




前言:
關於進程控制這塊的好文很多,下面轉載的這篇內容很豐富,也會舉適當的栗子,與其寫的一知半解不如參讀學習別人的優秀博文,感謝原作,本系列摘錄自:https://www.cnblogs.com/xiaomanon/p/4195327.html。如果有不妥之處,請告知,會刪除的,再次感謝o(*^▽^*)┛
進程控制(2):進程操作
進程(英語:process),是計算機中已運行程序的實體。進程爲曾經是分時系統的基本運作單位。在面向進程設計的系統(如早期的UNIX,Linux2.4及更早的版本)中,進程是程序的基本執行實體;在面向線程設計的系統(如當代多數操作系統、Linux 2.6及更新的版本)中,進程本身不是基本運行單位,而是線程的容器。程序本身只是指令、數據及其組織形式的描述,進程纔是程序(那些指令和數據)的真正運行實例。若干進程有可能與同一個程序相關係,且每個進程皆可以同步(循序)或異步(平行)的方式獨立運行。現代計算機系統可在同一段時間內以進程的形式將多個程序加載到存儲器中,並藉由時間共享(或稱時分複用),以在一個處理器上表現出同時(平行性)運行的感覺。同樣的,使用多線程技術(多線程即每一個線程都代表一個進程內的一個獨立執行上下文)的操作系統或計算機架構,同樣程序的平行線程,可在多CPU主機或網絡上真正同時運行(在不同的CPU上)。
注:以上內容來自維基百科。
本節將介紹基本的進程控制原語,包括進程的創建與退出,以及設置除進程標識符(PID)以外的其他標識符。
1 創建進程
Linux系統允許任何一個用戶進程創建一個子進程,創建成功後,子進程存在於系統之中,並且獨立於父進程。該子進程可以接受系統調度,可以得到分配的系統資源。系統也可以檢測到子進程的存在,並且賦予它與父進程同樣的權利。
Linux系統下使用fork()函數創建一個子進程,其函數原型如下:
#include <unistd.h> pid_t fork(void);
在討論fork()函數之前,有必要先明確父進程和子進程兩個概念。除了0號進程(該進程是系統自舉時由系統創建的)以外,Linux系統中的任何一個進程都是由其他進程創建的。創建新進程的進程,即調用fork()函數的進程就是父進程,而新創建的進程就是子進程。
補充(維基百科):
在UNIX裏,除了進程0(即PID=0的交換進程,Swapper Process)以外的所有進程都是由其他進程使用系統調用fork創建的,這裏調用fork創建新進程的進程即爲父進程,而相對應的爲其創建出的進程則爲子進程,因而除了進程0以外的進程都只有一個父進程,但一個進程可以有多個子進程。操作系統內核以進程標識符(Process Identifier,即PID)來識別進程。進程0是系統引導時創建的一個特殊進程,在其調用fork創建出一個子進程(即PID=1的進程1,又稱init)後,進程0就轉爲交換進程(有時也被稱爲空閒進程),而進程1(init進程)就是系統裏其他所有進程的祖先。
進程0:Linux引導中創建的第一個進程,完成加載系統後,演變爲進程調度、交換及存儲管理進程。
進程1:init 進程,由0進程創建,完成系統的初始化. 是系統中所有其它用戶進程的祖先進程。
Linux中1號進程是由0號進程來創建的,因此必須要知道的是如何創建0號進程,由於在創建進程時,程序一直運行在內核態,而進程運行在用戶態,因此創建0號進程涉及到特權級的變化,即從特權級0變到特權級3,Linux是通過模擬中斷返回來實現特權級的變化以及創建0號進程,通過將0號進程的代碼段選擇子以及程序計數器EIP直接壓入內核態堆棧,然後利用iret彙編指令中斷返回跳轉到0號進程運行。
fork()函數不需要參數,返回值是一個進程標識符(PID)。對於返回值,有以下3種情況:
(1) 對於父進程,fork()函數返回新創建的子進程的ID。
(2) 對於子進程,fork()函數返回0。由於系統的0號進程是內核進程,所以子進程的進程標識符不會是0,由此可以用來區別父進程和子進程。
(3) 如果創建出錯,則fork()函數返回-1。
fork()函數會創建一個新的進程,並從內核中爲此進程分配一個新的可用的進程標識符(PID),之後,爲這個新進程分配進程空間,並將父進程的進程空間中的內容複製到子進程的進程空間中,包括父進程的數據段和堆棧段,並且和父進程共享代碼段。這時候,系統中又多了一個進程,這個進程和父進程一模一樣,兩個進程都要接受系統的調度。
注意:由於在複製時複製了父進程的堆棧段,所以兩個進程都停留在了fork()函數中,等待返回。因此,fork()函數會返回兩次,一次是在父進程中返回,另一次是在子進程中返回,這兩次的返回值是不一樣的。
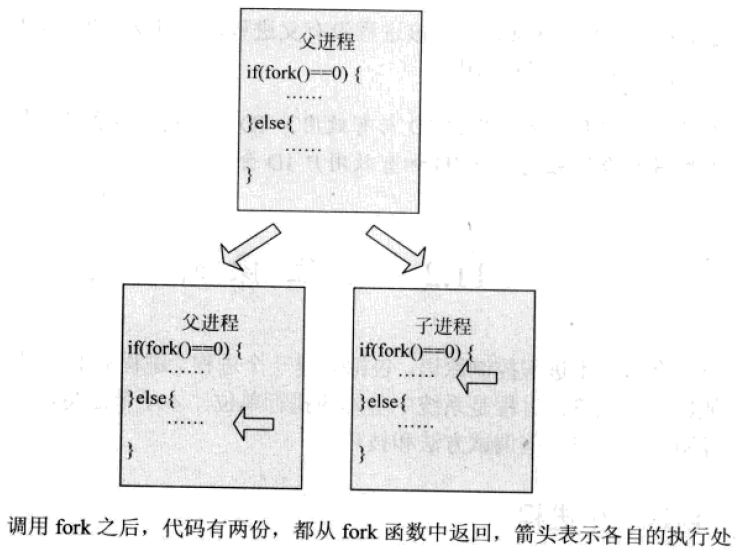
下面給出的示例程序用來創建一個子進程,該程序在父進程和子進程中分別輸出不同的內容。
//@file fork.c
//@brief create a new process
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
pid_t pid;//to store pid value
pid = fork();//create a new process
if (pid < 0)
{
//error
perror("fail to fork");
exit(-1);
}
else if (pid == 0)
{
//sub-process
printf("Sub-process, PID: %u, PPID: %u\n", getpid(), getppid());
}
else
{
//parent process
printf("Parent, PID: %u, Sub-process PID: %u\n", getpid(), pid);
}
return 0;
}
程序運行結果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./fork Parent, PID: 2598, Sub-process PID: 2599 Sub-process, PID: 2599, PPID: 2598
由於創建的新進程和父進程在系統看來是地位平等的兩個進程,所以運行機會也是一樣的,我們不能夠對其執行先後順序進行假設,先執行哪一個進程取決於系統的調度算法。如果想要指定運行的順序,則需要執行額外的操作。正因爲如此,程序在運行時並不能保證輸出順序和上面所描述的一致。
2 父子進程的共享資源
子進程完全複製了父進程的地址空間的內容,包括堆棧段和數據段的內容。子進程並沒有複製代碼段,而是和父進程共用代碼段。這樣做是存在其合理依據的,因爲子進程可能執行不同的流程,那麼就會改變數據段和堆棧段,因此需要分開存儲父子進程各自的數據段和堆棧段。但是代碼段是隻讀的,不存在被修改的問題,因此這一個段可以讓父子進程共享,以節省存儲空間,如下圖所示。
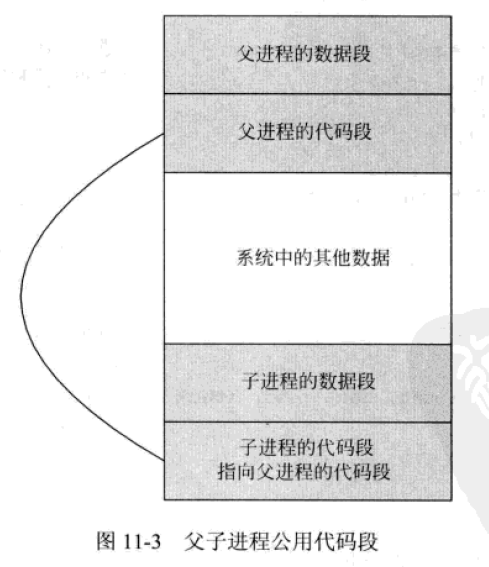
下面給出一個示例來說明這個問題。該程序定義了一個全局變量global、一個局部變量stack和一個指針heap。該指針用來指向一塊動態分配的內存區域。之後,該程序創建一個子進程,在子進程中修改global、stack和動態分配的內存中變量的值。然後在父子進程中分別打印出這些變量的值。由於父子進程的運行順序是不確定的,因此我們先讓父進程額外休眠2秒,以保證子進程先運行。
//@file fork.c
//@brief resource sharing between parent-process and sub-process
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global = 1; /*global variable, stored at data section*/
int main(void)
{
pid_t pid;//to store pid value
int stack = 1;//local variable, stored at stack
int *heap;//pointer to a heap variable
heap = (int *)malloc(sizeof(int));
*heap = 2;//set the heap value to 2
pid = fork();//create a new process
if (pid < 0)
{
//error
perror("fail to fork");
exit(-1);
}
else if (pid == 0)
{
//sub-process, change values
global++;
stack++;
(*heap)++;
//print all values
printf("In sub-process, global: %d, stack: %d, heap: %d\n", global, stack, *heap);
exit(0);
}
else
{
//parent process
sleep(2);//sleep 2 secends to make sure the sub-process runs first
printf("In parent-process, global: %d, stack: %d, heap: %d\n", global, stack, *heap);
}
return 0;
}
程序運行效果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./fork In sub-process, global: 2, stack: 2, heap: 3 In parent-process, global: 1, stack: 1, heap: 2
由於父進程休眠了2秒鐘,子進程先於父進程運行,因此會先在子進程中修改數據段和堆棧段中的內容。因此不難看出,子進程對這些數據段和堆棧段中內容的修改並不會影響到父進程的進程環境。
父進程的資源大部分被fork()函數所複製,只有小部分是子進程與父進程不同的。子進程繼承的資源情況如下表所示:

現在的Linux內核實現fork()函數時往往實現了在創建子進程時並不立即複製父進程的數據段和堆棧段,而是當子進程修改這些數據內容時複製纔會發生,內核纔會給子進程分配進程空間,將父進程的內容複製過來,然後繼續後面的操作。這樣的實現更加合理,對於一些只是爲了複製自身完成一些工作的進程來說,這樣做的效率會更高。這也是現代操作系統中一個重要的概念——“寫時複製”的一個重要體現。
3 fork出錯的情況
有兩種情況可能會導致fork()函數出錯:
(1) 系統中已經有太多的進程存在了
(2) 調用fork()函數的用戶進程太多了
一般情況下,系統都會對一個用戶所創建的進程數加以限制。如果操作系統不對其加限制,那麼惡意用戶可以利用這一缺陷攻擊系統。下面是一個利用進程的特性編寫的一個病毒程序,該程序是一個死循環,在循環中不斷調用fork()函數來創建子進程,直到系統中不能容納如此多的進程而崩潰爲止。下圖展示了這種情況:
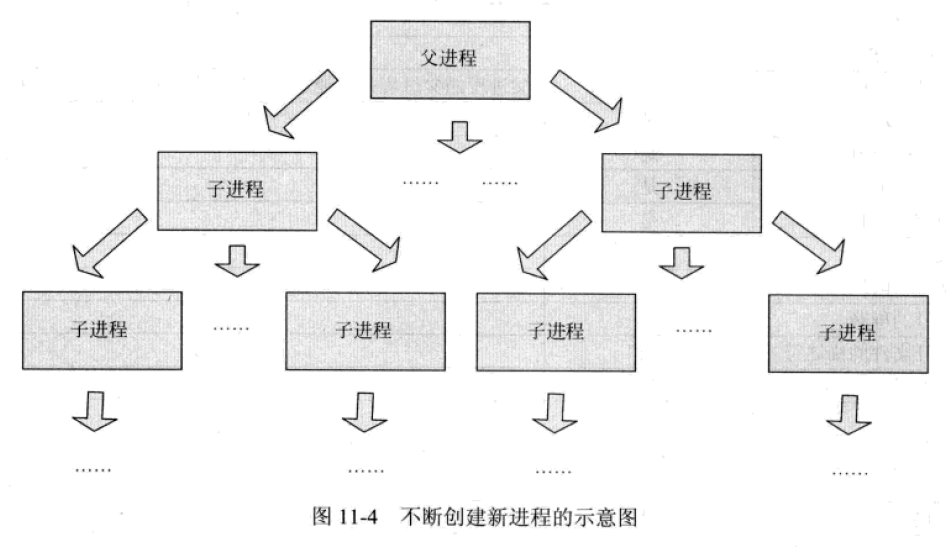
//@file fork.c
//@brief do bad thing, always create sub-process
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
while (1) fork();
return 0;
}
程序運行結果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./fork & [1] 13618 xiaomanon@xiaomanon-machine:~/Documents/c_code$ ps -u xiaomanon bash: fork: retry: Resource temporarily unavailable bash: fork: retry: Resource temporarily unavailable bash: fork: retry: Resource temporarily unavailable bash: fork: retry: Resource temporarily unavailable bash: fork: Resource temporarily unavailable
系統可能會變得很慢,以上是本人在Ubuntu 14.04LTS(虛擬機)上的測試結果,需要重啓才能解決問題。
注意:在現在的操作系統中,這種情況是不被允許的。因此,系統中限制了一個用戶創建的進程的數量,這種進攻已經不能奏效。
4 創建共享空間的子進程
進程在創建一個新的子進程之後,子進程的地址空間完全和父進程分開。父子進程是兩個獨立的進程,接受系統調度和分配系統資源的機會均等,因此父進程和子進程更像是一對兄弟。如果父子進程共用父進程的地址空間,則子進程就不是獨立於父進程的。
Linux環境下提供了一個與fork()函數類似的函數,也可以用來創建一個子進程,只不過新進程與父進程共用父進程的地址空間,其函數原型如下:
#include <unistd.h> pid_t vfork(void);
vfork()和fork()函數的區別有以下兩點:
(1) vfork()函數產生的子進程和父進程完全共享地址空間,包括代碼段、數據段和堆棧段,子進程對這些共享資源所做的修改,可以影響到父進程。由此可知,vfork()函數與其說是產生了一個進程,還不如說是產生了一個線程。
(2) vfork()函數產生的子進程一定比父進程先運行,也就是說父進程調用了vfork()函數後會等待子進程運行後再運行。
下面的示例程序用來驗證以上兩點。在子進程中,我們先讓其休眠2秒以釋放CPU控制權,在前面的fork()示例代碼中我們已經知道這樣會導致其他線程先運行,也就是說如果休眠後父進程先運行的話,則第(2)點則爲假;否則爲真。第(2)點爲真,則會先執行子進程,那麼全局變量便會被修改,如果第(1)點爲真,那麼後執行的父進程也會輸出與子進程相同的內容。代碼如下:
//@file vfork.c
//@brief vfork() usage
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global = 1;
int main(void)
{
pid_t pid;
int stack = 1;
int *heap;
heap = (int *)malloc(sizeof(int));
*heap = 1;
pid = vfork();
if (pid < 0)
{
perror("fail to vfork");
exit(-1);
}
else if (pid == 0)
{
//sub-process, change values
sleep(2);//release cpu controlling
global = 999;
stack = 888;
*heap = 777;
//print all values
printf("In sub-process, global: %d, stack: %d, heap: %d\n", global, stack, *heap);
exit(0);
}
else
{
//parent-process
printf("In parent-process, global: %d, stack: %d, heap: %d\n", global, stack, *heap);
}
return 0;
}
程序運行效果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./vfork
In sub-process, global: 999, stack: 888, heap: 777 In parent-process, global: 999, stack: 888, heap: 777
注意:如果不在子進程中添加exit()函數退出的話,會導致執行父進程時出現段錯誤,原因目前還沒弄明白。
5 在函數內部調用vfork
在使用vfork()函數時應該注意不要在任何函數中調用vfork()函數。下面的示例是在一個非main函數中調用了vfork()函數。該程序定義了一個函數f1(),該函數內部調用了vfork()函數。之後,又定義了一個函數f2(),這個函數沒有實際的意義,只是用來覆蓋函數f1()調用時的棧幀。main函數中先調用f1()函數,接着調用f2()函數。
//@file vfork.c
//@brief vfork() usage
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int f1(void)
{
vfork();
return 0;
}
int f2(int a, int b)
{
return a+b;
}
int main(void)
{
int c;
f1();
c = f2(1,2);
printf("%d\n",c);
return 0;
}
程序運行效果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./vfork 3 Segmentation fault (core dumped)
通過上面的程序運行結果可以看出,一個進程運行正常,打印出了預期結果,而另一個進程似乎出了問題,發生了段錯誤。出現這種情況的原因可以用下圖來分析一下:

左邊這張圖說明調用vfork()之後產生了一個子進程,並且和父進程共享堆棧段,兩個進程都要從f1()函數返回。由於子進程先於父進程運行,所以子進程先從f1()函數中返回,並且調用f2()函數,其棧幀覆蓋了原來f1()函數的棧幀。當子進程運行結束,父進程開始運行時,就出現了右圖的情景,父進程需要從f1()函數返回,但是f1()函數的棧幀已經被f2()函數的所替代,因此就會出現父進程返回出錯,發生段錯誤的情況。
由此可知,使用vfork()函數之後,子進程對父進程的影響是巨大的,其同步措施勢在必行。
6 退出進程
當一個進程需要退出時,需要調用退出函數。Linux環境下使用exit()函數退出進程,其函數原型如下:
#include <stdlib.h> void exit(int status);
exit()函數的參數表示進程的退出狀態,這個狀態的值是一個整型,保存在全局變量$?中,在shell中可以通過“echo $?”來檢查退出狀態值。
注意:這個退出函數會深入內核註銷掉進程的內核數據結構,並且釋放掉進程的資源。
7 exit函數與內核函數的關係
exit函數是一個標準的庫函數,其內部封裝了Linux系統調用_exit()函數。兩者的主要區別在於exit()函數會在用戶空間做一些善後工作,例如清理用戶的I/O緩衝區,將其內容寫入 磁盤文件等,之後才進入內核釋放用戶進程的地址空間;而_exit()函數直接進入內核釋放用戶進程的地址空間,所有用戶空間的緩衝區內容都將丟失。
8 設置進程所有者
每個進程都有兩個用戶ID,實際用戶ID和有效用戶ID。通常這兩個ID的值是相等的,其取值爲進程所有者的用戶ID。但是,在有些場合需要改變進程的有效用戶ID。Linux環境下使用setuid()函數改變一個進程的實際用戶ID和有效用戶ID,其函數原型如下:
#include <unistd.h> int setuid(uid_t uid);
setuid()函數的參數表示改變後的新用戶ID,如果成功修改當前進程的實際用戶ID和有效用戶ID,函數返回值爲0;如果失敗,則返回-1。只有兩種用戶可以修改進程的實際用戶ID和有效用戶ID:
(1) 根用戶:根用戶可以將進程的實際用戶ID和有效用戶ID更換。
(2) 其他用戶:其該用戶的用戶ID等於進程的實際用戶ID或者保存的用戶ID。
也就是說,用戶可以將自己的有效用戶ID改回去。這種情況多出現於下面的情況:一個進程需要具有某種權限,所以將其有效用戶ID設置爲具有這種權限的用戶ID,當進程不需要這種權限時,進程還原自己之前的有效用戶ID,使自己的權限復原。下面給出一個修改的示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
uid_t uid, euid;
uid = getuid();
euid = geteuid();
printf("Before, uid: %d, euid: %d\n", uid, euid);
if (setuid(1024) == -1)
{
perror("fail to set uid");
exit(-1);
}
uid = getuid();
euid = geteuid();
printf("After, uid: %d, euid: %d\n", uid, euid);
return 0;
}
程序運行效果如下:
xiaomanon@xiaomanon-machine:~/Documents/c_code$ ./setuid Before, uid: 1000, euid: 1000 fail to set uid: Operation not permitted xiaomanon@xiaomanon-machine:~/Documents/c_code$ sudo ./setuid
Before, uid: 0, euid: 0 After, uid: 1024, euid: 1024
說明:爲了保證程序正確運行,用戶應當具有該用戶權限。以上示例中,當前用戶就沒有修改uid的權限,而使用超級用戶權限時,能夠成功修改。那麼,如何讓當前用戶擁有修改用戶ID的權限呢?
Linux環境下還提供了只修改有效用戶ID的函數seteuid(),以及修改修改實際組ID和有效組ID的函數,其參數和返回值含義與setuid()的類似,函數原型如下所示:
#include <unistd.h> int seteuid(uid_t uid); int setgid(gid_t gid); int setegid(gid_t gid);
9 參考文獻
[1] 吳嶽,Linux C程序設計大全,清華大學出版社
[2] IBM, UNIX進程揭祕, developerWorks

