




聲明:文本非原創,只是翻譯,原文鏈接如下:
https://simonschreibt.de/gat/renderhell-book2/
Render Hell – Book II

 本文是 “Render Hell” 系列文章的第二篇。
本文是 “Render Hell” 系列文章的第二篇。
Pipeline 詳解
關於本篇文章,我收到的大多數積極反饋是:非常漂亮的演示說明,但是你的 Pipeline 已經是6年前的了!最初我一直不明白這句話是什麼意思,直到 Christoph Kubisch 加入到我的 Render Hell 創作中來,我才明白這句話的含義。他是一名就職於 NVIDIA 的技術開發工程師,無論我有什麼樣的問題,他都會爲我一一解答。請相信我,我的問題實在是太多了!😃
我們的講解都是基於 NVIDIA 架構的,因爲 Christoph 就在 NVIDIA 工作。因此我希望你們不要把這篇文章當作是 NVIDIA 的軟文,我倆都有解說事物原理的激情,而且我真的很高興能有個人來幫助我理解那些技術知識。
請注意,我們省略並簡化了一些細節內容。
關於 Pipeline 有兩點需要做如下說明,雖然這兩點在 Book I 中並沒有明顯的錯誤描述,但是可能還是不夠清晰:
1. 並不是所有的事情都是由 “微小” 的 GPU Core 來完成的!
2. 可以允許多條 Pipeline 同時運行!
接下來我將詳細說明這兩點,希望你能喜歡!
1. 並不是所有的事情都由 “微小” 的 GPU Core 來完成的
在之前的 Pipeline 示例中,看上去每個 Pipeline 階段都是由 GPU Core 來完成的 —— 其實並非如此!實際上大多數的任務都不是由它們完成的。在上一篇 “1. 拷貝數據到系統內存” 這一小節中,你已經看到,要想把數據給到 Core 還需要一些必要的組件。那麼 Core 到底做了哪些事情呢?
我們一起來看看下面這個傢伙吧:

一個 Core 可以接收命令和數據,然後通過計算浮點(FP)或整型(INT)數據來執行命令。因此你可以這麼認爲:Core 可以計算像素和頂點(也可能是其它的計算,比如物理計算,但這裏還是讓我們把重點放在圖形渲染上面吧)。
其它那些重要的事情,例如分配渲染任務、曲面細分、剔除和準備像素着色器的片元、深度測試以及將像素寫入 FrameBuffer,這些都不是由 Core 來完成的,而是由 GPU 內部專門的、不可編程的硬件模塊來完成的。
好了,瞭解了這一點之後,讓我們繼續討論下一個重點,一個我必須要澄清的重點:
2. 允許多條 Pipeline 同時運行
首先,我會用一個簡短的例子來告訴你這個小標題的含義,如果你看了之後還是無法滿足你的求知慾,我會再給你一個更詳細的講解。但在那之前,還是讓我們先快速回顧一下:
假如我們只有一個 GPU Core,我們能用它來計算什麼?

回答正確:什麼也計算不了!因爲 GPU Core 是需要別人分配任務給它的。而負責分配任務的人就是 Streaming Multiprocessor(SM,流處理器簇),它可以用來處理一個着色器上的頂點流/像素流。OK,有了 SM 和 Core,我們就可以計算了,但是每次只能計算一個頂點/像素:

當然了,如果我們增加 Core 的數量,就可以在同一時刻計算多個頂點/像素了,但前提是這些頂點和像素都必須屬於同一個着色器!

以上這些在我上一篇介紹 Pipeline 的時候其實就已經講過了!但是現在讓我們來點更有意思的:如果我們再添加一個 SM,讓它們各自管理一半的 Core,將會是什麼樣的結果呢?

這樣我們既可以並行的計算頂點/像素,又可以同時處理2個着色器了!這意味着,我們可以同時運行2個不同的像素着色器,或者同一時刻運行一個頂點着色器和一個像素着色器!
以上這些簡單的演示只是想讓你感受一下,不同的硬件模塊之間都是並行工作的,而真實的 Pipeline 其實會比我上一篇描述的更加靈活多變。
還沒滿足你的好奇心?那就和我一起深入到更多的細節裏去吧!
3. 深入探究 Pipeline 階段
3.1 簡介
首先:爲什麼我們需要一個靈活的、可並行的 Pipeline?原因就是,你無法預料你會碰到多大的負載。尤其是曲面細分,可能會比上一幀突然多出10萬個多邊形出來。因此,你需要一個靈活的 Pipeline 來應對各種不同的負載情況。
別擔心!
當你看到下面兩幅圖時,千萬不要害怕(就像我當初在維基百科上見到文字間的公式一樣)!沒錯,這東西並不那麼好理解,甚至複雜的圖表只能顯示出程序猿需要知道什麼,並且隱藏了大量的“真正”複雜的東西。我把這兩幅圖放在這裏,僅僅只是爲了讓你大致明白這個玩意兒究竟有多複雜 😃。

圖片來源:http://www.legitreviews.com/
下圖截取自 Christoph Kubisch 的文章《Life of a triangle》,它展示了 GPU 在結構化圖形系統中的部分工作原理。

圖片來源:Christoph Kubisch 的文章《Life of a triangle》
現在,我希望你能對 Pipeline 的複雜性有個大致的印象,並且能夠意識到接下來的講解是有多麼簡單。那就讓我們一起來看看整個 Pipeline 的詳細流程吧!
3.2 App 階段
一切從這裏開始,應用程序或遊戲 App 告訴驅動程序它們想要渲染一些東西。

3.3 Driver 階段
驅動程序接收來自 App 的命令,然後將它們放入 Command Buffer 中(在上一篇已經介紹過了)。不久之後(或者是程序猿強制執行),這些命令就被送進 GPU 裏去了。
注意: 驅動程序可能會造成性能瓶頸,詳見 Book III 中 “1. 大量的 Draw Call” 一節。

3.4 讀取命令
現在我們來到顯卡內部,Host 接口會從 Command Buffer 中讀取命令,以便後續執行它們。

3.5 獲取數據(Data Fetch)
發送給 GPU 的命令,有的自身攜帶數據,有的本身則爲一條拷貝數據的指令。GPU 通常有一個專用引擎,用來處理從 RAM 到 VRAM 的數據拷貝,反向傳輸也是一樣的。這些數據可以是用來填充頂點緩衝區、紋理或其它着色器參數。我們看到的一幀畫面內容通常是從發送一些攝像機矩陣參數開始的。

重點
- 雖然我這裏採用幾何圖形來表示數據,但實際上我們只是在討論頂點列表(頂點緩衝區)。很長一段時間,渲染過程並不關心最終的模型。相反,大多數情況下,渲染過程只不過是在處理單個頂點或像素。
- 只有當 VRAM 中找不到所需的紋理時,才需要執行拷貝動作。
- 如果頂點數據經常需要被訪問,那麼它們可以像紋理那樣一直呆在 VRAM 中,而不用每次執行 Draw Call 時都去拷貝它們。
- 如果頂點數據經常發生變化,那麼它們可以一直呆在 RAM 裏 (而非 VRAM),這樣 GPU 可以直接將它們從 RAM 讀取到 Cache 中。
現在所有的原材料都準備就緒了,Gigathread 引擎便開始發揮它的作用了。它爲每個頂點/像素創建一個線程,並將它們封裝成一個包,NVIDIA 把這個包叫做:線程塊(Thread Block)。Gigathread 引擎還會爲曲面細分後的頂點、幾何着色器(後面會講到)創建額外的線程。最後,線程塊被分發到各個 SM 手裏。

3.6 獲取頂點(Vertex Fetch)
SM 其實是各種不同硬件單元的集合,其中一個就是幾何處理引擎(Polymorph Engine)。爲了簡單起見,我把他們描繪成單獨的個體 😃 。幾何處理引擎找到所需的頂點數據並將其複製到 Cache 中,以便 Core 能夠更快地訪問它們。在 Book I 中已經解釋過爲什麼需要將數據複製到緩存中了,這裏就不再贅述。

3.7 執行着色程序
SM 的主要目的是執行 App 開發人員編寫的程序代碼,也被稱爲 着色器(Shader)。着色器的種類有很多,但每種都可以在任何一個 SM 中運行,並且它們都遵循相同的執行邏輯。
接下來 SM 會將它從 Gigathread 引擎那收到的大線程塊,拆分成許多更小的堆,每個堆包含32個線程,這樣的堆也被稱爲:Warp。一個 Maxwell 架構的 SM 最多可以容納64個 Warp。在我的示例中,以及 Maxwell 架構的 GPU 中,有32個專用的 Core 來處理32個線程。

然後一個 Warp 就被拿去工作了。此時,硬件應將所有需要的數據加載到寄存器中,以便 Core 可以用它們來工作。我這裏對演示做了一點簡化:Maxwell 的流處理器(SP)一般有4個 Warp 調度器,每個調度器可以處理一個 Warp,並管理 SM 上剩餘的 Warp。

真正的工作現在纔開始!GPU Core 本身看不到所有的 Shader 代碼,它們只能同一時刻看見1條指令。它們處理完當前指令後,SM 會給他們發送下一條指令。所有的 Core 都執行相同的指令,卻作用於不同的數據(頂點/像素)。不可能存在說一部分 Core 在執行指令 A 的時候,另一部分 Core 卻在執行指令 B。這種執行機制被稱爲 鎖步(lock-step)。

如果你的 Shader 代碼中有 IF 語句,鎖步機制將變得尤爲重要。

IF 語句可以讓一部分 Core 執行左邊的代碼,而另一部分 Core 則執行右邊的代碼,但絕不允許這兩部分 Core 同時執行(這點前面已經說過了)。首先,左側代碼在被執行的時候,負責執行右側代碼的 Core 則處於“休眠狀態”。等左側的 Core 執行結束後,右側的 Core 纔開始執行。Kayvon 則在視頻 “What about conditional execution?” 中(43:58 時間點)解釋了這一行爲。
譯者注:GPU 中的 IF 條件不同於 CPU。在 CPU 中,IF 條件只會執行一條分支;而在 GPU 中,IF 條件很有可能兩條分支都執行。可以參考知乎上的回答《Shader中的條件分支能否節省shader的性能?》。
在我給的例子中,16個像素/頂點是可以滿足要求的,但是也很有可能會出現這樣的 IF 條件:只有1個像素/頂點需要被計算,而其它31個 Core 都會被屏蔽掉。這種情況也同樣會發生在循環語句中,如果有一個 Core 在循環中呆太久,就會導致所有其它的 Core 都處於空閒狀態。這種現象也被稱爲 Divergent Thread(分歧線程),應該儘量避免這種情況發生。理想情況下,我們希望 Warp 中的所有線程都滿足 IF 條件的同一側分支,這樣我們就能完全跳過另一側的分支了。

但是明明同一時刻只有幾個 Core 可以工作,爲什麼還要讓 SM 容納 64 個 Warp 呢?這是因爲有時候爲了等待某些數據就緒,你不得不停下來。比如說,我們需要通過法線紋理貼圖來計算法線光照,即使該法線紋理已經在 Cache 中了,訪問該資源仍然會有所耗時,而如果它不在 Cache 中,那就更加耗時了。用專業術語講就是 Memory Stall(內存延遲),關於這點 Kayvon 給出了詳盡的解釋。與其什麼事情也不做,不如將當前的 Warp 換成其它已經準備就緒的 Warp 繼續執行。

上面的講解有點簡單了。現代的 GPU 架構不再像當初那種,只允許 Streaming Processor (SP) 在一定時間內只處理一個 Warp 。看看 這張 基於 Maxwell 架構的 SP(SMM)圖片:一個 SM 可以訪問四個 Warp 調度器,每個調度器控制32個 Core,這使得它能夠完全並行的處理4個 Warp。多線程工作狀態的記錄本是獨立保存的,並以 SM 可以並行運行的線程數來表示,就像上面提到的那樣。
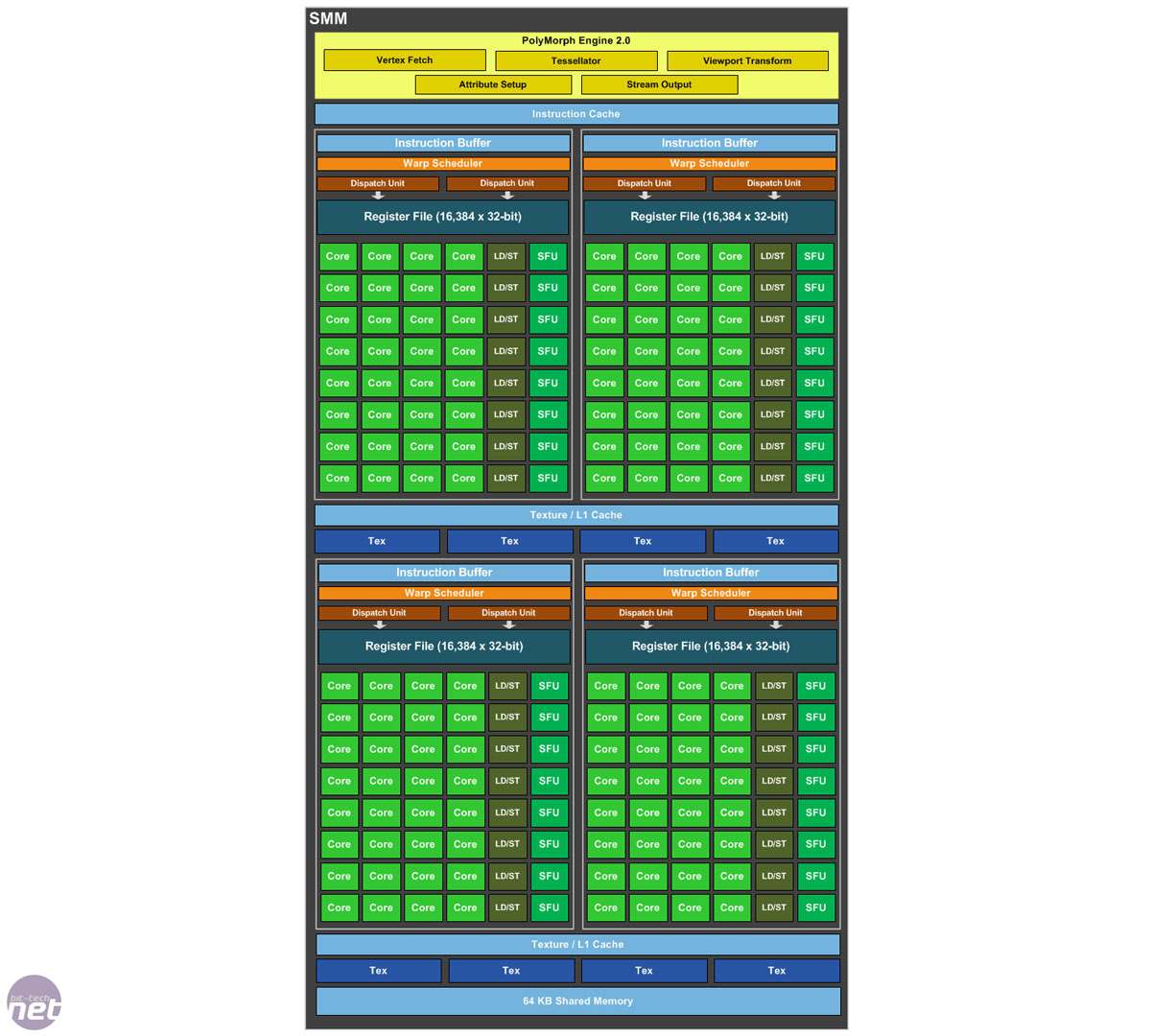{kind=link}
正如 Guohui.Wang 所指出的,不僅僅是在等待內存時需要切換調度器,其它情況也需要切換調度器:
因爲在 Maxwell 中可以同時運行4個以上的 Warp,每個 Warp 調度器可以在一個時鐘週期內對 Warp 發起兩次指令傳輸。在這種情況下,每個時鐘週期內有多達4個 Warp 可以執行它們新的指令(假設至少有4個 Warp 已經準備就緒)。然而,我們同樣也有指令級的並行處理。也就是說,當有4個 Warp 正在執行指令的時候(通常需要持續10-20個時鐘週期),下一批4個 Warp 可以在下一個時鐘週期到來時接受新的指令。因此,如果資源可用,則可能會有4個以上的 Warp 同時運行。實際上,在 GTC2013 大會上的一個 CUDA 優化視頻裏講到,在常用 case 中推薦使用30個以上的有效 Warp,這樣才能確保 Pipeline 的滿載利用率。因此,您可能需要修改一下此處的描述,以表明會有多個(超過4個)Warp 同時運行,以防別人誤認爲4個調度器只能容納4個並行的 Warp。
—— Guohui Wang

但是我們的線程到底做了什麼事情呢?舉個栗子,頂點着色器!
3.8 頂點着色器(Vertex Shader)
頂點着色器用於處理單個頂點,並根據程序猿的需要對其進行修改。不同於常用的軟件(如郵件程序),你運行一個程序,並交給它一堆需要處理的數據(如處理所有的郵件),當你運行一個頂點着色程序來處理每個頂點時,它會在 SM 管理的每個線程中運行。
我們的頂點着色器會根據你的需要,對頂點及其相關參數(如位置、顏色、UV座標)進行轉換:

個別 Pipeline 流程只會在用到曲面細分技術的時候纔會被執行,如果你的遊戲程序不會用到曲面細分技術,你可以選擇跳過接下來的 3.9 ~ 3.12 章節。
3.9 面片裝配(Patch Assembly)
直到這裏,我們看到的都是單個的頂點。當然,它們都是按照特定的順序由程序猿發出的,但我們並沒有把它們當作一個組,而是當作一個個相互獨立的點來處理。以下幾個小節討論的步驟僅在使用 曲面細分着色器 時纔會被執行。第一步是根據各個頂點創建 面片(Patch),這樣就可以對它們進行細分並添加幾何細節了。具體需要多少個頂點來組裝成一個面片是由程序猿來決定的,最大的個數是,猜猜看,32個。
在 OpenGL 中,這個階段被稱爲 Patch/Primitive Assembly,而在 DirectX 中,只有 Patch Assembly(Primitive Assembly 後面會講到)。有關 Patch/Primitive Assembly 更多詳細內容,請參考[a57]。

3.10 外殼着色器(Hull Shader)
外殼着色器使用頂點來計算細分因子,這些頂點全部來源於前面創建的單個面片,而計算得出的細分因子大小,則取決於模型到攝像機的距離。由於硬件只能細分三種 基本形狀(四邊形、三角形或一系列直線),因此 shader code 中還會指明當前細分器應該使用哪種基本形狀。最終的結果就是,我們得到了不只一個細分因子,而且它們是爲形狀的每一個外側和一個特殊的“內側”計算的。爲了後續能夠創建更爲重要的幾何圖形,外殼着色器還要爲專門處理位置信息的域着色器計算輸入值。

3.11 曲面細分(Tessellation)
現在我們清楚了要使用哪種基本形狀來進行細分,以及要細分成多少塊 —— 幾何處理引擎(Polymorph Engine)使用這些信息來開展真正的細分工作。最終我們得到了許多新的頂點,這些頂點再次被送回給 Gigathread 引擎,在 GPU 上進行分發,並最終交由域着色器處理。有關着色器階段的更多詳細信息,請參見 [a55] 和 [a79]。

在這裏你可以找到關於 三角形細分(Triangle Tesselation)和 四邊形細分(Quad Tesselation)的詳細文章。
您可能會問,爲什麼不直接將幾何圖形的所有細節都放入模型中呢?這是因爲有兩個原因:首先,您可能還記得,與純粹的計算相比,訪問內存是有多慢。因此,與其讀取所有這些額外的頂點以及它們全部的屬性(位置、法線、UV座標等),還不如使用較少的數據(面角頂點 + 替代邏輯或紋理,支持 Mipmap、壓縮 …)來生成它們。其次,通過曲面細分技術,你可以根據攝像機的距離來調節某些細節,所以你會非常靈活。否則,我們可能會計算大量的頂點,而這些頂點所在的三角形甚至最終都不可見(因爲太小或不在顯示區域內)。
3.12 域着色器(Domain Shader)
現在到了計算細分頂點的最終位置的時候了,如果程序猿想使用置換貼圖(displacement map),它就會在這裏生效。域着色器的輸入來自外殼着色器的輸出(例如面片頂點),以及來自細分的重心座標。有了重心座標和麪片頂點,你就可以計算新的頂點位置,然後對它應用置換貼圖了。與頂點着色器類似,域着色器計算出的數據會被傳遞到下一個着色器階段,該階段要麼是幾何着色器(Geometry Shader)(如果被激活的話),要麼是片元着色器(Fragment Shader)。

3.13 圖元裝配(Primitive Assembly)
來到幾何 Pipeline 的末端,我們收集頂點,用於裝配我們的圖元:三角形、直線或點。這些頂點要麼來自頂點着色器,要麼來自域着色器(如果曲面細分被激活的話)。
我們所處的模式(三角形、直線或點)是由發起本次 Draw Call 的應用程序來決定的。通常,我們只需要將圖元傳遞給最終的處理單元並進行光柵化就可以了,但還有一個可選的階段也會用到這些信息,它就是幾何着色器。

3.14 幾何着色器(Geometry Shader)
幾何着色器作用於最終的圖元。與外殼着色器類似,它獲取圖元的頂點作爲輸入。它可以修改這些頂點,甚至生成一些新的頂點。它還可以改變最終的圖元模式。例如,將一個點轉換爲兩個三角形,或立方體的三個可見邊。
但是,我們並不提倡創建大量新的頂點或三角形,細分的工作最好還是留給細分着色器去處理。幾何着色器存在的意義是相當特殊的,因爲它是圖元光柵化之前的最後一個準備環節,比如它在當前的 體素化技術(voxelization techniques)中起着關鍵作用。
在這裏你可以找到如何編寫和使用幾何着色器的優秀示例,而在這裏還可以找到關於 OpenGL Pipeline 很好的介紹。

3.15 視口變換(Viewport Transform)和裁剪(Clipping)
直到這裏,程序猿所有的操作使用的似乎都是二次空間(我想這樣做更簡單/更快),但現在到了該把畫面內容適配到實際顯示分辨率(或遊戲呈現的窗口)的時候了。有關此操作的更多信息,請參見 這篇文章 的 “Viewport Transform/Screen Mapping” 小節。

同樣的,如果三角形超出了鏡頭的某個安全邊界(保護帶),那麼它也會被裁剪,我們將這種行爲稱作 保護帶裁剪(Guard Band Clipping),你可以在 這裏 和 這裏 找到更多相關信息。之所以要裁剪,是因爲光柵化執行單元只能處理其工作區域內的三角形:

3.16 三角形之旅(Triangles Journey)
其實它在 Pipeline 中並不是一個獨立的步驟,但我發現它其實蠻有意思的,所以我就給它單獨設立了章節。
現在我們有了頂點確切的位置、陰影等信息,在我們開始“繪製”這些三角形之前,必須得先找出屏幕上哪些像素處於三角形區域內,這個工作則是由 光柵器 來完成的。這裏需要強調一下,如果這個三角形非常大,那麼會有多個可用的光柵器在同一個三角形上同時工作。否則,也就意味着只有一個光柵器處於工作狀態,而其他的光柵器則處於空閒狀態。
因此,每一個光柵器都負責屏幕上特定的幾個區域,如果一個三角形經確認屬於某個特定區域(通過三角形的邊界框(bounding box)來檢測),那麼它就會被髮送給負責該區域的光柵器去處理。

3.17 光柵化(Rasterizing)
光柵器收到他要處理的三角形,首先快速檢查該三角形是否面向鏡頭。如果不是,那就直接扔掉(背面剔除,Backface Culling)。如果三角形是“有效的”,則光柵器會計算連接頂點的邊(edge setup),並查看哪些像素四邊形(2×2像素)在三角形內,以此來創建 預像素 / 片元。

如果你對光柵化和微三角形(micro-triangles)真的很感興趣,你一定要看看這個 PPT,還有 這一篇 不錯的介紹。
光柵化引擎總是以2×2像素爲單位進行工作,這會使渲染過程效率低下,詳情參見 Book III。
創建完預像素/片段之後,還要檢查它們是否真的可見(或是否被其它已渲染的物體擋住):
光柵器所產生的像素會被送到 Z-cull (Z軸剔除)單元。Z-cull 單元拿到一個像素塊,並將該塊中像素的深度與 FrameBuffer 中已有像素的深度進行比較,完全位於 FrameBuffer 像素後面的像素塊將從 Pipeline 中剔除掉,從而消除進一步像素着色工作的需要。
—— NVIDIA GF100 白皮書
3.18 像素着色器(Pixel Shader)
生成預像素/片元后,我們就可以對它們進行“填充”了。對於每個預像素/片元,都會生成一個新的線程,並再次分發給所有可用的 Core(就像處理所有頂點那樣)。
“同樣,我們對32個像素線程進行批處理,更準確的說是8個2×2像素塊,它始終是像素着色器工作的最小單位。”

當 Core 完成他們的工作後,會將結果寫回到原來的寄存器中,並將寄存器的結果寫入緩存以便進行最後一步:光柵輸出(ROP)。
3.19 光柵輸出(Raster Output)
最後一步是由光柵輸出單元來完成的,該單元會將最終的像素數據(剛從像素着色器那得到的)從二級緩存搬運到 VRAM 中的 FrameBuffer 裏。以 GF100 爲例,它有48個這樣的 ROP 單元,我是根據它們彼此非常靠近來演示數據流的(從二級緩存到 VRAM):
“[…] 二級緩存和 ROP 組是緊密耦合在一起的 […]”
—— NVIDIA GF100 白皮書
除了搬運像素數據,ROP 還負責 像素混合(Pixel Blending)、抗鋸齒(Anti Aliasing) 信息彙報以及 “原子操作(Atomic Operation)”。

多麼奇妙的一次旅行啊!我花了很長一段時間才把所有的信息彙集到一起,希望這篇文章能夠對你有所幫助。
本篇到此結束。