




CAS在一種“分佈式ID生成方案”上的應用。
所謂“分佈式ID生成方案”,是指在分佈式環境下,生成全局唯一ID的方法。
可以利用DB自增鍵(auto inc id)來生成全局唯一ID,插入一條記錄,生成一個ID:

這個方案利用了數據庫的單點特性,其優點爲:
- 無需寫額外代碼
- 全局唯一
- 絕對遞增
- 遞增ID的步長確定
其不足爲:
- 需要做數據庫HA,保證生成ID的高可用
- 數據庫中記錄數較多
- 生成ID的性能,取決於數據庫插入性能
優化方案爲:
- 利用雙主保證高可用
- 定期刪除數據
- 增加一層服務,採用批量生成的方式降低數據庫的寫壓力,提升整體性能
增加服務後,DB中只需保存當前最大的ID即可,在服務啓動初始化的過程中,首先拉取當前的max-id:
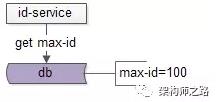
- select max_id from T;
然後批量獲取一批ID,放到id-servcie內存裏,並將max-id寫回數據庫:
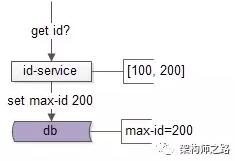
- update T set max_id=200;
這樣,id-service就拿到了[100, 200]這一批ID,上游在獲取ID時,不用每次都插入數據庫,而是分配完100個ID後,再修改max-id的值,這樣分配ID的整體性能就增加了100倍。
這個方案的優點:
- 數據庫只保存一條記錄
- 性能極大增強
其不足爲:
- 如果id-service重啓,可能內存會有一段已經申請的ID沒有分配出去,導致ID空洞,當然,這不是一個嚴重的問題
- 服務沒有做HA,無法保證高可用
優化方案爲:
- 冗餘服務,做集羣保證高可用
冗餘了服務後,多個服務在啓動過程中,進行ID批量申請時,可能由於併發導致數據不一致:
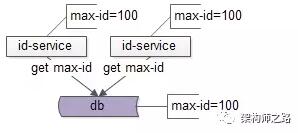
- select max_id from T;
如上圖所示,兩個id-service在啓動的過程中,同時拿到了max-id爲100。
兩個id-service同時對數據庫的max-id進行寫回:
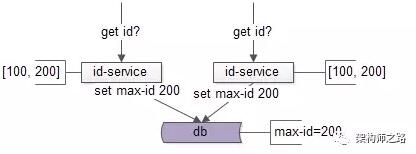
- update T set max_id=200;
寫回max-id成功後,這兩個id-service都以爲自己拿到了[100,200]這一批ID,導致集羣會生成重複的ID。
問題發生的原因,是併發寫回時,沒有對max-id的初始值進行比對:
- id-service1寫回max-id=200成功的條件是,max-id必須等於100
- id-service2寫回max-id=200成功的條件是,max-id也必須等於100
- id-service1寫回時,max-id是100,理應寫回成功
- id-service2寫回時,max-id已經被改成了200,不應該寫回成功
只要實施CAS樂觀鎖,在寫回時對max-id的初始條件進行比對,就能避免數據的不一致,寫回SQL由:
- update T set max_id=200;
升級爲:
- update T set max_id=200 where max_id=100;
這樣,id-service2寫回時,就會失敗:
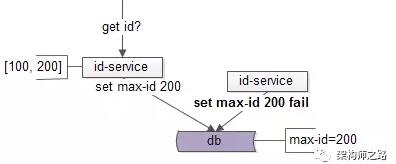
失敗後,id-service2要再次查詢max-id:
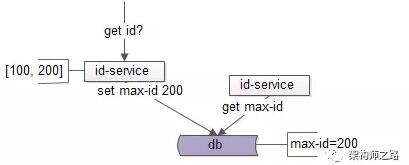
此時max-id已經變爲200,於是id-service2獲取到了[200, 300]這一批ID,並將max-id=300寫回:
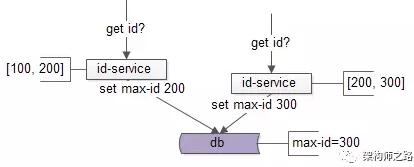
- update t set max_id=300 where max_id=200;
寫回成功。
這種方案的好處是:
- 能夠通過水平擴展的方式,達到分佈式ID生成服務的無限性能
- 使用CAS簡潔的保證不會生成重複的ID
其不足爲:
- 由於有多個service,生成的ID 不是絕對遞增的,而是趨勢遞增的
【本文爲51CTO專欄作者“58沈劍”原創稿件】