




臺灣大學李宏毅老師的機器學習課程是一份非常好的ML/DL入門資料,李宏毅老師將課程錄像上傳到了YouTube,地址:NTUEE ML 2016 。
這篇文章是學習本課程第1-3課所做的筆記和自己的理解。
Lecture 1: Regression - Case Study
machine learning 有三個步驟,step 1 是選擇 a set of function, 即選擇一個 model,step 2 是評價goodness of function,step 3 是選出 best function。
regression 的例子有道瓊斯指數預測、自動駕駛中的方向盤角度預測,以及推薦系統中購買可能性的預測。課程中的例子是預測寶可夢進化後的CP值。
一隻寶可夢可由5個參數表示,x=(x_cp, x_s, x_hp, x_w, x_h)。我們在選擇 model 的時候先選擇linear model。接下來評價goodness of function ,它類似於函數的函數,我們輸入一個函數,輸出的是how bad it is,這就需要定義一個loss function。在所選的model中,隨着參數的不同,有着無數個function(即,model確定之後,function是由參數所決定的),每個function都有其loss,選擇best function即是選擇loss最小的function(參數),求解最優參數的方法可以是gradient descent。
gradient descent 的步驟是:先選擇參數的初始值,再向損失函數對參數的負梯度方向迭代更新,learning rate控制步子大小、學習速度。梯度方向是損失函數等高線的法線方向。
gradient descent 可能使參數停在損失函數的局部最小值、導數爲0的點、或者導數極小的點處。線性迴歸中不必擔心局部最小值的問題,損失函數是凸的。
在得到best function之後,我們真正在意的是它在testing data上的表現。選擇不同的model,會得到不同 的best function,它們在testing data 上有不同表現。複雜模型的model space涵蓋了簡單模型的model space,因此在training data上的錯誤率更小,但並不意味着在testing data 上錯誤率更小。模型太複雜會出現overfitting。
如果我們收集更多寶可夢進化前後的CP值會發現,進化後的CP值不只依賴於進化前的CP值,還有其它的隱藏因素(比如寶可夢所屬的物種)。同時考慮進化前CP值x_cp和物種x_s,之前的模型要修改爲
if x_s = pidgey: y = b_1 + w_1 * x_cp
if x_s = weedle: y = b_2 + w_2 * x_cp
if x_s = caterpie: y = b_3 + w_3 * x_cp
if x_s = eevee: y = b_4 + w_4 * x_cp
這仍是一個線性模型,因爲它可以寫作
y =
b_1 * δ(x_s = pidgey) + w_1 * δ(x_s = pidgey) * x_cp +
b_2 * δ(x_s = weedle) + w_2 * δ(x_s = weedle) * x_cp +
b_3 * δ(x_s = caterpie) + w_3 * δ(x_s = caterpie) * x_cp +
b_4 * δ(x_s = eevee) + w_4 * δ(x_s = eevee) * x_cp
上式中的粗體項都是linear model y = b + Σw_i * x_i 中的feature x_i。
這個模型在測試集上有更好的表現。如果同時考慮寶可夢的其它屬性,選一個很複雜的模型,結果會overfitting。
對線性模型來講,希望選出的best function 能 smooth一些,也就是權重係數小一些,因爲這樣的話,在測試數據受噪聲影響時,預測值所受的影響會更小。
所以在損失函數中加一個正則項 λΣ(w_i)^2。
越大的λ,對training error考慮得越少。
我們希望函數smooth,但也不能太smooth。
調整λ,選擇使testing error最小的λ。
Lecture 2: Where does the error come from?
error有兩種來源,分別是bias和variance,診斷error的來源,可以挑選適當的方法improve model。
以進化前的寶可夢爲輸入,以進化後的真實CP值爲輸出,真實的函數記爲f^” role=”presentation” style=”position: relative;”>f^f^)
從訓練數據,我們找到 f∗” role=”presentation” style=”position: relative;”> f∗ f∗的一個估計。

簡單模型,variance小。複雜模型,variance大。(簡單模型更少受訓練數據影響。複雜模型會盡力去擬合訓練數據的變化。)
bias代表f¯” role=”presentation” style=”position: relative;”>f¯f¯ 的距離。簡單模型,bias大。複雜模型,bias小。
simple model的model space較小,可能沒有包含target。
在underfitting的情況下,error大部分來自bias。
在overfitting的情況下,error大部分來自variance。
如果model連訓練樣本都fit得不好,那就是underfitting, bias大。
如果model可以fit訓練樣本,但是testing error大,那就是overfitting, variance大。
在bias大的情況下,需要重新設計model,比如增加更多的feature,或者讓model更complex。而此時more data是沒有幫助的。
在variance大的情況下,需要more data,或者regularization。more data指的是,之前100個f∗” role=”presentation” style=”position: relative;”>f∗f∗。
在選擇模型時,要考慮兩種error的折中,使total error最小。
不應該這樣做:

因爲這樣做,在public testing set上的error rate,並不代表在private testing set上的error rate。
應該採用cross validation的方法!
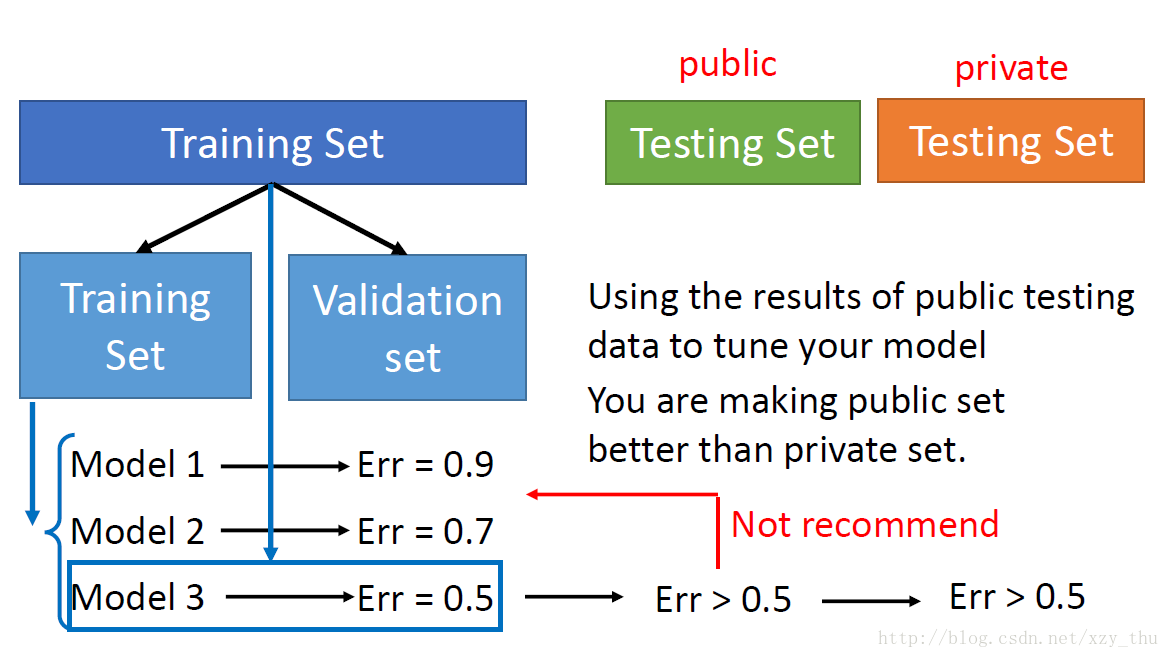
將training set分成training set 和 validation set,在training set上訓練model 1-3,選擇在validation set 上error rate最小的model。
如果嫌training set中data少的話,可以在確定model後在全部training data上再train一遍該model。
這樣做,在public testing set上的error rate纔會代表在private testing set上的error rate。
不能用public testing set去調整model。
N折交叉驗證

將training set分成N折,每次只有一折作爲validation set,其它折作爲training set,在各model中選擇N次訓練得到的N個validation error rate的均值最小的model。
Lecture 3: Gradient Descent

Tip 1: Tuning your learning rates
在用梯度下降時要畫出loss隨更新參數次數的曲線(如下圖),看一下前幾次更新參數時曲線的走法如何。

調整學習率的一個思路是:每幾個epoch之後就降低學習率(一開始離目標遠,所以學習率大些,後來離目標近,學習率就小些),並且不同的參數有不同的學習率。
Adagrad


如何理解Adagrad的參數更新式子呢?以一元二次函數爲例,參數更新的best step是

在參數更新式子中,gt” role=”presentation” style=”position: relative;”>gtgt 代表first derivative,分母中的根號項反映了second derivative(用first derivative去估計second derivative)。
Tip 2: Stochastic Gradient Descent
SGD讓訓練過程更快。普通GD是在看到所有樣本(訓練數據)之後,計算出損失L,再更新參數。而SGD是每看到一個樣本就計算出一個損失,然後就更新一次參數。
Tip 3: Feature Scaling
如果不同參數的取值範圍大小不同,那麼loss函數等高線方向(負梯度方向,參數更新方向)不指向loss最低點。feature scaling讓不同參數的取值範圍是相同的區間,這樣loss函數等高線是一系列共圓心的正圓,更新參數更容易。
feature scaling的做法是,把input feature的每個維度都標準化(減去該維度特徵的均值,除以該維度的標準差)。
Gradient Descent的理論推導(以兩個參數爲例)


約等式的成立需要the red circle is small enough這個條件,如果η” role=”presentation” style=”position: relative;”>ηη 沒有設好,這個約等式可能不成立,從而loss不會越來越小。
也可以考慮Taylor Series中的二階項,要多很多運算,一般不划算。
李宏毅機器學習課程筆記
李宏毅機器學習課程筆記1:Regression、Error、Gradient Descent
李宏毅機器學習課程筆記2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅機器學習課程筆記3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅機器學習課程筆記4:CNN、Why Deep、Semi-supervised
李宏毅機器學習課程筆記5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅機器學習課程筆記6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅機器學習課程筆記7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅機器學習課程筆記8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅機器學習課程筆記9:Recurrent Neural Network
李宏毅機器學習課程筆記10:Ensemble、Deep Reinforcement Learning