




這篇博文是在總結網易公開課上ng的機器學習第二講和周志華老師書上線性迴歸的個人總結。準備做一個系列筆記,希望能堅持。
代碼放在文後
什麼是線性模型
通俗一點來講,就是我們希望用一個線性組合,來擬合我們的數據,實質上是求解輸入到輸出的一個線性函數的映射。當然非線性映射也是有的,比如對數線性迴歸。線性模型一半是監督學習。本文中講的線性迴歸模型就是的。
線性模型可以幹什麼呢?線性模型有常見的線性迴歸,對數迴歸等等,他們可以用在數據的預測上,邏輯迴歸可以用在分類上。
線性模型的一般表達式:
線性迴歸模型
首先解釋一下“迴歸”二字的意思,周志華老師在其書《機器學習》(下文用“書中”代指)中講到:若預測的值是離散的,例如好人,壞人;得病,不得病,這種稱爲分類(classification);如預測的是連續值,我們稱之爲迴歸(regression)。顯然線性問題是一個連續的,所以我們稱之爲線性迴歸(正誤可以勘正)。
線性迴歸假定給定數據集D = {(x1,y1),(x2,y2)...,(xn,yn)},線性迴歸試圖學習一個線性模型儘可能的預測實際值的輸出。我們用h表示模型的預測輸出值。那麼h的表達式如下:
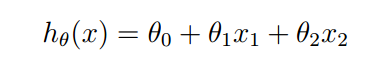
用向量表示就是我們常見的形式:

其中x1,x2…xn是我們的樣本數據,x1表示x1這個特徵,h(x)表示預測函數(hypotheses h)theta表示每一個特徵的權重,注意theta0是線性函數的縱截距,x0 = 1. n表示輸入特徵的個數.
在這個模型中。w是未知的,我們稱之爲參數。線性迴歸的模型求解就是計算出theta。
回想一下,我們的h是一個假設值,真是的函數值是y,我們的目標是想用假設的y來代替y,所以我們的目標其實是如何讓h最大限度的趨近與y。爲了達到這個目的,我們定義了個一個稱之爲損失函數的函數(cost function)定於如下:

此時,我們的目標是如何讓j最小。以達到全局最優的解。讓我們好好看看這個cost function,它的sigma裏面其實是一個最小二乘(least squares)。所以,線性迴歸模型中求解最優值的過程中,使用到了最小二乘算法來進行參數估計。在線性迴歸中,最小二乘就是試圖找到一條直線,是的所有樣本到直線上的歐氏距離之和最小。下面我們來看看如何求的在J取得最小值的時候h的取值,間接的也就求出了theta的值。
爲了求解,我們採用梯度下降算法來描述這個過程。選定初始的w,然後不斷的進行學習更新w,達到最優的解
更新規則如下:

這裏的alpha 稱爲學習率。
我們推導偏導數考慮值只對一個樣本,偏導數如下:

將其帶入到公式()中,得到一次更新規則如下:

那麼對於所有的樣本,有如下算法:

上面這個方法被稱爲batch gradent descent的線性迴歸問題求解。我們看到其每次循環需要對所有的樣本進行計算(sigma)如果樣本很大的時候,那麼計算的次數將會很大,所以這個算法並不適合大樣本的學習。
爲了使其能在大樣本下依舊完美工作,將算法進行改進:

這個算法的稱之爲stochastic gradient descent(incremental gradient descent).
還有一個用矩陣來求解的過程,具體就不寫了,直接給出結果

聲明:公式來自NG的講義
實現
筆者用java實現了三種geadient descent 算法, 代碼如下:
package com.dmml.linear;
/**
* Created by macan on 2016/10/12.
*/
import java.util.ArrayList;
/**
* 梯度下降算法求解線性迴歸模型
* 1. batch gradient descent
* 2. stochastic gradient descent
* 3. gradient descent by matrix
*
* 假設: 特殊是N維的, 結果是一維的
*
*/
public class GradientDescent {
public final static int maxIterator = 1000;
/**
* 學習data set
*/
private ArrayList<int[]> trainData;
/**
*
*/
private ArrayList<Integer> targetData;
/**
* learning rate
*/
private static double alpha = 0.00001;
/**
* 特徵的維度
*/
private int N;
/**
* 樣本的個數
*/
private int M;
/**
* theta 參數
* double
*/
private double[] theta;
/**
* 構造方法
* @param trainData 訓練數據集
* @param testData 測試數據集
*/
public GradientDescent(ArrayList<int[]> trainData, ArrayList<Integer> testData){
this.trainData = trainData;
this.targetData = testData;
M = trainData.size();
N = trainData.get(1).length;
//初始化theta
theta = new double[N];
}
/**
* batch gradient descent algorithm
*/
public void batchGradientDescent(){
//計算
//迭代,設置最大的迭代次數爲1000
for (int n = 0; n < maxIterator; ++n) {
for (int i = 0; i < N; ++i){
double temp = batchOndGradient(i);
if (temp <0.001){
break;
}
theta[i] += temp;
}
}
}
/**
* stochastic gradient descent
*/
public void stochasticGradientDescent(){
//計算
//迭代,設置最大的迭代次數爲1000
for (int n = 0; n < maxIterator; ++n) {
//for each feature
for (int i = 0; i < N; ++i){
//for each row data
for (int m = 0; m < M; ++m) {
theta[i] += stochasticOneGradient(m,i);
}
}
}
}
/**
* 利用矩陣的思路,來解決gradient descent
*/
public void matrixInGradientDescet(){
double[][] train = toArray(trainData);
double[][] target = toArray2(targetData);
double[][] x1 = Matrix.trans(train);
//計算
double[][] res = Matrix.times(Matrix.times(Matrix.inv(Matrix.times(x1, train)), x1), target);
for (int i = 0; i < res.length; ++i){
for (int j = 0; j <res[i].length; ++j){
theta[i] = res[i][j];
}
}
}
/**
* 計算sigma(y - h(x))x(i,j)
* @param f 特徵index
* @return 返回計算的結果
*/
public double batchOndGradient(int f) {
double result = 0.0;
double temp = 0.0;
for (int m = 0; m < M; ++m) {
//計算h(x)
double hx = 0.0;
int[] X = trainData.get(m);
for (int i = 0; i < N; ++i) {
hx += theta[i] * X[i];
}
//計算(h - hx) * x
temp += (targetData.get(m) - hx) * X[f];
}
return alpha * temp;
}
public double stochasticOneGradient(int m, int f){
double result = 0.0;
double temp = 0.0;
//計算h(x)
double hx = 0.0;
int[] X = trainData.get(m);
for (int i = 0; i < N; ++i) {
hx += theta[i] * X[i];
}
//計算(h - hx) * x
return alpha * ((targetData.get(m) - hx) * X[f]);
}
public static double[][] toArray(ArrayList<int[]> data){
double[][] res = new double[data.size()][data.get(1).length];
for (int i = 0;i < data.size(); ++i){
for (int j = 0; j < data.get(i).length; ++j){
res[i][j] = (double)data.get(i)[j];
}
}
return res;
}
public static double[][] toArray2(ArrayList<Integer> data){
double[][] res = new double[data.size()][1];
for (int i = 0;i < data.size(); ++i){
res[i][0] = data.get(i).doubleValue();
}
return res;
}
public void print(){
for (int i = 0; i < theta.length; ++i){
System.out.print("theta" + i + " = " + theta[i]);
}
System.out.println();
}
public void initTheta(){
for (int i = 0; i < N; ++i){
theta[i] = 0.0;
}
}
public double[] getTheta(){
return theta;
}
}
測試代碼:
@Test
public void testGradientDescent(){
int N = 4;
int M = 300;
ArrayList<int[]> data = createDataSet(N, M);
ArrayList<int[]> train = new ArrayList<int[]>();
ArrayList<Integer> test = new ArrayList<Integer>();
for (int[] sub : data){
int[] t = new int[N];
for (int i = 0; i < N; ++i){
t[i] = sub[i];
}
train.add(t);
test.add(new Integer(sub[N]));
}
//System.out.println(data);
GradientDescent gradientDescent = new GradientDescent(train, test);
System.out.println("batch Gradient descent...");
gradientDescent.batchGradientDescent();
gradientDescent.print();
double[] th1 = gradientDescent.getTheta();
System.out.println("stochastic Gradient Descent");
GradientDescent sgd = new GradientDescent(train, test);
sgd.stochasticGradientDescent();
sgd.print();
double th2[] = sgd.getTheta();
System.out.println("matrix In Gradient Descet");
GradientDescent mgd = new GradientDescent(train, test);
mgd.matrixInGradientDescet();
mgd.print();
double[] th3 = mgd.getTheta();
saveData(data, th1, th2, th3);
}
public void saveData(ArrayList<int[]> data, double[] th1, double[] th2, double[] th3)
{
String path = "data.txt";
try {
BufferedWriter writer = new BufferedWriter(new FileWriter(new File(path)));
for (int[] rows : data){
for (int i = 0; i< rows.length; ++i){
writer.write(rows[i] + "\t");
}
writer.write("\n");
}
for (int i = 0; i < th1.length; ++i){
writer.write("theta" + i + " = " + th1[i] + "\t");
}
writer.write("\n");
for (int i = 0; i < th2.length; ++i){
writer.write("theta" + i + " = " + th2[i] + "\t");
}
writer.write("\n");
for (int i = 0; i < th3.length; ++i){
writer.write("theta" + i + " = " + th3[i] + "\t");
}
writer.write("\n");
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}運行結果如下:

用矩陣這種運算的時候,截距算的很大,這個原因我也不知道爲啥,如果用童鞋看出來,請指教。

