




1、zookeeper概念介紹
在介紹ZooKeeper之前,先來介紹一下分佈式協調技術,所謂分佈式協調技術主要是用來解決分佈式環境當中多個進程之間的同步控制,讓他們有序的去訪問某種共享資源,防止造成資源競爭(腦裂)的後果。
這裏首先介紹下什麼是分佈式系統,所謂分佈式系統就是在不同地域分佈的多個服務器,共同組成的一個應用系統來爲用戶提供服務,在分佈式系統中最重要的是進程的調度,這裏假設有一個分佈在三個地域的服務器組成的一個應用系統,在第一臺機器上掛載了一個資源,然後這三個地域分佈的應用進程都要競爭這個資源,但我們又不希望多個進程同時進行訪問,這個時候就需要一個協調器,來讓它們有序的來訪問這個資源。這個協調器就是分佈式系統中經常提到的那個“鎖”,例如”進程1“在使用該資源的時候,會先去獲得這把鎖,”進程1“獲得鎖以後會對該資源保持獨佔,此時其它進程就無法訪問該資源,“進程1”;在用完該資源以後會將該鎖釋放掉,以便讓其它進程來獲得鎖。由此可見,通過這個“鎖”機制,就可以保證分佈式系統中多個進程能夠有序的訪問該共享資源。這裏把這個分佈式環境下的這個“鎖”叫作分佈式鎖。這個分佈式鎖就是分佈式協調技術實現的核心內容。
目前,在分佈式協調技術方面做得比較好的有Google的Chubby,還有Apache的ZooKeeper,它們都是分佈式鎖的實現者。ZooKeeper所提供鎖服務在分佈式領域久經考驗,它的可靠性、可用性都是經過理論和實踐驗證的。
ZooKeeper是一種爲分佈式應用所設計的高可用、高性能的開源協調服務,它提供了一項基本服務:分佈式鎖服務,同時,也提供了數據的維護和管理機制,如:統一命名服務、狀態同步服務、集羣管理、分佈式消息隊列、分佈式應用配置項的管理等等。
2、zookeeper應用舉例
1)什麼是單點故障問題呢?
所謂單點故障,就是在一個主從的分佈式系統中,主節點負責任務調度分發,從節點負責任務的處理,而當主節點發生故障時,整個應用系統也就癱瘓了,那麼這種故障就稱爲單點故障。那我們的解決方法就是通過對集羣master角色的選取,來解決分佈式系統單點故障的問題。
2)傳統的方式是怎麼解決單點故障的?以及有哪些缺點呢?
傳統的方式是採用一個備用節點,這個備用節點定期向主節點發送ping包,主節點收到ping包以後向備用節點發送回復Ack信息,當備用節點收到回覆的時候就會認爲當前主節點運行正常,讓它繼續提供服務。而當主節點故障時,備用節點就無法收到回覆信息了,此時,備用節點就認爲主節點宕機,然後接替它成爲新的主節點繼續提供服務。
這種傳統解決單點故障的方法,雖然在一定程度上解決了問題,但是有一個隱患,就是網絡問題,可能會存在這樣一種情況:主節點並沒有出現故障,只是在回覆ack響應的時候網絡發生了故障,這樣備用節點就無法收到回覆,那麼它就會認爲主節點出現了故障,接着,備用節點將接管主節點的服務,併成爲新的主節點,此時,分佈式系統中就出現了兩個主節點(雙Master節點)的情況,雙Master節點的出現,會導致分佈式系統的服務發生混亂。這樣的話,整個分佈式系統將變得不可用。爲了防止出現這種情況,就需要引入ZooKeeper來解決這種問題。
3)zookeeper的工作原理是什麼?
下面通過三種情形來講解:
(1)master啓動
在分佈式系統中引入Zookeeper以後,就可以配置多個主節點,這裏以配置兩個主節點爲例,假定它們是 主節點A 和 主節點B,當兩個主節點都啓動後,它們都會向ZooKeeper中註冊節點信息。我們假設 主節點A 鎖註冊的節點信息是 master00001 , 主節點B 註冊的節點信息是 master00002 ,註冊完以後會進行選舉,選舉有多種算法,這裏以編號最小作爲選舉算法,那麼編號最小的節點將在選舉中獲勝並獲得鎖成爲主節點,也就是 主節點A 將會獲得鎖成爲主節點,然後 主節點B 將被阻塞成爲一個備用節點。這樣,通過這種方式Zookeeper就完成了對兩個Master進程的調度。完成了主、備節點的分配和協作。
(2)master故障
如果 主節點A 發生了故障,這時候它在ZooKeeper所註冊的節點信息會被自動刪除,而ZooKeeper會自動感知節點的變化,發現 主節點A 故障後,會再次發出選舉,這時候 主節點B 將在選舉中獲勝,替代 主節點A 成爲新的主節點,這樣就完成了主、被節點的重新選舉。
(3)master恢復
如果主節點恢復了,它會再次向ZooKeeper註冊自身的節點信息,只不過這時候它註冊的節點信息將會變成 master00003 ,而不是原來的信息。ZooKeeper會感知節點的變化再次發動選舉,這時候 主節點B 在選舉中會再次獲勝繼續擔任 主節點 , 主節點A 會擔任備用節點。
zookeeper就是通過這樣的協調、調度機制如此反覆的對集羣進行管理和狀態同步的。
4)zookeeper集羣架構
zookeeper一般是通過集羣架構來提供服務的,下圖是zookeeper的基本架構圖。
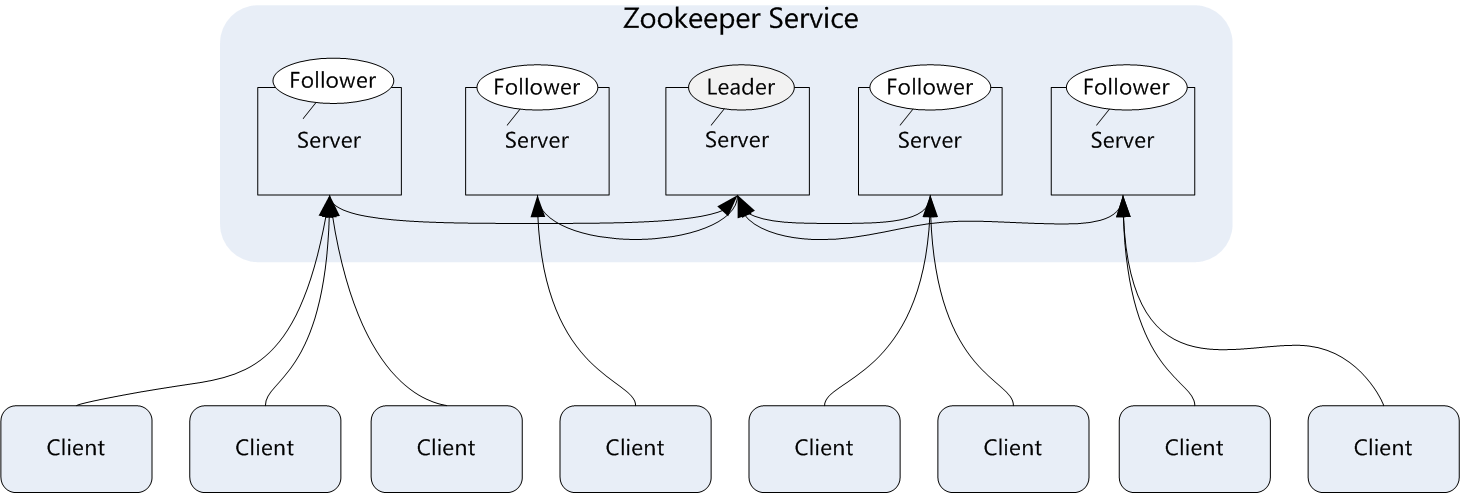
zookeeper集羣主要角色有server和client,其中server又分爲leader、follower和observer三個三絕,每個角色的含義如下:
Leader:領導者角色,主要負責投票的發起和決議,以及更新系統狀態。 follower:跟隨着角色,用於接收客戶端的請求並返回結果給客戶端,在選舉過程中參與投票。 observer:觀察者角色,用戶接收客戶端的請求,並將寫請求轉發給leader,同時同步leader狀態,但是不參與投票。Observer目的是擴展系統,提高伸縮性。 client:客戶端角色,用於向zookeeper發起請求。
Zookeeper集羣中每個Server在內存中存儲了一份數據,在Zookeeper啓動時,將從實例中選舉一個Server作爲leader,Leader負責處理數據更新等操作,當且僅當大多數Server在內存中成功修改數據,才認爲數據修改成功。
Zookeeper寫的流程爲:客戶端Client首先和一個Server或者Observe通信,發起寫請求,然後Server將寫請求轉發給Leader,Leader再將寫請求轉發給其它Server,其它Server在接收到寫請求後寫入數據並響應Leader,Leader在接收到大多數寫成功迴應後,認爲數據寫成功,最後響應Client,完成一次寫操作過程。
3、Kafka基礎與入門
1)kafka基本概念
Kafka是一種高吞吐量的分佈式發佈/訂閱消息系統,這是官方對kafka的定義,這樣說起來,可能不太好理解,這裏簡單舉個例子:現在是個大數據時代,各種商業、社交、搜索、瀏覽都會產生大量的數據。那麼如何快速收集這些數據,如何實時的分析這些數據,是一個必須要解決的問題,同時,這也形成了一個業務需求模型,即生產者生產(produce)各種數據,消費者(consume)消費(分析、處理)這些數據。那麼面對這些需求,如何高效、穩定的完成數據的生產和消費呢?這就需要在生產者與消費者之間,建立一個通信的橋樑,這個橋樑就是消息系統。從微觀層面來說,這種業務需求也可理解爲不同的系統之間如何傳遞消息。
kafka是Apache組織下的一個開源系統,它的最大的特性就是可以實時的處理大量數據以滿足各種需求場景:比如基於hadoop平臺的數據分析、低時延的實時系統、storm/spark流式處理引擎等。kafka現在它已被多家大型公司作爲多種類型的數據管道和消息系統使用。
2)kafka角色術語
kafka的一些核心概念和角色
Broker:Kafka集羣包含一個或多個服務器,每個服務器被稱爲broker。 Topic:每條發佈到Kafka集羣的消息都有一個分類,這個類別被稱爲Topic(主題)。 Producer:指消息的生產者,負責發佈消息到kafka broker。 Consumer:指消息的消費者,從kafka broker拉取數據,並消費這些已發佈的消息。 Partition:Partition是物理上的概念,每個Topic包含一個或多個Partition,每個partition都是一個有序的隊列。partition中的每條消息都會被分配一個有序的id(offset)。 Consumer Group:消費者組,可以給每個Consumer指定消費組,若不指定消費者組,則屬於默認的group。 Message:消息,通信的基本單位,每個producer可以向一個topic發佈一些消息。
3)kafka拓撲架構
一個典型的Kafka集羣包含若干Producer,若干broker、若干Consumer Group,以及一個Zookeeper集羣。Kafka通過Zookeeper管理集羣配置,選舉leader,以及在Consumer Group發生變化時進行rebalance。Producer使用push模式將消息發佈到broker,Consumer使用pull模式從broker訂閱並消費消息。典型架構如下圖所示:
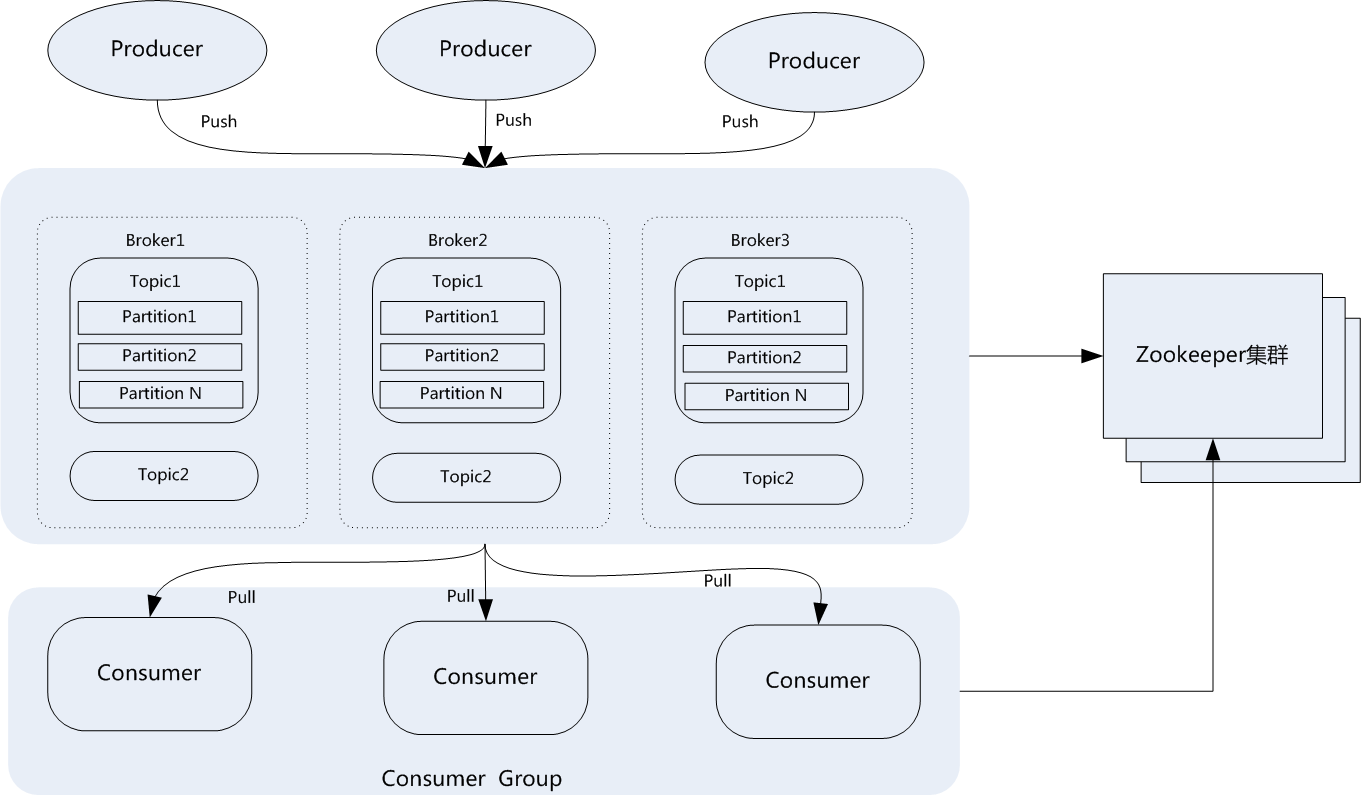
從圖中可以看出,典型的消息系統有生產者(Producer),存儲系統(broker)和消費者(Consumer)組成,Kafka作爲分佈式的消息系統支持多個生產者和多個消費者,生產者可以將消息分佈到集羣中不同節點的不同Partition上,消費者也可以消費集羣中多個節點上的多個Partition。在寫消息時允許多個生產者寫到同一個Partition中,但是讀消息時一個Partition只允許被一個消費組中的一個消費者所消費,而一個消費者可以消費多個Partition。也就是說同一個消費組下消費者對Partition是互斥的,而不同消費組之間是共享的
kafka支持消息持久化存儲,持久化數據保存在kafka的日誌文件中,在生產者生產消息後,kafka不會直接把消息傳遞給消費者,而是先要在broker中進行存儲,爲了減少磁盤寫入的次數,broker會將消息暫時緩存起來,當消息的個數或尺寸、大小達到一定閥值時,再統一寫到磁盤上,這樣不但提高了kafka的執行效率,也減少了磁盤IO調用次數。
kafka中每條消息寫到partition中,是順序寫入磁盤的,這個很重要,因爲在機械盤中如果是隨機寫入的話,效率將是很低的,但是如果是順序寫入,那麼效率卻是非常高,這種順序寫入磁盤機制是kafka高吞吐率的一個很重要的保證。
4)Topic和partition
Kafka中的topic是以partition的形式存放的,每一個topic都可以設置它的partition數量,Partition的數量決定了組成topic的log的數量。推薦partition的數量一定要大於同時運行的consumer的數量。另外,建議partition的數量要小於等於集羣broker的數量,這樣消息數據就可以均勻的分佈在各個broker中
那麼,Topic爲什麼要設置多個Partition呢,這是因爲kafka是基於文件存儲的,通過配置多個partition可以將消息內容分散存儲到多個broker上,這樣可以避免文件尺寸達到單機磁盤的上限。同時,將一個topic切分成任意多個partitions,可以保證消息存儲、消息消費的效率,因爲越多的partitions可以容納更多的consumer,可有效提升Kafka的吞吐率。因此,將Topic切分成多個partitions的好處是可以將大量的消息分成多批數據同時寫到不同節點上,將寫請求分擔負載到各個集羣節點。
在存儲結構上,每個partition在物理上對應一個文件夾,該文件夾下存儲這個partition的所有消息和索引文件。partiton命名規則爲topic名稱+序號,第一個partiton序號從0開始,序號最大值爲partitions數量減1。
在每個partition(文件夾)中有多個大小相等的segment(段)數據文件,每個segment的大小是相同的,但是每條消息的大小可能不相同,因此segment<br/>數據文件中消息數量不一定相等。segment數據文件有兩個部分組成,分別爲index file和data file,此兩個文件是一一對應,成對出現,後綴”.index“和“.log”分別表示爲segment索引文件和數據文件。
5)Producer生產機制
Producer是消息和數據的生產者,它發送消息到broker時,會根據Paritition機制選擇將其存儲到哪一個Partition。如果Partition機制設置的合理,所有消息都可以均勻分佈到不同的Partition裏,這樣就實現了數據的負載均衡。如果一個Topic對應一個文件,那這個文件所在的機器I/O將會成爲這個Topic的性能瓶頸,而有了Partition後,不同的消息可以並行寫入不同broker的不同Partition裏,極大的提高了吞吐率。
6)Consumer消費機制
Kafka發佈消息通常有兩種模式:隊列模式(queuing)和發佈/訂閱模式(publish-subscribe)。在隊列模式下,只有一個消費組,而這個消費組有多個消費者,一條消息只能被這個消費組中的一個消費者所消費;而在發佈/訂閱模式下,可有多個消費組,每個消費組只有一個消費者,同一條消息可被多個消費組消費。
Kafka中的Producer和consumer採用的是push、pull的模式,即producer向 broker進行push消息,comsumer從bork進行pull消息,push和pull對於消息的生產和消費是異步進行的。pull模式的一個好處是consumer可自主控制消費消息的速率,同時consumer還可以自己控制消費消息的方式是批量的從broker拉取數據還是逐條消費數據。