




序列化:把變量從內存中變爲可儲存或者可傳輸的過程叫做序列化,序列化之後就可將已序列化過的數據寫入磁盤,或者通過網絡傳輸到別的機器上。
python中使用pickle進行序列化
1.dumps()
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
dump()函數內置了很多參數,這些參數的用法一一介紹。
(1)dump(obj)
obj參數是必填項,就是需要被序列化的參數。
例如:
>>> s=[1,'zaq',['python','learing'],{'time':30,'asf':'y'}]
>>> print(s)
[1, 'zaq', ['python', 'learing'], {'time': 30, 'asf': 'y'}]
>>> import json
>>> print(pickle.dumps(s))
b'\x80\x03]q\x00(K\x01X\x03\x00\x00\x00zaqq\x01]q\x02(X\x06\x00\x00\x00pythonq\x03X\x07\x00\x00\x00learingq\x04e}q\x05(X\x04\x00\x00\x00timeq\x06K\x1eX\x03\x00\x00\x00asfq\x07X\x01\x00\x00\x00yq\x08ue.'這裏就是將原來的列表s,變成了一個可用於存儲和傳輸的bytes。
(2)dump(obj,f)
後將序列後的s放到文件中去(用於存儲):
f=open('dump.txt','wb')#因爲序列化後的s是一個字節,所以要用wb的方式寫入
pickle.dump(s,f)
f.close()#使用完文件一定要讓它關上
```
打開dump文件:
```
€]q (KX zaqq]q(X pythonqX learingqe}q(X timeqKX asfqX yque.€]q (KX zaqq]q(X pythonqX learingqe}q(X timeqKX asfqX yque.€]q (KX zaqq]q(X pythonqX learingqe}q(X timeqKX asfqX yque.€]q (KX zaqq]q(X pythonqX learingqe}q(X timeqKX asfqX yque.
```
顯示的的是python 保存的對象內部信息...反正看不懂
## json-python
爲了更加方便的傳輸和保存,一般數據都是用json 表示。因爲json 傳輸的是一個字符串,更快更方便。
對於json和python之間的數據對象對比如下:
- python-json

- json-python
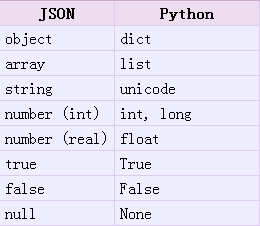
例如:
import json
s=[1,’zaq’,[‘python’,’learing’],{‘time’:(1,30),’asf’:’y’}]
print(json.dumps(s))
[1, “zaq”, [“python”, “learing”], {“time”: [1, 30], “asf”: “y”}]
print(type(json.dumps(s)))
其中元組就變成了列表,但是序列化之後的s就是字符串
將json轉化爲python:`json,loads()`
語法:`json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])`
例子:import json
txt_json=’[“a”,1,”s”,2]’
json.loads(txt_json)
[‘a’, 1, ‘s’, 2]
(3)dump(obj, fp, *, skipkeys=False)
skipkeys可以設置被序列化的字典中的key 不用是str類型。
例如:
>>> s={'name':"zaq",'time':30,('who',30):'y'}
>>> json.dumps(s) #不使用skipkeys參數,就會報錯
Traceback (most recent call last):
File "<input>", line 1, in <module>
>>> json.dumps(s,skipkeys=True)
'{"time": 30, "name": "zaq"}'(4)dump(obj,indent=None)
indent用來加縮進值
>>> d1=json.dumps(s,skipkeys=True,indent=4)
>>> print(d1)
{
"time": 30,
"name": "zaq"
}但是看到('who',30):'y'這一部分沒有輸出,估計是skipkeys=True的原因。
(5)dump(obj, sort_keys=False)
sore_keys是保證字典輸出按照原有順序來的依靠。
>>> s={'time': 30, 'who': 'y', 'name': 'zaq'}
>>> d1=json.dumps(s,sort_keys=True)
>>> print(d1)
{"name": "zaq", "time": 30, "who": "y"}2.反序列化load()
之前往文件裏面寫了一點東西,現在把它拿出來
>>> f=open('dump.txt','rb')
>>> d=pickle.load(f)
>>> f.close()
>>> d
[1, 'zaq', ['python', 'learing'], {'time': 30, 'asf': 'y'}]