




1、直接插入排序(direct Insert Sort),基本思想是:順序地將待排序的記錄按其關鍵碼的大小插入到已排序的記錄子序列的適當位置。子序列的記錄個數從1 開始逐漸增大,當子序列的記錄個數與順序表中的記錄個數相同時排序完畢。
public void InsertSort(SeqList<int> sqList)
{for (int i = 1; i < sqList.Last; ++i) //假設第一個數據i=0是最小的,所以i是從1開始
{
if (sqList[i] < sqList[i - 1]) //依次判斷I與前面的數據那個小,
{
int tmp = sqList[i]; //用tmp暫時保存當前小的數據
int j = 0;
for (j = i - 1; j >= 0&&tmp<sqList[j]; --j) //循環判斷已經排序中的數據大小與當前的tmp比較
{
sqList[j + 1] = sqList[j]; //如果某個已經排序好的數據比tmp大,則讓已經排序好的數據後移一位空一個位置
}
sqList[j + 1] = tmp; //這時候就讓空出的那個位置放入tmp
}
}
}
2、冒泡排序(Bubble Sort),基本思想是:將相鄰的記錄的關鍵碼進行比較,若前面記錄的關鍵碼大於後面記錄的關鍵碼,則將它們交換,否則不交換。
public void BubbleSort(SeqList<int> sqList)
{
int tmp; //用於兩個數據交換用
for (int i = 0; i < sqList.Last; ++i) //這層循環是用於冒泡排序需要循環n-1次
{
for (int j = sqList.Last - 1; j >= i; --j) //從後向前依次比較出最小的
{
if (sqList[j + 1] < sqList[j]) //把小的很前面大的交換數據
{
tmp = sqList[j + 1];
sqList[j + 1] = sqList[j];
sqList[j] = tmp;
}
}
}
}
3、簡單選擇排序(Simple Select Sort),算法的基本思想是:從待排序的記錄序列中選擇關鍵碼最小(或最大)的記錄並將它與序列中的第一個記錄交換位置;然後從不包括第一個位置上的記錄序列中選擇關鍵碼最小(或最大)的記錄並將它與序列中的第二個記錄交換位置;如此重複,直到序列中只剩下一個記錄爲止。
public void SimpleSelectSort(SeqList<int> sqList)
{
int tmp = 0; //用於數據交換
int t = 0; //用於記錄當比較中最小數的index
for (int i = 0; i < sqList.Last; ++i)
{
t = i;
for (int j = i + 1; j <= sqList.Last; ++j) //循環比較找出最小數的index
{
if (sqList[t] > sqList[j]) //判斷兩個數中哪個數最小
{
t = j; //讓最小的index等於t
}
}
tmp = sqList[i]; 讓最小的數和當前總排序中最小index的數交換位置
sqList[i] = sqList[t];
sqList[t] = tmp;
}
}
4、快速排序(Quick Sort),基本思想是:通過不斷比較關鍵碼,以某個記錄爲界(該記錄稱爲支點) ,將待排序列分成兩部分。其中,一部分滿足所有記錄的關鍵碼都大於或等於支點記錄的關鍵碼,另一部分記錄的關鍵碼都小於支點記錄的關鍵碼。把以支點記錄爲界將待排序列按關鍵碼分成兩部分的過程,稱爲一次劃分。對各部分不斷劃分,直到整個序列按關鍵碼有序爲止。
public void QuickSort(SeqList<int> sqList, int low, int high)
{
int i = low; //定義低的一端爲low
int j = high; //高的一端爲hight
int tmp = sqList[low]; //temp爲基數
while (low < high) //判斷高低端是否重合,如果重合說明已經排序完成
{
while ((low < high) && (sqList[high] >= tmp)) //如果高端的數大於基數,則繼續往左檢索直到檢索出小於基數的數
{
--high;
}
sqList[low] = sqList[high]; //如果小於基數,則讓這個低的數放入低端指向
++low; //低端向右移動一位
while ((low < high) && (sqList[low] <= tmp)) //判斷低端的數是否小於基數,如果小於則繼續向右檢索直到檢索出大於
{
++low;
}
sqList[high] = sqList[low]; //讓大於基數的這個數放入高端
--high;
}
sqList[low] = tmp; //檢索完畢,把基數放入空位處
if (i < low-1)
{
QuickSort(sqList, i, low-1); //檢索完畢後,如果基數左側還有數,則遞歸重新檢索基數左側
}
if (low+1 < j)
{
QuickSort(sqList, low+1, j); //檢索完畢後,如果基數右側還有數,則遞歸重新檢索基數右側
}
}
}
5、堆排序,堆分爲最大堆和最小堆兩種。最大堆的定義如下: 設順序表sqList中存放了n個記錄,對於任意的i(0≤i≤n-1),如果2i+1<n時有 sqList[i]的關鍵碼不小於 sqList[2i+1]的關鍵碼;如果 2i+2<n 時有sqList[i] 的關鍵碼不小於 sqList[2i+2] 的關鍵碼,則這樣的堆爲最大堆。 如果把這 n 個記錄看作是一棵完全二叉樹的結點,則 sqList[0]對應完全二
叉樹的根,sqList[1]對應樹根的左孩子結點,sqList[2]對應樹根的右孩子結點,sqList[3]對應 sqList[1]的左孩子結點,sqList[4]對應 sqList[2]的右孩子結點,如此等等。在此基礎上,只需調整所有非葉子結點滿足:sqList[i] 的關鍵碼不小於 sqList[2i+1] 的關鍵碼和 sqList[i] 的關鍵碼不小於 sqList[2i+2] 的關鍵碼,則這樣的完全二叉樹就是一個最大堆。
public void CreateHeap(SeqList<int> sqList, int low, int high) //low爲數組最小index,high爲數組長度
{
if ((low < high) && (high <= sqList.Last))
{
int j = 0;
int tmp = 0; //用於存放父節點的值
int k = 0;
for (int i = high / 2; i >= low; --i) //i爲二叉樹最下方的葉子結點的父節點(當前選中的父節點)
{
k = i; //當前的父節點
j = 2 * k + 1; //當前的左孩子
tmp = sqList[i]; //tmp存放父節點的值
while (j <= high)
{
if ((j < high) && (j + 1 <= high) && (sqList[j] < sqList[j + 1])) //判斷有沒有右孩子,如果有則比較左右孩子的值,把大的值大的值賦值給J
{
++j;
}
if (tmp < sqList[j]) 判斷父節點的值與孩子節點的值那個大,如果孩子節點的大則把孩子節點的值給父節點,繼續往下查找,值大的孩子節點爲父節點
{
sqList[k] = sqList[j];
k = j;
j = 2 * k + 1;
}
else //跳出循環
{
j = high + 1;
}
}
sqList[k] = tmp; //最初父節點的值給最後(n)孩子節點,n爲第n次比較後的孩子節點
}
}
}
使用
public void HeapSort(SeqList<int> sqList)
{
int tmp = 0;
CreateHeap(sqList, 0, sqList.Last); //創建最大堆
for (int i = sqList.Last; i > 0; --i) //取出堆頂元素,並重新創建最大堆,依次取出
{
tmp = sqList[0];
sqList[0] = sqList[i];
sqList[i] = tmp;
CreateHeap(sqList, 0, i-1);
}
}
6、歸併排序,
基本思想
將待排序序列R[0...n-1]看成是n個長度爲1的有序序列,將相鄰的有序表成對歸併,得到n/2個長度爲2的有序表;將這些有序序列再次歸併,得到n/4個長度爲4的有序序列;如此反覆進行下去,最後得到一個長度爲n的有序序列。
綜上可知:
歸併排序其實要做兩件事:
(1)“分解”——將序列每次折半劃分。
(2)“合併”——將劃分後的序列段兩兩合併後排序。
我們先來考慮第二步,如何合併?
在每次合併過程中,都是對兩個有序的序列段進行合併,然後排序。這兩個有序序列段分別爲 R[low, mid] 和 R[mid+1, high]。先將他們合併到一個局部的暫存數組R2中,帶合併完成後再將R2複製回R中。爲了方便描述,我們稱 R[low, mid] 第一段,R[mid+1, high] 爲第二段。每次從兩個段中取出一個記錄進行關鍵字的比較,將較小者放入R2中。最後將各段中餘下的部分直接複製到R2中。經過這樣的過程,R2已經是一個有序的序列,再將其複製回R中,一次合併排序就完成了。
public void Merge(int[] array, int low, int mid, int high) {
int i = low; // i是第一段序列的下標
int j = mid + 1; // j是第二段序列的下標
int k = 0; // k是臨時存放合併序列的下標
int[] array2 = new int[high - low + 1]; // array2是臨時合併序列
// 掃描第一段和第二段序列,直到有一個掃描結束
while (i <= mid && j <= high) {
// 判斷第一段和第二段取出的數哪個更小,將其存入合併序列,並繼續向下掃描
if (array[i] <= array[j]) {
array2[k] = array[i];
i++;
k++;
} else {
array2[k] = array[j];
j++;
k++;
}
}
// 若第一段序列還沒掃描完,將其全部複製到合併序列
while (i <= mid) {
array2[k] = array[i];
i++;
k++;
}
// 若第二段序列還沒掃描完,將其全部複製到合併序列
while (j <= high) {
array2[k] = array[j];
j++;
k++;
}
// 將合併序列複製到原始序列中
for (k = 0, i = low; i <= high; i++, k++) {
array[i] = array2[k];
}
}
int i = 0;
// 歸併gap長度的兩個相鄰子表
for (i = 0; i + 2 * gap - 1 < length; i = i + 2 * gap) {
Merge(array, i, i + gap - 1, i + 2 * gap - 1);
}
// 餘下兩個子表,後者長度小於gap
if (i + gap - 1 < length) {
Merge(array, i, i + gap - 1, length - 1);
}
}
public int[] sort(int[] list) {
for (int gap = 1; gap < list.length; gap = 2 * gap) {
MergePass(list, gap, list.length);
console.WriteLine("gap = " + gap + ":\t");
this.printAll(list);
}
return list;
}
把記錄按步長 gap 分組,對每組記錄採用直接插入排序方法進行排序。
隨着步長逐漸減小,所分成的組包含的記錄越來越多,當步長的值減小到 1 時,整個數據合成爲一組,構成一組有序記錄,則完成排序。
我們來通過演示圖,更深入的理解一下這個過程。
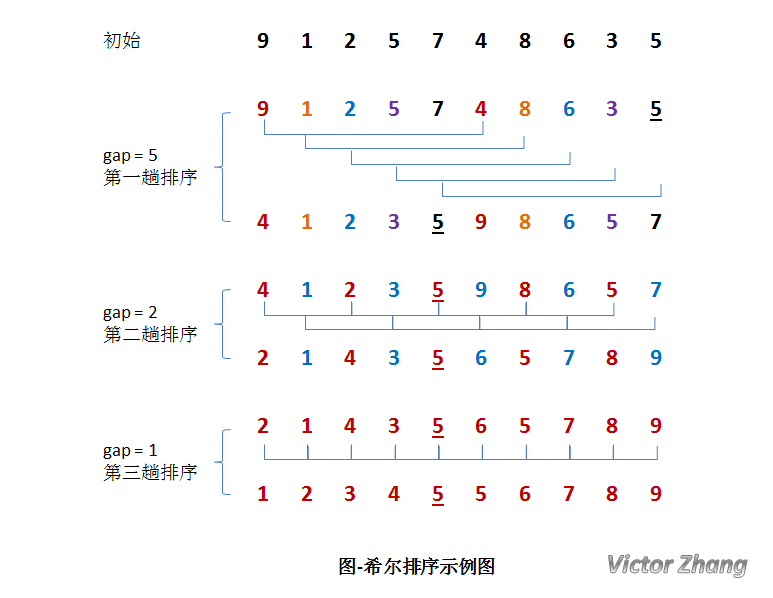
在上面這幅圖中:
初始時,有一個大小爲 10 的無序序列。
在第一趟排序中,我們不妨設 gap1 = N / 2 = 5,即相隔距離爲 5 的元素組成一組,可以分爲 5 組。
接下來,按照直接插入排序的方法對每個組進行排序。
在第二趟排序中,我們把上次的 gap 縮小一半,即 gap2 = gap1 / 2 = 2 (取整數)。這樣每相隔距離爲 2 的元素組成一組,可以分爲 2 組。
按照直接插入排序的方法對每個組進行排序。
在第三趟排序中,再次把 gap 縮小一半,即gap3 = gap2 / 2 = 1。 這樣相隔距離爲 1 的元素組成一組,即只有一組。
按照直接插入排序的方法對每個組進行排序。此時,排序已經結束。
需要注意一下的是,圖中有兩個相等數值的元素 5 和 5 。我們可以清楚的看到,在排序過程中,兩個元素位置交換了。
所以,希爾排序是不穩定的算法。
int gap = list.length / 2;
while (1 <= gap) {
// 把距離爲 gap 的元素編爲一個組,掃描所有組
for (int i = gap; i < list.length; i++) {
int j = 0;
int temp = list[i];
// 對距離爲 gap 的元素組進行排序
for (j = i - gap; j >= 0 && temp < list[j]; j = j - gap) {
list[j + gap] = list[j];
}
list[j + gap] = temp;
}
gap = gap / 2; // 減小增量
}
}
8、基數排序,它不需要比較關鍵字的大小。
它是根據關鍵字中各位的值,通過對排序的N個元素進行若干趟“分配”與“收集”來實現排序的。
不妨通過一個具體的實例來展示一下,基數排序是如何進行的。
設有一個初始序列爲: R {50, 123, 543, 187, 49, 30, 0, 2, 11, 100}。
我們知道,任何一個阿拉伯數,它的各個位數上的基數都是以0~9來表示的。
所以我們不妨把0~9視爲10個桶。
我們先根據序列的個位數的數字來進行分類,將其分到指定的桶中。例如:R[0] = 50,個位數上是0,將這個數存入編號爲0的桶中。

分類後,我們在從各個桶中,將這些數按照從編號0到編號9的順序依次將所有數取出來。
這時,得到的序列就是個位數上呈遞增趨勢的序列。
按照個位數排序: {50, 30, 0, 100, 11, 2, 123, 543, 187, 49}。
接下來,可以對十位數、百位數也按照這種方法進行排序,最後就能得到排序完成的序列。
public class RadixSort {// 獲取x這個數的d位數上的數字
// 比如獲取123的1位數,結果返回3
public int getDigit(int x, int d) {
int a[] = {
1, 1, 10, 100
}; // 本實例中的最大數是百位數,所以只要到100就可以了
return ((x / a[d]) % 10);
}
public void radixSort(int[] list, int begin, int end, int digit) {
final int radix = 10; // 基數
int i = 0, j = 0;
int[] count = new int[radix]; // 存放各個桶的數據統計個數
int[] bucket = new int[end - begin + 1];
// 按照從低位到高位的順序執行排序過程
for (int d = 1; d <= digit; d++) {
// 置空各個桶的數據統計
for (i = 0; i < radix; i++) {
count[i] = 0;
}
// 統計各個桶將要裝入的數據個數
for (i = begin; i <= end; i++) {
j = getDigit(list[i], d);
count[j]++;
}
// count[i]表示第i個桶的右邊界索引
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
// 將數據依次裝入桶中
// 這裏要從右向左掃描,保證排序穩定性
for (i = end; i >= begin; i--) {
j = getDigit(list[i], d); // 求出關鍵碼的第k位的數字, 例如:576的第3位是5
bucket[count[j] - 1] = list[i]; // 放入對應的桶中,count[j]-1是第j個桶的右邊界索引
count[j]--; // 對應桶的裝入數據索引減一
}
// 將已分配好的桶中數據再倒出來,此時已是對應當前位數有序的表
for (i = begin, j = 0; i <= end; i++, j++) {
list[i] = bucket[j];
}
}
}
public int[] sort(int[] list) {
radixSort(list, 0, list.length - 1, 3);
return list;
}
}

