




1.什麼是注意力機制?
注意力機制模仿了生物觀察行爲的內部過程,即一種將內部經驗和外部感覺對齊從而增加部分區域的觀察精細度的機制。例如人的視覺在處理一張圖片時,會通過快速掃描全局圖像,獲得需要重點關注的目標區域,也就是注意力焦點。然後對這一區域投入更多的注意力資源,以獲得更多所需要關注的目標的細節信息,並抑制其它無用信息。
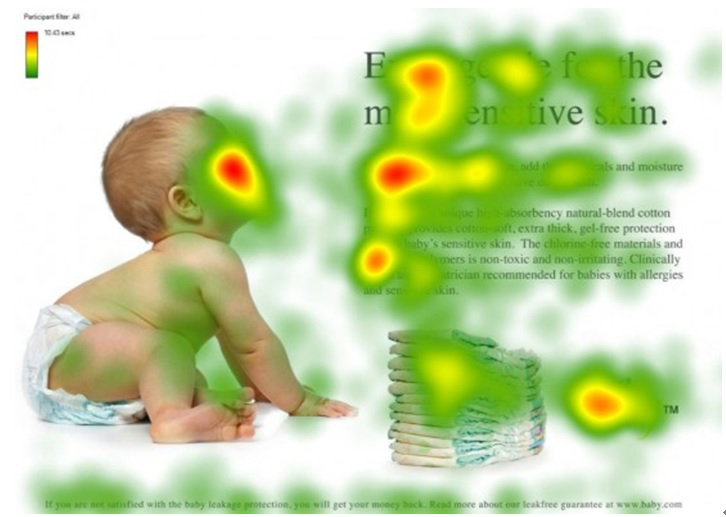
圖片來源:深度學習中的注意力機制,其中紅色區域表示更關注的區域。
2|0Encoder-Decoder 框架
目前大多數的注意力模型都是依附在 Encoder-Decoder 框架下,但並不是只能運用在該模型中,注意力機制作爲一種思想可以和多種模型進行結合,其本身不依賴於任何一種框架。Encoder-Decoder 框架是深度學習中非常常見的一個模型框架,例如在 Image Caption 的應用中 Encoder-Decoder 就是 CNN-RNN 的編碼 - 解碼框架;在神經網絡機器翻譯中 Encoder-Decoder 往往就是 LSTM-LSTM 的編碼 - 解碼框架,在機器翻譯中也被叫做 Sequence to Sequence learning 。
所謂編碼,就是將輸入的序列編碼成一個固定長度的向量;解碼,就是將之前生成的固定向量再解碼成輸出序列。這裏的輸入序列和輸出序列正是機器翻譯的結果和輸出。
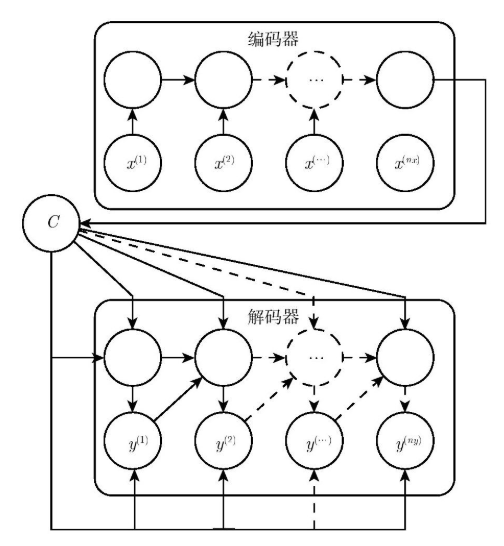
爲了說明 Attention 機制的作用,以 Encoder-Decoder 框架下的機器翻譯的應用爲例,該框架的抽象表示如下圖:

2|1侷限性
Encoder-Decoder 框架雖然應用廣泛,但是其存在的侷限性也比較大。其最大的侷限性就是 Encoder 和 Decoder 之間只通過一個固定長度的語義向量 CC 來唯一聯繫。也就是說,Encoder 必須要將輸入的整個序列的信息都壓縮進一個固定長度的向量中,存在兩個弊端:一是語義向量 C 可能無法完全表示整個序列的信息;二是先輸入到網絡的內容攜帶的信息會被後輸入的信息覆蓋掉,輸入的序列越長,該現象就越嚴重。這兩個弊端使得 Decoder 在解碼時一開始就無法獲得輸入序列最夠多的信息,因此導致解碼的精確度不夠準確。
3|0Attention 機制
在上述的模型中,Encoder-Decoder 框架將輸入 XX 都編碼轉化爲語義表示 CC,這就導致翻譯出來的序列的每一個字都是同權地考慮了輸入中的所有的詞。例如輸入的英文句子是:Tom chase Jerry,目標的翻譯結果是:湯姆追逐傑瑞。在未考慮注意力機制的模型當中,模型認爲 湯姆 這個詞的翻譯受到 Tom,chase 和 Jerry 這三個詞的同權重的影響。但是實際上顯然不應該是這樣處理的,湯姆 這個詞應該受到輸入的 Tom 這個詞的影響最大,而其它輸入的詞的影響則應該是非常小的。顯然,在未考慮注意力機制的 Encoder-Decoder 模型中,這種不同輸入的重要程度並沒有體現處理,一般稱這樣的模型爲 分心模型。
而帶有 Attention 機制的 Encoder-Decoder 模型則是要從序列中學習到每一個元素的重要程度,然後按重要程度將元素合併。因此,注意力機制可以看作是 Encoder 和 Decoder 之間的接口,它向 Decoder 提供來自每個 Encoder 隱藏狀態的信息。通過該設置,模型能夠選擇性地關注輸入序列的有用部分,從而學習它們之間的“對齊”。這就表明,在 Encoder 將輸入的序列元素進行編碼時,得到的不在是一個固定的語義編碼 C ,而是存在多個語義編碼,且不同的語義編碼由不同的序列元素以不同的權重參數組合而成。一個簡單地體現 Attention 機制運行的示意圖如下:
定義:對齊
對齊是指將原文的片段與其對應的譯文片段進行匹配。
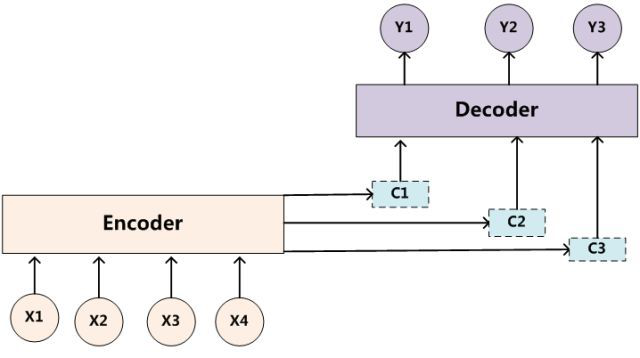


其中,hihi 表示 Encoder 的轉換函數,F(hj,Hi)F(hj,Hi) 表示預測與目標的匹配打分函數。將以上過程串聯起來,則注意力模型的結構如下圖所示:

4. Attention原理:
詳見https://www.cnblogs.com/ydcode/p/11038064.html