




Lucene總的來說是:
- 一個高效的,可擴展的,全文檢索庫。
- 全部用Java實現,無須配置。
- 僅支持純文本文件的索引(Indexing)和搜索(Search)。
- 不負責由其他格式的文件抽取純文本文件,或從網絡中抓取文件的過程。
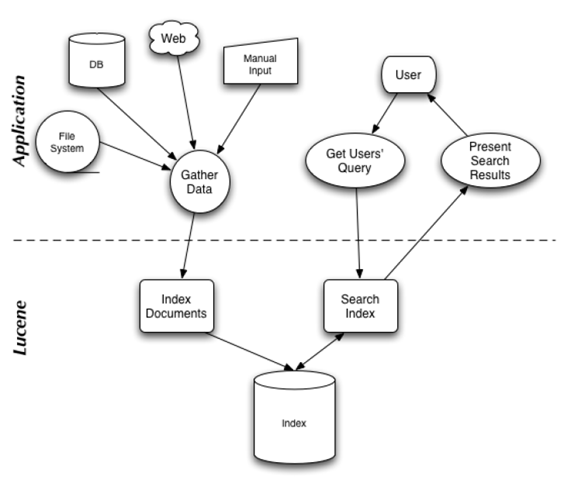
在Lucene in action中,Lucene 的構架和過程如下圖,
![[圖]Lucene的構架和過程](https://pic1.xuehuaimg.com/proxy/csdn/http://hi.csdn.net/attachment/201002/1/3634917_1265049061Uiu0.png)
說明Lucene 是有索引和搜索的兩個過程,包含索引創建,索引,搜索三個要點。
讓我們更細一些看Lucene的各組件:
![[圖]Lucene各組件](https://pic1.xuehuaimg.com/proxy/csdn/http://hi.csdn.net/attachment/201002/1/3634917_1265049062fG9p.jpg)
- 被索引的文檔用Document對象 表示。
- IndexWriter 通過函數addDocument 將文檔添加到索引中,實現創建索引的過程。
- Lucene 的索引是應用反向索引。
- 當用戶有請求時,Query 代表用戶的查詢語句。
- IndexSearcher 通過函數search 搜索Lucene Index 。
- IndexSearcher 計算term weight 和score 並且將結果返回給用戶。
- 返回給用戶的文檔集合用TopDocsCollector 表示。
那麼如何應用這些組件呢?
讓我們再詳細到對Lucene API 的調用實現索引和搜索過程。
![[圖]Lucene API的調用](https://pic1.xuehuaimg.com/proxy/csdn/http://hi.csdn.net/attachment/201002/1/3634917_12650490643655.jpg)
- 索引過程如下:
- 創建一個IndexWriter 用來寫索引文件,它有幾個參數,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用來對文檔進行詞法分析和語言處理的。
- 創建一個Document 代表我們要索引的文檔。
- 將不同的Field 加入到文檔中。我們知道,一篇文檔有多種信息,如題目,作者,修改時間,內容等。不同類型的信息用不同的Field 來表示,在本例子中,一共有兩類信息進行了索引,一個是文件路徑,一個是文件內容。其中FileReader 的SRC_FILE 就表示要索引的源文件。
- IndexWriter 調用函數addDocument 將索引寫到索引文件夾中。
- 搜索過程如下:
- IndexReader 將磁盤上的索引信息讀入到內存,INDEX_DIR 就是索引文件存放的位置。
- 創建IndexSearcher 準備進行搜索。
- 創建Analyer 用來對查詢語句進行詞法分析和語言處理。
- 創建QueryParser 用來對查詢語句進行語法分析。
- QueryParser 調用parser 進行語法分析,形成查詢語法樹,放到Query 中。
- IndexSearcher 調用search 對查詢語法樹Query 進行搜索,得到結果TopScoreDocCollector 。
以上便是Lucene API函數的簡單調用。
然而當進入Lucene的源代碼後,發現Lucene有很多包,關係錯綜複雜。
然而通過下圖,我們不難發現,Lucene的各源碼模塊,都是對普通索引和搜索過程的一種實現。
此圖是上一節介紹的全文檢索的流程對應的Lucene實現的包結構。(參照http://www.lucene.com.cn/about.htm 中文章《開放源代碼的全文檢索引擎Lucene》)
![[圖]Lucene包結構](https://pic1.xuehuaimg.com/proxy/csdn/http://hi.csdn.net/attachment/201002/1/3634917_12650490657464.jpg)
- Lucene 的analysis 模塊主要負責詞法分析及語言處理而形成Term 。
- Lucene 的index 模塊主要負責索引的創建,裏面有IndexWriter 。
- Lucene 的store 模塊主要負責索引的讀寫。
- Lucene 的QueryParser 主要負責語法分析。
- Lucene 的search 模塊主要負責對索引的搜索。
- Lucene 的similarity 模塊主要負責對相關性打分的實現。
瞭解了Lucene的整個結構,我們便可以開始Lucene的源碼之旅了。
另:
博客園此文鏈接爲:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623596.html
Javaeye此文鏈接爲:http://forfuture1978.javaeye.com/blog/546808


{kind=link}