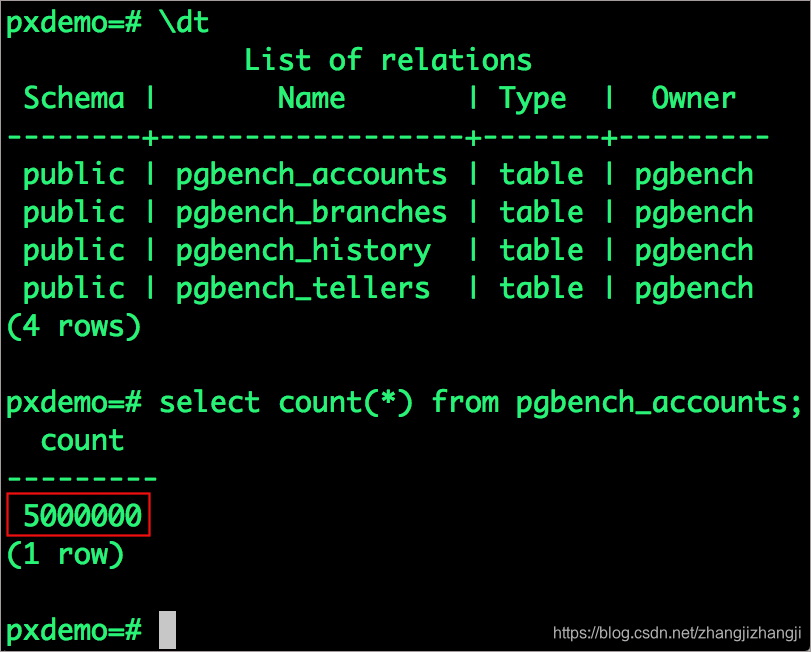
我們看到數據庫表都還在,並且所有的內容都是正確的。
在Postgres進行存儲管理
測試了端到端的數據庫錯誤恢復後,我們在Kubernetes集羣上來運行StorageOps。
完全無停機下,擴充卷
我們現在來演示一下,在空間將滿的情況下,如何簡單的、動態的爲卷添加空間。
在容器內打開一個shell,
$ POD=`kubectl get pods -l app=postgres | grep Running | awk '{print $1}'`
$ kubectl exec -it $POD bash讓我們來用pgbench來運行一個baseline transaction benchmark,它將嘗試增加捲容量到1Gib,並且沒能成功。
$ pgbench -c 10 -j 2 -t 10000 pxdemo
$ exit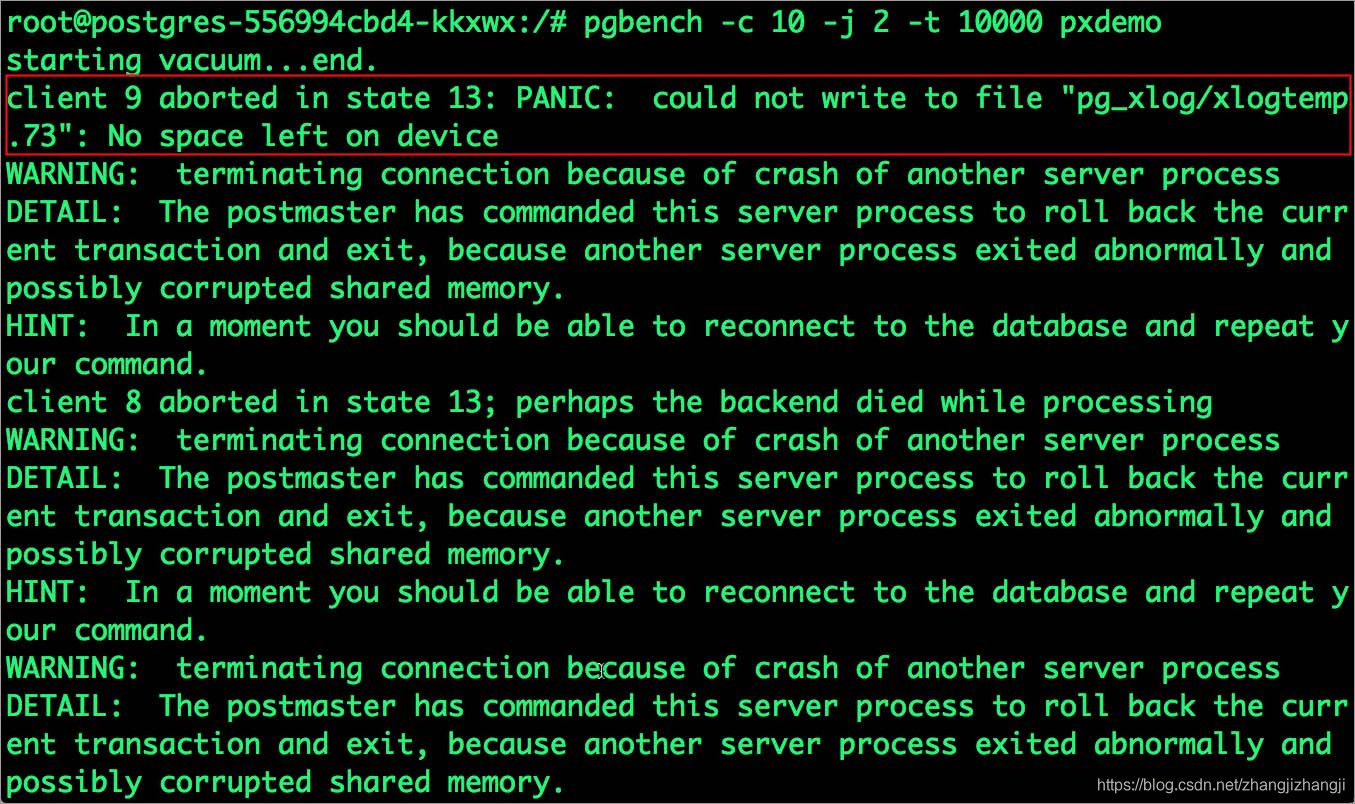
在運行上面命令的時候,可能會有多種錯誤產生。第一個錯誤提示Pod已經沒有空間了。
PANIC: could not write to file "pg_xlog/xlogtemp.73": No space left on deviceKubernetes並不支持在PVC創建後進行修改。我們在Portworx上用pxctl CLI工具來進行操作。
我們來獲取卷的名稱,用pxctl工具來查看。
SSH到節點裏,運行下面的命令
POD=`/opt/pwx/bin/pxctl volume list --label pvc=px-postgres-pvc | grep -v ID | awk '{print $1}'`
$ /opt/pwx/bin/pxctl v i $POD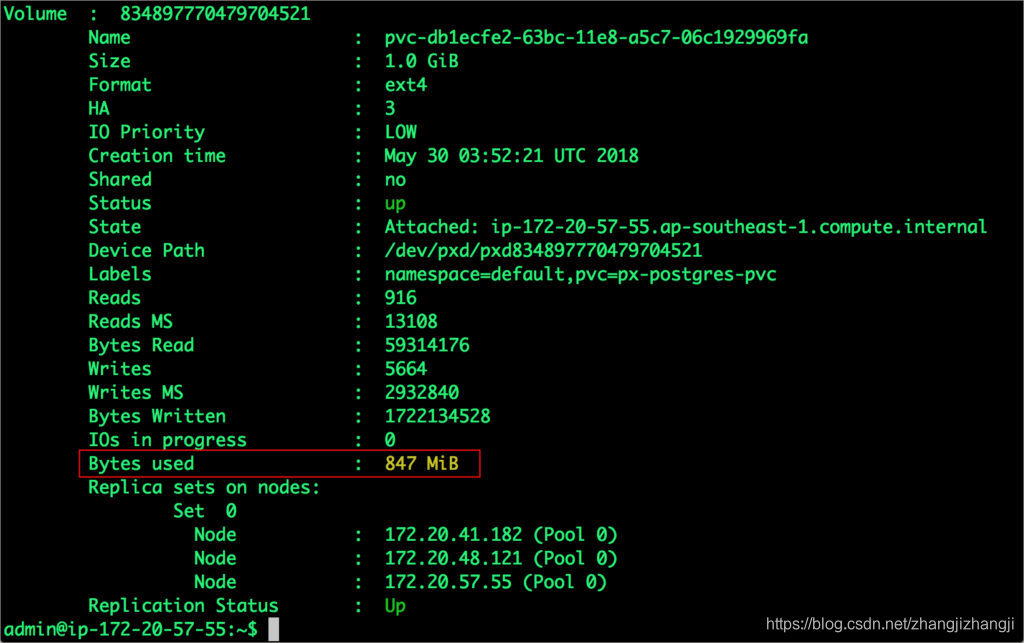
注意到卷還有10%就要滿了。讓我們用下面的命令來擴充。
$ /opt/pwx/bin/pxctl volume update $POD --size=2
Update Volume: Volume update successful for volume 834897770479704521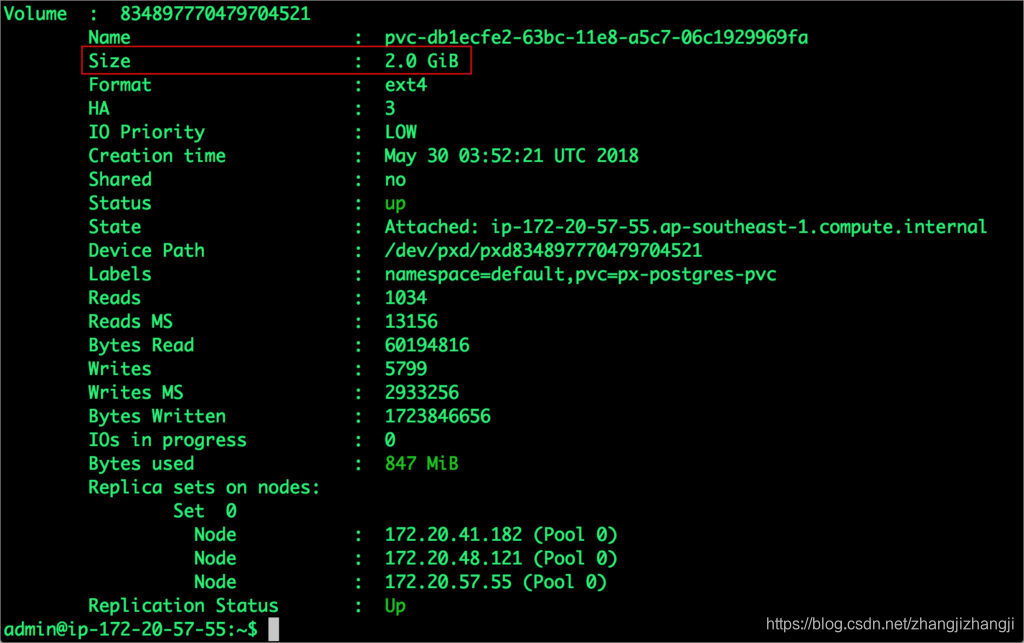
爲卷做快照,並且恢復數據庫
Portworx支持爲Kubernetes PVCs創建快照。讓我們爲之前創建的Postgres PVC來創建一個快照。
$ kubectl create -f https://github.com/fmrtl73/katacoda-scenarios-1/raw/master/px-k8s-postgres-all-in-one/assets/px-snap.yaml
volumesnapshot "px-postgres-snapshot" created可以通過下面的命令來看所有的快照。
$ kubectl get volumesnapshot,volumesnapshotdata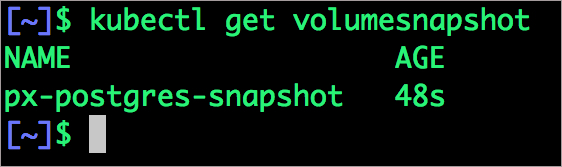

有了快照,我們來刪掉數據庫。
$ POD=`kubectl get pods -l app=postgres | grep Running | grep 1/1 | awk '{print $1}'`
$ kubectl exec -it $POD bash
$ psql
drop database pxdemo;
\l
\q
exit快照就跟卷是一樣的,我們可以使用它來創建一個新的PostgreSQL實例。讓我們恢復快照數據,來創建一個新的PostgreSQL實例。
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/px-snap-pvc.yaml
persistentvolumeclaim "px-postgres-snap-clone" created從新的PVC,我們創建一個PostgreSQL Pod,
$ kubectl create -f https://raw.githubusercontent.com/fmrtl73/katacoda-scenarios-1/master/px-k8s-postgres-all-in-one/assets/postgres-app-restore.yaml
deployment "postgres-snap" created確認這個pod是在運行狀態。
$ kubectl get pods -l app=postgres-snap
最後,讓我們訪問由benchmark工具創建的數據。
$ POD=`kubectl get pods -l app=postgres-snap | grep Running | grep 1/1 | awk '{print $1}'`
$ kubectl exec -it $POD bash$ psql pxdemo
\dt
select count(*) from pgbench_accounts;
\q
exit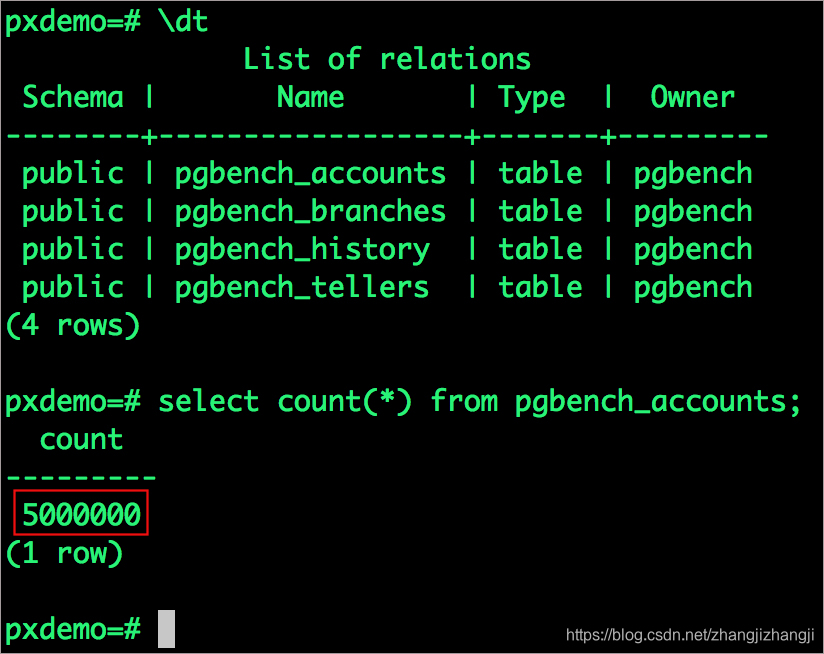
我們發現表和數據都是正常的。如果我們想要在另一個Amazon區域創建一個容災備份,我們可以把快照推送到Amazon S3。Portworx快照支持所有的S3兼容存儲對象,所以備份也可以是其他的雲或者是本地部署的數據中心。
_
小結
Portworx可以通過RKE很容易的部署,用來運行Kubernetes上生產系統中有狀態的工作負載。通過跟STORK的整合,DevOps和StorageOps團隊能夠無縫的在Kubernetes上運行數據庫集羣。他們也可以爲雲原生應用運行傳統的操作,比如擴充卷,快照,備份,容災恢復。